Empirical Analysis of Dialogue Relation Extraction with Large Language Models
2404.17802
0
0

Abstract
Dialogue relation extraction (DRE) aims to extract relations between two arguments within a dialogue, which is more challenging than standard RE due to the higher person pronoun frequency and lower information density in dialogues. However, existing DRE methods still suffer from two serious issues: (1) hard to capture long and sparse multi-turn information, and (2) struggle to extract golden relations based on partial dialogues, which motivates us to discover more effective methods that can alleviate the above issues. We notice that the rise of large language models (LLMs) has sparked considerable interest in evaluating their performance across diverse tasks. To this end, we initially investigate the capabilities of different LLMs in DRE, considering both proprietary models and open-source models. Interestingly, we discover that LLMs significantly alleviate two issues in existing DRE methods. Generally, we have following findings: (1) scaling up model size substantially boosts the overall DRE performance and achieves exceptional results, tackling the difficulty of capturing long and sparse multi-turn information; (2) LLMs encounter with much smaller performance drop from entire dialogue setting to partial dialogue setting compared to existing methods; (3) LLMs deliver competitive or superior performances under both full-shot and few-shot settings compared to current state-of-the-art; (4) LLMs show modest performances on inverse relations but much stronger improvements on general relations, and they can handle dialogues of various lengths especially for longer sequences.
Create account to get full access
Overview
- The paper explores the use of large language models (LLMs) for dialogue relation extraction (DRE), which involves identifying the relationships between utterances in a dialogue.
- The researchers conduct an empirical analysis to understand the performance of LLMs on DRE tasks, investigating factors such as model architecture, training data, and task formulation.
- The paper provides insights into the strengths and limitations of LLMs for DRE and suggests directions for future research in this area.
Plain English Explanation
Dialogue relation extraction (DRE) is the process of understanding how the different statements in a conversation are connected to each other. This is an important task for applications like chatbots, where the system needs to grasp the context and meaning behind the user's messages.
The researchers in this paper examine how well large language models (LLMs) – powerful AI systems trained on vast amounts of text data – perform at DRE tasks. They explore various factors that can influence the models' performance, such as the model architecture, the training data used, and how the task is framed.
The key findings from the paper can help guide the development of more robust and effective DRE systems using LLMs. For example, the researchers identify certain limitations of LLMs when it comes to capturing the nuanced relationships between dialogue utterances. This knowledge can inform future research and development efforts in this area.
Overall, this paper provides valuable insights into the strengths and weaknesses of using LLMs for dialogue relation extraction, which is an important step towards building more natural and intelligent conversational AI systems.
Technical Explanation
The researchers conduct an empirical analysis to investigate the performance of large language models (LLMs) on dialogue relation extraction (DRE) tasks. DRE involves identifying the semantic relationships between utterances in a dialogue, such as [elaboration], [contrast], or [agreement].
The study examines several factors that can impact LLM performance on DRE, including:
- Model Architecture: The researchers compare the effectiveness of transformer-based LLMs like BERT and RoBERTa against task-specific models like CRE-LLM and Improving Recall with Large Language Models.
- Training Data: The paper investigates how the choice of training data, such as Recall, Retrieve, Reason or Building Japanese Document-level Relation Extraction Dataset, affects DRE performance.
- Task Formulation: The researchers explore different ways of framing the DRE task, such as Retrieval-Augmented Generation-based Relation Extraction, and analyze their impact on model performance.
Through extensive experiments, the paper provides valuable insights into the strengths and limitations of LLMs for DRE. The findings highlight the importance of considering factors like model architecture, training data, and task formulation when developing LLM-based DRE systems.
Critical Analysis
The paper presents a comprehensive empirical analysis of LLM performance on dialogue relation extraction tasks, offering valuable insights for researchers and practitioners in this field. However, the authors also acknowledge several limitations and areas for further investigation:
- The study is primarily focused on English language dialogues, and the researchers note that the findings may not generalize to other languages. Further research is needed to explore the cross-linguistic applicability of the observed trends.
- The paper does not delve into the interpretability and explainability of the LLM-based DRE models. Understanding the inner workings of these systems and their decision-making processes could provide additional insights and guide future model development.
- The authors suggest that incorporating domain-specific knowledge or leveraging external resources (e.g., commonsense knowledge bases) may help improve the performance of LLMs on more complex DRE tasks. Exploring these avenues could be a fruitful direction for future research.
Overall, the paper makes a significant contribution to the understanding of LLM capabilities and limitations for dialogue relation extraction. The insights provided can inform the design of more effective and robust DRE systems, paving the way for more natural and intelligent conversational AI applications.
