Structured Information Matters: Incorporating Abstract Meaning Representation into LLMs for Improved Open-Domain Dialogue Evaluation

0
Sign in to get full access
Overview
- This paper explores incorporating Abstract Meaning Representation (AMR) into large language models (LLMs) to improve open-domain dialogue evaluation.
- AMR is a semantic formalism that captures the underlying meaning of a sentence, which the authors hypothesize can help LLMs better understand the content and context of dialogues.
- The researchers develop a model called AMRFact that leverages AMR to enhance the factuality evaluation of dialogue summaries generated by LLMs.
Plain English Explanation
The paper focuses on improving how AI systems evaluate open-ended conversations, or dialogues. When we have a conversation with someone, there's often more meaning behind the words than what is explicitly stated. Researchers have developed a way to represent the underlying meaning of sentences called Abstract Meaning Representation (AMR).
The authors of this paper believe that incorporating AMR into large language models (LLMs) - powerful AI systems trained on vast amounts of text data - can help them better understand the context and content of dialogues. To test this, they created a model called AMRFact that uses AMR to evaluate how factual the summaries generated by LLMs are.
The key idea is that by tapping into the deeper semantic meaning captured by AMR, LLMs can provide more accurate and meaningful evaluations of open-ended conversations. This could lead to significant improvements in how AI assistants and chatbots understand and respond to human dialogue.
Technical Explanation
The paper proposes a novel approach called AMRFact that incorporates Abstract Meaning Representation (AMR) into large language models (LLMs) to improve open-domain dialogue evaluation. AMR is a semantic formalism that represents the underlying meaning of a sentence in a structured graph format, aiming to capture the core semantic roles and relationships.
The authors hypothesize that leveraging AMR can enhance LLMs' understanding of the content and context of dialogues, leading to more accurate evaluations. To test this, they develop an AMRFact model that takes the AMR graphs of dialogue utterances as input, in addition to the text, and uses this structured semantic information to better assess the factuality of generated dialogue summaries.
In their experiments, the researchers compare AMRFact to LLM-only baselines on benchmark dialogue datasets. The results demonstrate that incorporating AMR significantly improves the factuality of the summaries, as measured by both automatic metrics and human evaluation. This suggests that structured semantic representations like AMR can indeed enhance LLMs' dialogue understanding and generation capabilities.
Critical Analysis
The paper makes a compelling case for the value of incorporating structured semantic information, such as AMR, into LLMs for open-domain dialogue understanding and evaluation. The authors provide a thorough technical explanation of their AMRFact model and present convincing empirical results to support their claims.
One potential limitation is the reliance on AMR, which can be challenging to generate accurately, especially for more complex or context-dependent language. The authors acknowledge this and suggest exploring other semantic representations as future work. Additionally, the paper focuses solely on factuality evaluation, and it would be interesting to see how AMR-enhanced LLMs perform on other dialogue assessment tasks, such as coherence, engagement, or overall quality.
Furthermore, the authors do not discuss potential biases or ethical considerations that may arise from using AMR-augmented LLMs for dialogue evaluation. As these models become more powerful and widely deployed, it will be crucial to carefully examine their fairness, transparency, and accountability.
Overall, the paper makes a strong contribution by demonstrating the value of incorporating structured semantic information into LLMs for more effective open-domain dialogue processing. The findings highlight the importance of considering both linguistic form and meaning when developing advanced natural language understanding systems.
Conclusion
This paper presents a novel approach, called AMRFact, that leverages Abstract Meaning Representation (AMR) to enhance the dialogue evaluation capabilities of large language models (LLMs). By incorporating the structured semantic information captured by AMR, the authors show that LLMs can provide more accurate and factual summaries of open-ended conversations.
The key insight is that understanding the underlying meaning and relationships in dialogue, not just the surface-level language, is crucial for effective open-domain dialogue processing. The promising results of the AMRFact model suggest that further research into integrating structured semantic representations with powerful LLMs could lead to significant advancements in areas such as conversational AI, intelligent assistants, and human-machine interaction.
