Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
2404.03622
0
0
💬
Abstract
Large language models (LLMs) have exhibited impressive performance in language comprehension and various reasoning tasks. However, their abilities in spatial reasoning, a crucial aspect of human cognition, remain relatively unexplored. Human possess a remarkable ability to create mental images of unseen objects and actions through a process known as the Mind's Eye, enabling the imagination of the unseen world. Inspired by this cognitive capacity, we propose Visualization-of-Thought (VoT) prompting. VoT aims to elicit spatial reasoning of LLMs by visualizing their reasoning traces, thereby guiding subsequent reasoning steps. We employed VoT for multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. Experimental results demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs. Notably, VoT outperformed existing multimodal large language models (MLLMs) in these tasks. While VoT works surprisingly well on LLMs, the ability to generate mental images to facilitate spatial reasoning resembles the mind's eye process, suggesting its potential viability in MLLMs.
Create account to get full access
Overview
- Explores the ability of large language models (LLMs) to reason about spatial concepts and tasks
- Proposes a novel "Visualization-of-Thought" (VoT) prompting technique to enhance the spatial reasoning capabilities of LLMs
- Evaluates VoT on multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds
- Demonstrates that VoT significantly improves the spatial reasoning performance of LLMs, outperforming existing multimodal large language models (MLLMs)
Plain English Explanation
Large language models (LLMs) have shown impressive abilities in understanding and processing language, but their skills in spatial reasoning – the capacity to mentally visualize and manipulate objects and their relationships – have been less explored. Humans possess a remarkable "mind's eye" ability to imagine unseen objects and actions, which enables us to reason about the spatial world.
Inspired by this human cognitive capacity, the researchers developed a new technique called "Visualization-of-Thought" (VoT) prompting. VoT aims to help LLMs reason about spatial tasks by guiding them to visualize the steps of their own reasoning process. The researchers then tested VoT on several spatial reasoning challenges, including navigating through 2D environments and arranging visual elements on a grid.
The results showed that VoT significantly improved the spatial reasoning abilities of LLMs, outperforming even multimodal language models that combine text and visual information. This suggests that the ability to generate mental images, akin to the human "mind's eye," can be a valuable tool for enhancing the spatial reasoning capabilities of AI systems.
Technical Explanation
The researchers investigated the spatial reasoning abilities of large language models (LLMs), which have demonstrated impressive performance in language comprehension and various reasoning tasks. However, the researchers noted that the spatial reasoning capabilities of LLMs remain relatively unexplored.
To address this, the researchers proposed a novel technique called "Visualization-of-Thought" (VoT) prompting. VoT aims to elicit spatial reasoning in LLMs by guiding them to visualize the steps of their own reasoning process, thereby facilitating subsequent reasoning steps.
The researchers evaluated VoT on a variety of multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. The experiments demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs, outperforming existing multimodal large language models (MLLMs) in these tasks.
The researchers noted that the ability to generate "mental images" to facilitate spatial reasoning, as demonstrated by VoT, resembles the human "mind's eye" process. This suggests that the capacity to visualize and manipulate spatial concepts may be a valuable component in the development of more capable multimodal AI systems.
Critical Analysis
The paper provides a compelling exploration of spatial reasoning in large language models, highlighting the potential benefits of incorporating visualization-based techniques to enhance their capabilities. However, the research also raises some important caveats and areas for further investigation.
One key limitation is that the evaluation was conducted in relatively constrained 2D grid-based environments, which may not fully capture the complexity of real-world spatial reasoning tasks. Extending the VoT approach to more complex, three-dimensional environments would be an important next step to assess its broader applicability.
Additionally, the paper does not delve into the specific mechanisms by which VoT prompting improves spatial reasoning. Understanding the underlying cognitive and neural processes involved could provide valuable insights for the design of even more effective spatial reasoning tools.
Furthermore, the research focused on evaluating VoT's performance relative to existing multimodal language models, but it would be informative to also compare its effectiveness against other spatial reasoning approaches, such as those based on computer vision or reinforcement learning.
Overall, this work represents an important step in advancing the spatial reasoning capabilities of large language models. Continued research in this direction, addressing the identified limitations and exploring alternative approaches, could lead to significant advancements in the development of more well-rounded and spatially-aware AI systems.
