SLIDE: A Framework Integrating Small and Large Language Models for Open-Domain Dialogues Evaluation
2405.15924
0
0

Abstract
The long-standing one-to-many problem of gold standard responses in open-domain dialogue systems presents challenges for automatic evaluation metrics. Though prior works have demonstrated some success by applying powerful Large Language Models (LLMs), existing approaches still struggle with the one-to-many problem, and exhibit subpar performance in domain-specific scenarios. We assume the commonsense reasoning biases within LLMs may hinder their performance in domainspecific evaluations. To address both issues, we propose a novel framework SLIDE (Small and Large Integrated for Dialogue Evaluation), that leverages both a small, specialised model (SLM), and LLMs for the evaluation of open domain dialogues. Our approach introduces several techniques: (1) Contrastive learning to differentiate between robust and non-robust response embeddings; (2) A novel metric for semantic sensitivity that combines embedding cosine distances with similarity learned through neural networks, and (3) a strategy for incorporating the evaluation results from both the SLM and LLMs. Our empirical results demonstrate that our approach achieves state-of-the-art performance in both the classification and evaluation tasks, and additionally the SLIDE evaluator exhibits better correlation with human judgements. Our code is available at https:// github.com/hegehongcha/SLIDE-ACL2024.
Create account to get full access
Overview
- This paper presents a framework called SLIDE (Small and Large-scale Integrated Dialogues Evaluation) that integrates small and large language models for evaluating open-domain dialogues.
- The framework aims to provide a comprehensive and systematic approach to assessing the performance of dialogue systems across various dimensions, including coherence, informativeness, and task completion.
- SLIDE leverages the complementary strengths of small and large language models to provide a more nuanced and robust evaluation of dialogue systems.
Plain English Explanation
The paper introduces a new framework called SLIDE (Small and Large-scale Integrated Dialogues Evaluation) that combines the power of small and large language models to assess the performance of open-domain dialogue systems. Dialogue systems are AI-powered chatbots that can engage in natural conversations on a wide range of topics.
Evaluating the performance of dialogue systems is a complex task because there are many different aspects to consider, such as how coherent and informative the responses are, and whether the system can effectively complete specific tasks. Large language models are powerful at generating human-like responses, but they can sometimes lack the contextual understanding and reasoning capabilities needed for a comprehensive dialogue evaluation.
SLIDE aims to address this by integrating small and large language models, leveraging the strengths of each. The small models are better at understanding the context and nuances of a conversation, while the large models can generate more natural and diverse responses. By combining these two approaches, the SLIDE framework can provide a more thorough and reliable evaluation of dialogue systems, helping to identify their strengths and weaknesses.
Technical Explanation
The SLIDE framework integrates small and large language models to evaluate open-domain dialogues. The small models, such as DialoGPT, are used to assess the coherence, relevance, and contextual understanding of the dialogue, while the large models, such as GPT-3, are used to generate and evaluate the informativeness and quality of the responses.
The framework consists of several key components:
-
Dialogue Preprocessing: The input dialogue is preprocessed to extract relevant features, such as the conversational context, speaker roles, and task-specific information.
-
Small Model Evaluation: The small language models are used to assess the coherence, relevance, and contextual understanding of the dialogue, generating scores for these dimensions.
-
Large Model Evaluation: The large language models are used to generate alternative responses and evaluate their informativeness, quality, and task-completion capabilities.
-
Integrated Scoring: The scores from the small and large model evaluations are combined to provide a comprehensive assessment of the dialogue system's performance.
The authors demonstrate the effectiveness of the SLIDE framework through experiments on several open-domain dialogue datasets, showing that it outperforms existing evaluation approaches in terms of reliability, sensitivity, and alignment with human judgments.
Critical Analysis
The SLIDE framework represents a significant advance in the evaluation of open-domain dialogue systems, as it addresses some of the limitations of using either small or large language models in isolation. By integrating the strengths of both model types, the framework can provide a more nuanced and comprehensive assessment of dialogue performance.
However, the paper does not fully address some potential limitations and areas for future research. For example, the framework's reliance on task-specific information and preprocessing steps may limit its generalizability to a wider range of dialogue scenarios. Additionally, the authors do not discuss the potential biases or blindspots that may be introduced by the small and large language models used in the framework.
Further research could explore ways to make the SLIDE framework more flexible and adaptable, potentially by incorporating unsupervised or self-supervised approaches to dialogue evaluation. Incorporating abstract meaning representation or other structured representations of dialogue could also help to improve the framework's ability to capture the deeper semantic and pragmatic aspects of conversations.