As LLMs continue to play an increasingly prominent role in our lives, it will be important to ensure that they can deeply comprehend the nuances and context of human dialogue. The work presented in this paper represents an important step in that direction, highlighting the value of incorporating structured information to improve the capabilities and interpretability of these transformative language technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Structured Information Matters: Incorporating Abstract Meaning Representation into LLMs for Improved Open-Domain Dialogue Evaluation
Bohao Yang, Kun Zhao, Chen Tang, Dong Liu, Liang Zhan, Chenghua Lin
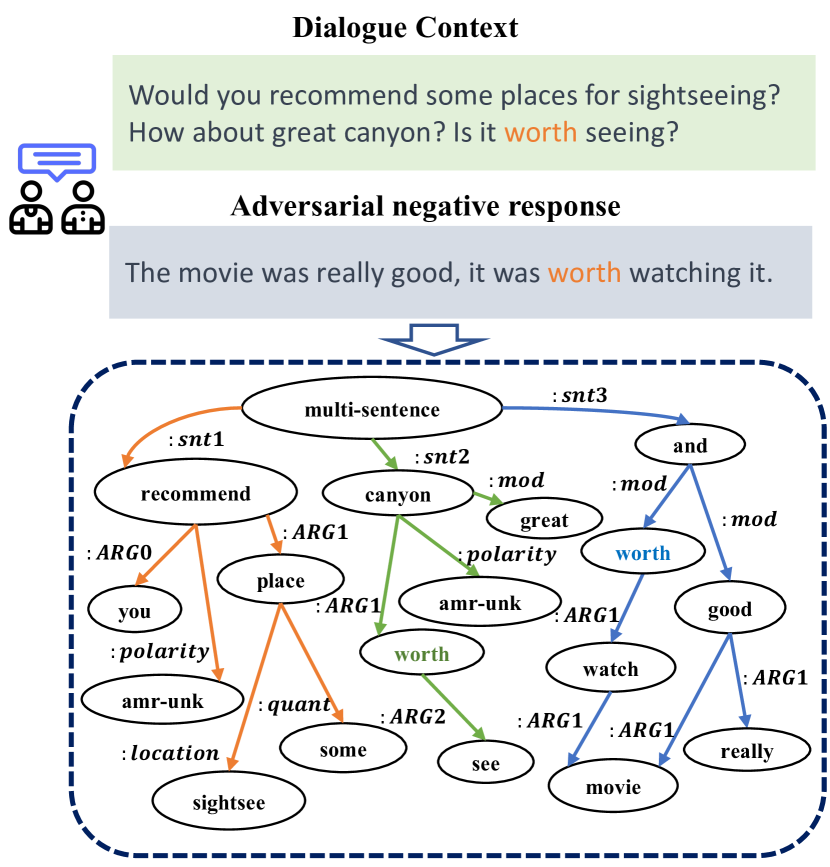
Automatic open-domain dialogue evaluation has attracted increasing attention. Trainable evaluation metrics, typically trained with true positive and randomly selected negative responses, tend to assign higher scores to responses that share greater content similarity with a given context. However, adversarial negative responses, despite possessing high content similarity with the contexts, are semantically different. Consequently, existing evaluation metrics are not robust enough to evaluate such responses, resulting in low correlations with human judgments. While recent studies have demonstrated the effectiveness of Large Language Models (LLMs) for open-domain dialogue evaluation, they still face challenges in effectively handling adversarial negative examples. In this paper, we propose an effective framework for open-domain dialogue evaluation, which combines domain-specific language models (SLMs) enhanced with Abstract Meaning Representation (AMR) knowledge with LLMs. The SLMs can explicitly incorporate AMR graph information of the dialogue through a gating mechanism for enhanced dialogue semantic representation learning. Both the evaluation result from the SLMs and the AMR graph information are incorporated into the LLM's prompt for enhanced evaluation performance. Experimental results on open-domain dialogue evaluation tasks demonstrate the superiority of our method compared to a wide range of state-of-the-art baselines, especially in discriminating adversarial negative responses. Our code and data are publicly available at https://github.com/Bernard-Yang/SIMAMR.