Conclusion
This paper explores the promising potential of using "Visualization-of-Thought" (VoT) prompting to enhance the spatial reasoning abilities of large language models (LLMs). The results demonstrate that VoT can significantly improve the performance of LLMs on a range of multi-hop spatial reasoning tasks, outperforming existing multimodal language models.
The researchers' findings suggest that the capacity to generate and manipulate mental images, akin to the human "mind's eye" process, may be a crucial component in developing more capable and well-rounded AI systems. By bridging the gap between language understanding and spatial reasoning, VoT and similar techniques could pave the way for AI agents that can more effectively navigate and interact with the physical world.
While this research represents an important step forward, further exploration of VoT's applicability in more complex environments and a deeper understanding of its underlying mechanisms could lead to even more impactful advancements in the field of spatial reasoning for artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Neel Joshi
0
0
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
6/24/2024
💬
Image-of-Thought Prompting for Visual Reasoning Refinement in Multimodal Large Language Models
Qiji Zhou, Ruochen Zhou, Zike Hu, Panzhong Lu, Siyang Gao, Yue Zhang
0
0
Recent advancements in Chain-of-Thought (CoT) and related rationale-based works have significantly improved the performance of Large Language Models (LLMs) in complex reasoning tasks. With the evolution of Multimodal Large Language Models (MLLMs), enhancing their capability to tackle complex multimodal reasoning problems is a crucial frontier. However, incorporating multimodal rationales in CoT has yet to be thoroughly investigated. We propose the Image-of-Thought (IoT) prompting method, which helps MLLMs to extract visual rationales step-by-step. Specifically, IoT prompting can automatically design critical visual information extraction operations based on the input images and questions. Each step of visual information refinement identifies specific visual rationales that support answers to complex visual reasoning questions. Beyond the textual CoT, IoT simultaneously utilizes visual and textual rationales to help MLLMs understand complex multimodal information. IoT prompting has improved zero-shot visual reasoning performance across various visual understanding tasks in different MLLMs. Moreover, the step-by-step visual feature explanations generated by IoT prompting elucidate the visual reasoning process, aiding in analyzing the cognitive processes of large multimodal models
5/30/2024

Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs
Kanchana Ranasinghe, Satya Narayan Shukla, Omid Poursaeed, Michael S. Ryoo, Tsung-Yu Lin
0
0
Integration of Large Language Models (LLMs) into visual domain tasks, resulting in visual-LLMs (V-LLMs), has enabled exceptional performance in vision-language tasks, particularly for visual question answering (VQA). However, existing V-LLMs (e.g. BLIP-2, LLaVA) demonstrate weak spatial reasoning and localization awareness. Despite generating highly descriptive and elaborate textual answers, these models fail at simple tasks like distinguishing a left vs right location. In this work, we explore how image-space coordinate based instruction fine-tuning objectives could inject spatial awareness into V-LLMs. We discover optimal coordinate representations, data-efficient instruction fine-tuning objectives, and pseudo-data generation strategies that lead to improved spatial awareness in V-LLMs. Additionally, our resulting model improves VQA across image and video domains, reduces undesired hallucination, and generates better contextual object descriptions. Experiments across 5 vision-language tasks involving 14 different datasets establish the clear performance improvements achieved by our proposed framework.