Conclusion
The SLIDE framework represents an important step forward in the evaluation of open-domain dialogue systems, combining the strengths of small and large language models to provide a more comprehensive and reliable assessment. By integrating multiple evaluation dimensions, the framework can help researchers and developers identify the strengths and weaknesses of their dialogue systems, ultimately leading to more robust and effective conversational AI. As the field of dialogue systems continues to evolve, frameworks like SLIDE will play a crucial role in driving progress and ensuring the development of high-quality, human-centered dialogue capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Structured Information Matters: Incorporating Abstract Meaning Representation into LLMs for Improved Open-Domain Dialogue Evaluation
Bohao Yang, Kun Zhao, Chen Tang, Liang Zhan, Chenghua Lin
0
0
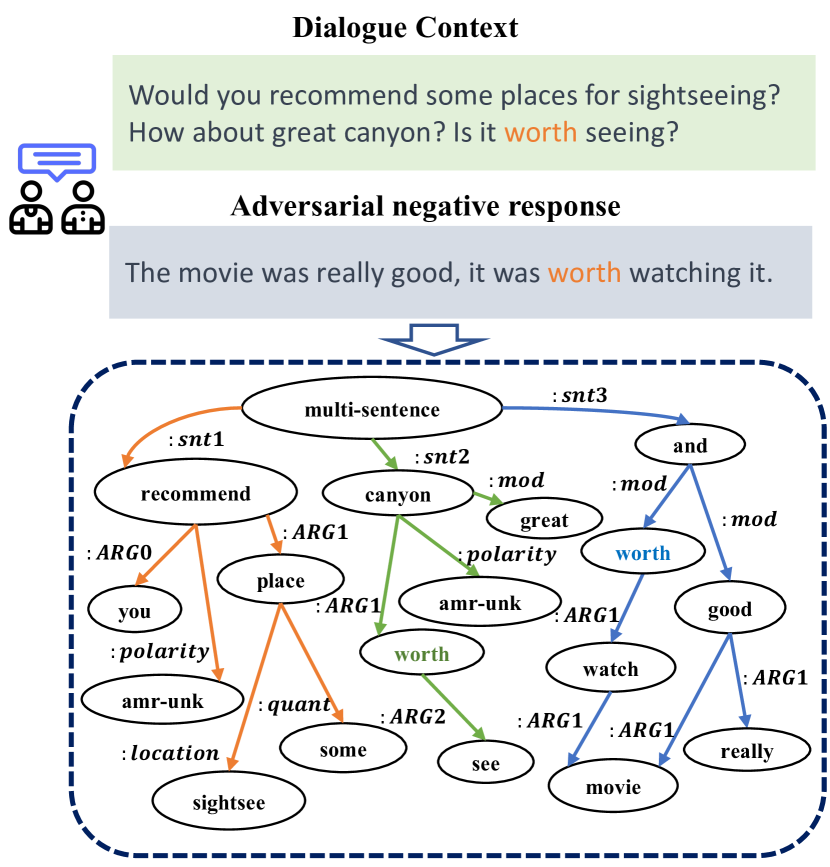
Automatic open-domain dialogue evaluation has attracted increasing attention. Trainable evaluation metrics are commonly trained with true positive and randomly selected negative responses, resulting in a tendency for them to assign a higher score to the responses that share higher content similarity with a given context. However, adversarial negative responses possess high content similarity with the contexts whilst being semantically different. Therefore, existing evaluation metrics are not robust enough to evaluate such responses, resulting in low correlations with human judgments. While recent studies have shown some efficacy in utilizing Large Language Models (LLMs) for open-domain dialogue evaluation, they still encounter challenges in effectively handling adversarial negative examples. In this paper, we propose a simple yet effective framework for open-domain dialogue evaluation, which combines domain-specific language models (SLMs) with LLMs. The SLMs can explicitly incorporate Abstract Meaning Representation (AMR) graph information of the dialogue through a gating mechanism for enhanced semantic representation learning. The evaluation result of SLMs and AMR graph information are plugged into the prompt of LLM, for the enhanced in-context learning performance. Experimental results on open-domain dialogue evaluation tasks demonstrate the superiority of our method compared to a wide range of state-of-the-art baselines, especially in discriminating adversarial negative responses. Our code is available at https://github.com/Bernard-Yang/SIMAMR.
4/9/2024
Large Language Model based Situational Dialogues for Second Language Learning
Shuyao Xu, Long Qin, Tianyang Chen, Zhenzhou Zha, Bingxue Qiu, Weizhi Wang
0
0
In second language learning, scenario-based conversation practice is important for language learners to achieve fluency in speaking, but students often lack sufficient opportunities to practice their conversational skills with qualified instructors or native speakers. To bridge this gap, we propose situational dialogue models for students to engage in conversational practice. Our situational dialogue models are fine-tuned on large language models (LLMs), with the aim of combining the engaging nature of an open-ended conversation with the focused practice of scenario-based tasks. Leveraging the generalization capabilities of LLMs, we demonstrate that our situational dialogue models perform effectively not only on training topics but also on topics not encountered during training. This offers a promising solution to support a wide range of conversational topics without extensive manual work. Additionally, research in the field of dialogue systems still lacks reliable automatic evaluation metrics, leading to human evaluation as the gold standard (Smith et al., 2022), which is typically expensive. To address the limitations of existing evaluation methods, we present a novel automatic evaluation method that employs fine-tuned LLMs to efficiently and effectively assess the performance of situational dialogue models.
