Analyzing the Role of Semantic Representations in the Era of Large Language Models

0
💬
Sign in to get full access
Overview
- The paper investigates the role of semantic representations, specifically Abstract Meaning Representation (AMR), in the era of large language models (LLMs) across five diverse NLP tasks.
- The authors propose an AMR-driven chain-of-thought prompting method, called AMRCoT, and find that it generally hurts performance more than it helps.
- The paper conducts a series of analysis experiments to understand where AMR may be helpful or problematic for LLMs.
- The key findings suggest that it is difficult to predict when AMR will be beneficial, but errors tend to arise with multi-word expressions, named entities, and in the final inference step.
Plain English Explanation
In the past, natural language processing (NLP) models often relied on a rich set of features created by linguistic experts, such as semantic representations. However, with the rise of large language models (LLMs), more and more tasks are being approached as generic, end-to-end sequence generation problems.
This paper investigates the role of semantic representations, specifically Abstract Meaning Representation (AMR), in the context of LLMs. The researchers propose a new method called AMRCoT, which uses AMR to guide the LLM's reasoning process through a chain of thoughts.
The key finding is that the AMRCoT method generally hurts the LLM's performance more than it helps. The researchers then analyze why this might be the case, looking at different types of language constructs and the final inference step where the LLM must connect its reasoning to the final prediction.
The main takeaway is that while semantic representations like AMR may have potential, it is challenging to reliably predict when they will be beneficial for LLMs. The researchers recommend focusing future work on addressing issues with multi-word expressions, named entities, and the final inference step.
Technical Explanation
The paper explores the role of semantic representations, specifically Abstract Meaning Representation (AMR), in the era of large language models (LLMs). AMR is a semantic formalism that represents the meaning of a sentence as a directed acyclic graph.
The authors propose an AMR-driven chain-of-thought prompting method, called AMRCoT, which aims to guide the LLM's reasoning process by providing it with the AMR representation of the input. They evaluate this approach across five diverse NLP tasks: question answering, summarization, dialogue, sentiment analysis, and semantic parsing.
The results show that the AMRCoT method generally hurts performance more than it helps, suggesting that the benefits of incorporating explicit semantic representations may be limited in the era of LLMs.
To investigate this further, the authors conduct a series of analysis experiments. They find that it is difficult to predict which input examples AMR may help or hurt on, but errors tend to arise with multi-word expressions, named entities, and in the final inference step where the LLM must connect its reasoning over the AMR to its prediction.
The paper also discusses the implications of these findings for the role of semantic representations in the era of LLMs and provides recommendations for future work in this area.
Critical Analysis
The paper raises important questions about the role of semantic representations, such as AMR, in the context of large language models (LLMs). While the authors' findings suggest that the benefits of incorporating explicit semantic representations may be limited, the paper also highlights the challenges in reliably predicting when these representations may be helpful or harmful for LLMs.
One limitation of the study is that it focuses on a single semantic representation, AMR, and it would be valuable to investigate the effects of other types of semantic representations as well. Additionally, the paper does not delve into the potential reasons why AMR may be more beneficial for certain tasks or input examples than others, which could provide valuable insights for future research.
Furthermore, the paper does not address the potential long-term implications of the observed trends, such as the impact on the evolution of LLMs' latent representations and temporal knowledge. As LLMs continue to advance, understanding the role of semantic representations may become increasingly crucial for building effective recommender systems and other applications that rely on natural language understanding.
Overall, the paper provides a valuable contribution to the ongoing discussion on the role of semantic representations in the era of LLMs, and the findings presented serve as a starting point for further research in this important area.
Conclusion
This paper investigates the role of semantic representations, specifically Abstract Meaning Representation (AMR), in the context of large language models (LLMs). The authors propose an AMR-driven chain-of-thought prompting method, called AMRCoT, and find that it generally hurts performance more than it helps across five diverse NLP tasks.
The key takeaways from this study are:
- It is challenging to reliably predict when incorporating explicit semantic representations like AMR will be beneficial for LLMs.
- Errors tend to arise with multi-word expressions, named entities, and in the final inference step where the LLM must connect its reasoning over the AMR to the final prediction.