Read more8/19/2024
💬
0
Analyzing the Role of Semantic Representations in the Era of Large Language Models
Zhijing Jin, Yuen Chen, Fernando Gonzalez, Jiarui Liu, Jiayi Zhang, Julian Michael, Bernhard Scholkopf, Mona Diab
Traditionally, natural language processing (NLP) models often use a rich set of features created by linguistic expertise, such as semantic representations. However, in the era of large language models (LLMs), more and more tasks are turned into generic, end-to-end sequence generation problems. In this paper, we investigate the question: what is the role of semantic representations in the era of LLMs? Specifically, we investigate the effect of Abstract Meaning Representation (AMR) across five diverse NLP tasks. We propose an AMR-driven chain-of-thought prompting method, which we call AMRCoT, and find that it generally hurts performance more than it helps. To investigate what AMR may have to offer on these tasks, we conduct a series of analysis experiments. We find that it is difficult to predict which input examples AMR may help or hurt on, but errors tend to arise with multi-word expressions, named entities, and in the final inference step where the LLM must connect its reasoning over the AMR to its prediction. We recommend focusing on these areas for future work in semantic representations for LLMs. Our code: https://github.com/causalNLP/amr_llm.
Read more5/3/2024

0
SLIDE: A Framework Integrating Small and Large Language Models for Open-Domain Dialogues Evaluation
Kun Zhao, Bohao Yang, Chen Tang, Chenghua Lin, Liang Zhan
The long-standing one-to-many problem of gold standard responses in open-domain dialogue systems presents challenges for automatic evaluation metrics. Though prior works have demonstrated some success by applying powerful Large Language Models (LLMs), existing approaches still struggle with the one-to-many problem, and exhibit subpar performance in domain-specific scenarios. We assume the commonsense reasoning biases within LLMs may hinder their performance in domainspecific evaluations. To address both issues, we propose a novel framework SLIDE (Small and Large Integrated for Dialogue Evaluation), that leverages both a small, specialised model (SLM), and LLMs for the evaluation of open domain dialogues. Our approach introduces several techniques: (1) Contrastive learning to differentiate between robust and non-robust response embeddings; (2) A novel metric for semantic sensitivity that combines embedding cosine distances with similarity learned through neural networks, and (3) a strategy for incorporating the evaluation results from both the SLM and LLMs. Our empirical results demonstrate that our approach achieves state-of-the-art performance in both the classification and evaluation tasks, and additionally the SLIDE evaluator exhibits better correlation with human judgements. Our code is available at https:// github.com/hegehongcha/SLIDE-ACL2024.
Read more5/31/2024

0
On the Benchmarking of LLMs for Open-Domain Dialogue Evaluation
John Mendonc{c}a, Alon Lavie, Isabel Trancoso
Large Language Models (LLMs) have showcased remarkable capabilities in various Natural Language Processing tasks. For automatic open-domain dialogue evaluation in particular, LLMs have been seamlessly integrated into evaluation frameworks, and together with human evaluation, compose the backbone of most evaluations. However, existing evaluation benchmarks often rely on outdated datasets and evaluate aspects like Fluency and Relevance, which fail to adequately capture the capabilities and limitations of state-of-the-art chatbot models. This paper critically examines current evaluation benchmarks, highlighting that the use of older response generators and quality aspects fail to accurately reflect modern chatbot capabilities. A small annotation experiment on a recent LLM-generated dataset (SODA) reveals that LLM evaluators such as GPT-4 struggle to detect actual deficiencies in dialogues generated by current LLM chatbots.
Read more7/8/2024