4/1/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024
Should We Fine-Tune or RAG? Evaluating Different Techniques to Adapt LLMs for Dialogue
Simone Alghisi, Massimo Rizzoli, Gabriel Roccabruna, Seyed Mahed Mousavi, Giuseppe Riccardi
0
0
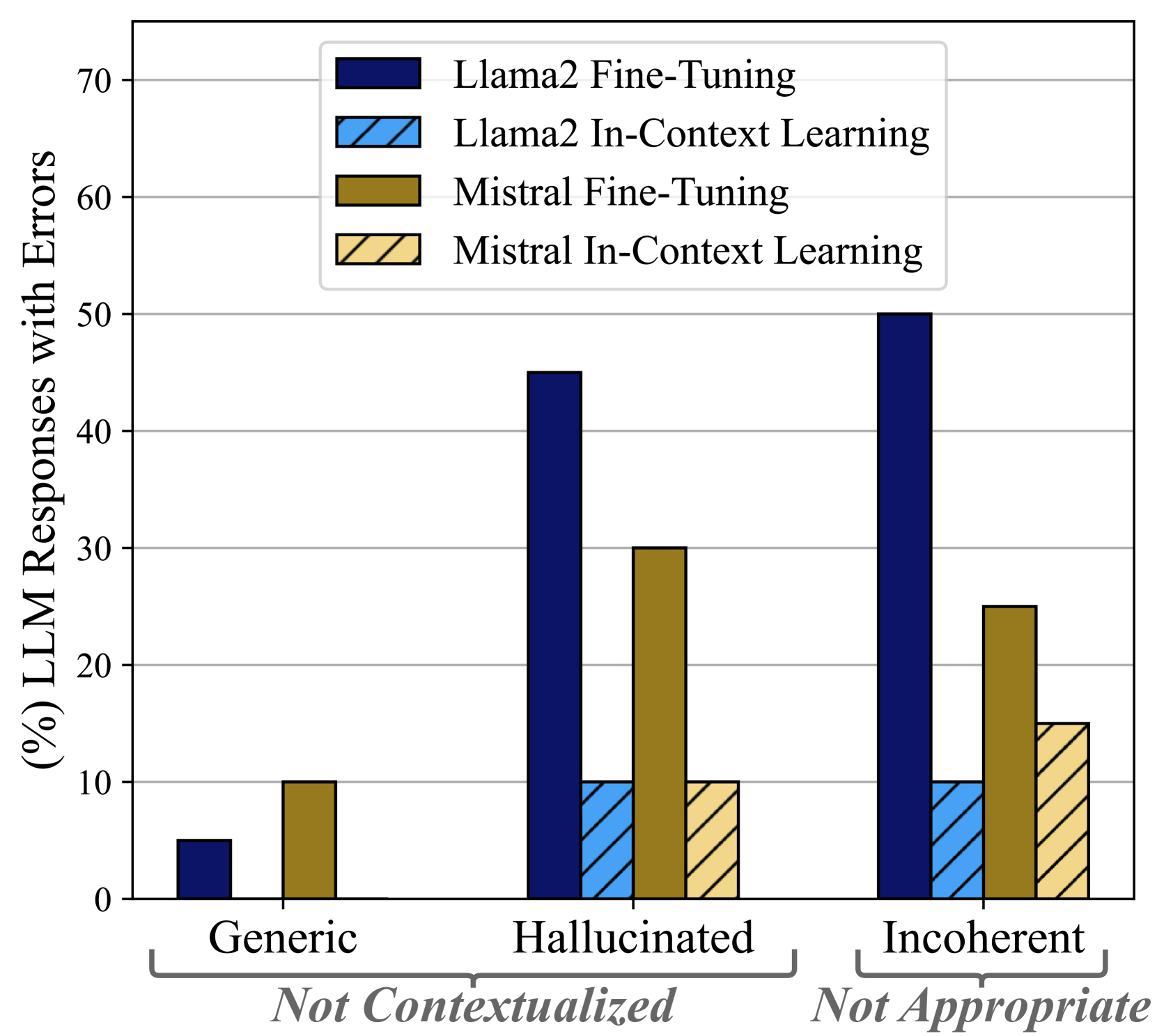
We study the limitations of Large Language Models (LLMs) for the task of response generation in human-machine dialogue. Several techniques have been proposed in the literature for different dialogue types (e.g., Open-Domain). However, the evaluations of these techniques have been limited in terms of base LLMs, dialogue types and evaluation metrics. In this work, we extensively analyze different LLM adaptation techniques when applied to different dialogue types. We have selected two base LLMs, Llama-2 and Mistral, and four dialogue types Open-Domain, Knowledge-Grounded, Task-Oriented, and Question Answering. We evaluate the performance of in-context learning and fine-tuning techniques across datasets selected for each dialogue type. We assess the impact of incorporating external knowledge to ground the generation in both scenarios of Retrieval-Augmented Generation (RAG) and gold knowledge. We adopt consistent evaluation and explainability criteria for automatic metrics and human evaluation protocols. Our analysis shows that there is no universal best-technique for adapting large language models as the efficacy of each technique depends on both the base LLM and the specific type of dialogue. Last but not least, the assessment of the best adaptation technique should include human evaluation to avoid false expectations and outcomes derived from automatic metrics.
6/11/2024