4/12/2024
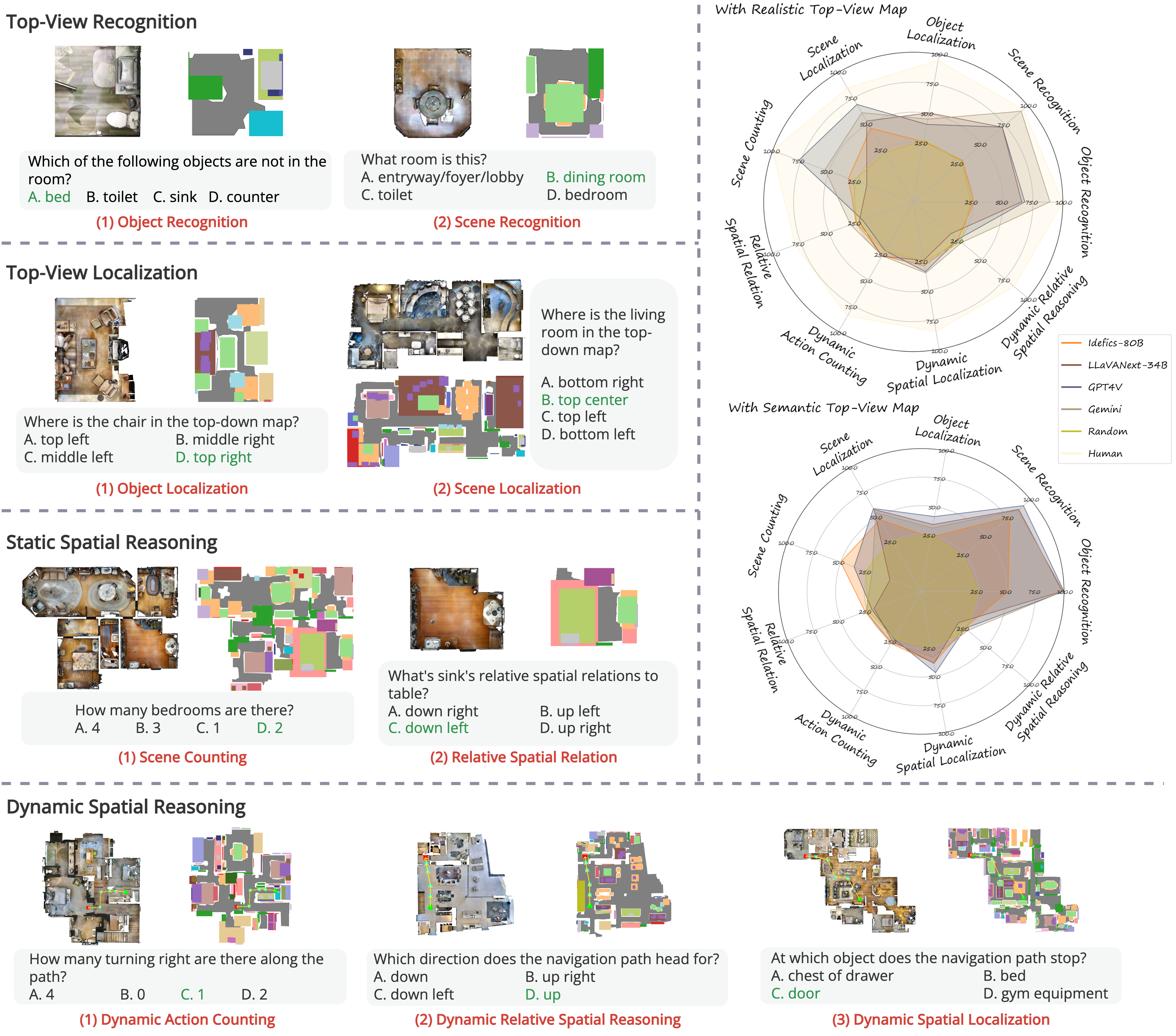
TopViewRS: Vision-Language Models as Top-View Spatial Reasoners
Chengzu Li, Caiqi Zhang, Han Zhou, Nigel Collier, Anna Korhonen, Ivan Vuli'c
0
0
Top-view perspective denotes a typical way in which humans read and reason over different types of maps, and it is vital for localization and navigation of humans as well as of `non-human' agents, such as the ones backed by large Vision-Language Models (VLMs). Nonetheless, spatial reasoning capabilities of modern VLMs remain unattested and underexplored. In this work, we thus study their capability to understand and reason over spatial relations from the top view. The focus on top view also enables controlled evaluations at different granularity of spatial reasoning; we clearly disentangle different abilities (e.g., recognizing particular objects versus understanding their relative positions). We introduce the TopViewRS (Top-View Reasoning in Space) dataset, consisting of 11,384 multiple-choice questions with either realistic or semantic top-view map as visual input. We then use it to study and evaluate VLMs across 4 perception and reasoning tasks with different levels of complexity. Evaluation of 10 representative open- and closed-source VLMs reveals the gap of more than 50% compared to average human performance, and it is even lower than the random baseline in some cases. Although additional experiments show that Chain-of-Thought reasoning can boost model capabilities by 5.82% on average, the overall performance of VLMs remains limited. Our findings underscore the critical need for enhanced model capability in top-view spatial reasoning and set a foundation for further research towards human-level proficiency of VLMs in real-world multimodal tasks.
6/5/2024