- Future research should focus on addressing these issues to better understand the potential role of semantic representations in the era of LLMs.
Overall, this paper highlights the need for further exploration of the interplay between semantic representations and the capabilities of large language models, which have become increasingly dominant in natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Analyzing the Role of Semantic Representations in the Era of Large Language Models
Zhijing Jin, Yuen Chen, Fernando Gonzalez, Jiarui Liu, Jiayi Zhang, Julian Michael, Bernhard Scholkopf, Mona Diab
Traditionally, natural language processing (NLP) models often use a rich set of features created by linguistic expertise, such as semantic representations. However, in the era of large language models (LLMs), more and more tasks are turned into generic, end-to-end sequence generation problems. In this paper, we investigate the question: what is the role of semantic representations in the era of LLMs? Specifically, we investigate the effect of Abstract Meaning Representation (AMR) across five diverse NLP tasks. We propose an AMR-driven chain-of-thought prompting method, which we call AMRCoT, and find that it generally hurts performance more than it helps. To investigate what AMR may have to offer on these tasks, we conduct a series of analysis experiments. We find that it is difficult to predict which input examples AMR may help or hurt on, but errors tend to arise with multi-word expressions, named entities, and in the final inference step where the LLM must connect its reasoning over the AMR to its prediction. We recommend focusing on these areas for future work in semantic representations for LLMs. Our code: https://github.com/causalNLP/amr_llm.
Read more5/3/2024
0
Structured Information Matters: Incorporating Abstract Meaning Representation into LLMs for Improved Open-Domain Dialogue Evaluation
Bohao Yang, Kun Zhao, Chen Tang, Dong Liu, Liang Zhan, Chenghua Lin
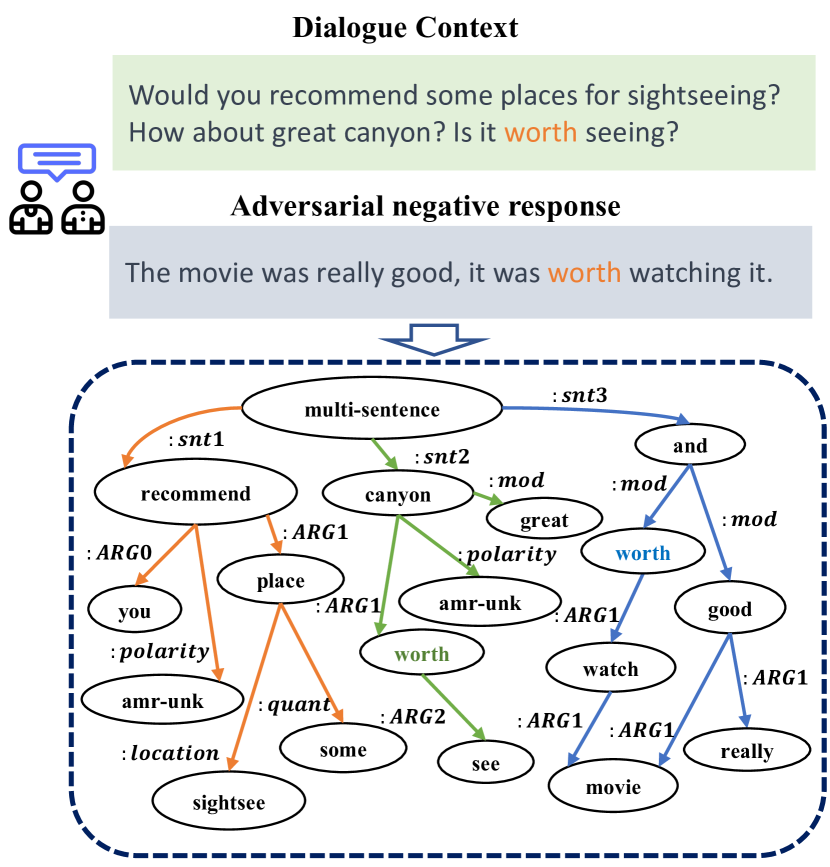
Automatic open-domain dialogue evaluation has attracted increasing attention. Trainable evaluation metrics, typically trained with true positive and randomly selected negative responses, tend to assign higher scores to responses that share greater content similarity with a given context. However, adversarial negative responses, despite possessing high content similarity with the contexts, are semantically different. Consequently, existing evaluation metrics are not robust enough to evaluate such responses, resulting in low correlations with human judgments. While recent studies have demonstrated the effectiveness of Large Language Models (LLMs) for open-domain dialogue evaluation, they still face challenges in effectively handling adversarial negative examples. In this paper, we propose an effective framework for open-domain dialogue evaluation, which combines domain-specific language models (SLMs) enhanced with Abstract Meaning Representation (AMR) knowledge with LLMs. The SLMs can explicitly incorporate AMR graph information of the dialogue through a gating mechanism for enhanced dialogue semantic representation learning. Both the evaluation result from the SLMs and the AMR graph information are incorporated into the LLM's prompt for enhanced evaluation performance. Experimental results on open-domain dialogue evaluation tasks demonstrate the superiority of our method compared to a wide range of state-of-the-art baselines, especially in discriminating adversarial negative responses. Our code and data are publicly available at https://github.com/Bernard-Yang/SIMAMR.
Read more8/19/2024

0
Semantic Graphs for Syntactic Simplification: A Revisit from the Age of LLM
Peiran Yao, Kostyantyn Guzhva, Denilson Barbosa
Symbolic sentence meaning representations, such as AMR (Abstract Meaning Representation) provide expressive and structured semantic graphs that act as intermediates that simplify downstream NLP tasks. However, the instruction-following capability of large language models (LLMs) offers a shortcut to effectively solve NLP tasks, questioning the utility of semantic graphs. Meanwhile, recent work has also shown the difficulty of using meaning representations merely as a helpful auxiliary for LLMs. We revisit the position of semantic graphs in syntactic simplification, the task of simplifying sentence structures while preserving their meaning, which requires semantic understanding, and evaluate it on a new complex and natural dataset. The AMR-based method that we propose, AMRS$^3$, demonstrates that state-of-the-art meaning representations can lead to easy-to-implement simplification methods with competitive performance and unique advantages in cost, interpretability, and generalization. With AMRS$^3$ as an anchor, we discover that syntactic simplification is a task where semantic graphs are helpful in LLM prompting. We propose AMRCoC prompting that guides LLMs to emulate graph algorithms for explicit symbolic reasoning on AMR graphs, and show its potential for improving LLM on semantic-centered tasks like syntactic simplification.
Read more7/8/2024
📊
0
Abstract Meaning Representation-Based Logic-Driven Data Augmentation for Logical Reasoning
Qiming Bao, Alex Yuxuan Peng, Zhenyun Deng, Wanjun Zhong, Gael Gendron, Timothy Pistotti, Neset Tan, Nathan Young, Yang Chen, Yonghua Zhu, Paul Denny, Michael Witbrock, Jiamou Liu
Combining large language models with logical reasoning enhances their capacity to address problems in a robust and reliable manner. Nevertheless, the intricate nature of logical reasoning poses challenges when gathering reliable data from the web to build comprehensive training datasets, subsequently affecting performance on downstream tasks. To address this, we introduce a novel logic-driven data augmentation approach, AMR-LDA. AMR-LDA converts the original text into an Abstract Meaning Representation (AMR) graph, a structured semantic representation that encapsulates the logical structure of the sentence, upon which operations are performed to generate logically modified AMR graphs. The modified AMR graphs are subsequently converted back into text to create augmented data. Notably, our methodology is architecture-agnostic and enhances both generative large language models, such as GPT-3.5 and GPT-4, through prompt augmentation, and discriminative large language models through contrastive learning with logic-driven data augmentation. Empirical evidence underscores the efficacy of our proposed method with improvement in performance across seven downstream tasks, such as reading comprehension requiring logical reasoning, textual entailment, and natural language inference. Furthermore, our method leads on the ReClor leaderboardfootnote{url{https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347}}. The source code and data are publicly availablefootnote{href{https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning}{AMR-LDA GitHub Repository}}.
Read more6/6/2024