Conclusion
This empirical analysis of dialogue relation extraction (DRE) with large language models (LLMs) offers valuable insights for researchers and developers working in the field of conversational AI. The study explores how factors such as model architecture, training data, and task formulation can impact the performance of LLMs on DRE tasks.
The key findings suggest that while LLMs show promise for DRE, they also have inherent limitations in capturing the nuanced relationships between dialogue utterances. This knowledge can guide the development of more effective DRE systems, potentially through the incorporation of domain-specific knowledge or the use of specialized model architectures.
Overall, this paper contributes to the ongoing efforts to harness the power of large language models for natural and intelligent conversational AI applications. The insights provided can inform future research and development in this rapidly evolving field, ultimately leading to more robust and user-friendly dialogue systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How Good are LLMs at Relation Extraction under Low-Resource Scenario? Comprehensive Evaluation
Dawulie Jinensibieke, Mieradilijiang Maimaiti, Wentao Xiao, Yuanhang Zheng, Xiaobo Wang
0
0
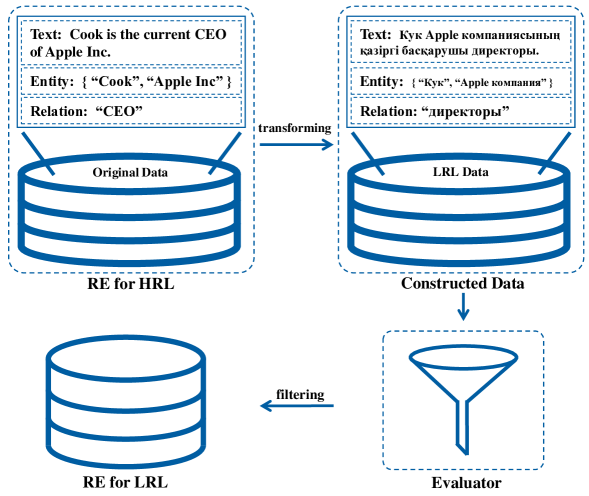
Relation Extraction (RE) serves as a crucial technology for transforming unstructured text into structured information, especially within the framework of Knowledge Graph development. Its importance is emphasized by its essential role in various downstream tasks. Besides the conventional RE methods which are based on neural networks and pre-trained language models, large language models (LLMs) are also utilized in the research field of RE. However, on low-resource languages (LRLs), both conventional RE methods and LLM-based methods perform poorly on RE due to the data scarcity issues. To this end, this paper constructs low-resource relation extraction datasets in 10 LRLs in three regions (Central Asia, Southeast Asia and Middle East). The corpora are constructed by translating the original publicly available English RE datasets (NYT10, FewRel and CrossRE) using an effective multilingual machine translation. Then, we use the language perplexity (PPL) to filter out the low-quality data from the translated datasets. Finally, we conduct an empirical study and validate the performance of several open-source LLMs on these generated LRL RE datasets.
6/27/2024

Relation Extraction with Fine-Tuned Large Language Models in Retrieval Augmented Generation Frameworks
Sefika Efeoglu, Adrian Paschke
0
0
Information Extraction (IE) is crucial for converting unstructured data into structured formats like Knowledge Graphs (KGs). A key task within IE is Relation Extraction (RE), which identifies relationships between entities in text. Various RE methods exist, including supervised, unsupervised, weakly supervised, and rule-based approaches. Recent studies leveraging pre-trained language models (PLMs) have shown significant success in this area. In the current era dominated by Large Language Models (LLMs), fine-tuning these models can overcome limitations associated with zero-shot LLM prompting-based RE methods, especially regarding domain adaptation challenges and identifying implicit relations between entities in sentences. These implicit relations, which cannot be easily extracted from a sentence's dependency tree, require logical inference for accurate identification. This work explores the performance of fine-tuned LLMs and their integration into the Retrieval Augmented-based (RAG) RE approach to address the challenges of identifying implicit relations at the sentence level, particularly when LLMs act as generators within the RAG framework. Empirical evaluations on the TACRED, TACRED-Revisited (TACREV), Re-TACRED, and SemEVAL datasets show significant performance improvements with fine-tuned LLMs, including Llama2-7B, Mistral-7B, and T5 (Large). Notably, our approach achieves substantial gains on SemEVAL, where implicit relations are common, surpassing previous results on this dataset. Additionally, our method outperforms previous works on TACRED, TACREV, and Re-TACRED, demonstrating exceptional performance across diverse evaluation scenarios.
6/26/2024
⛏️
CRE-LLM: A Domain-Specific Chinese Relation Extraction Framework with Fine-tuned Large Language Model
Zhengpeng Shi, Haoran Luo
0
0
Domain-Specific Chinese Relation Extraction (DSCRE) aims to extract relations between entities from domain-specific Chinese text. Despite the rapid development of PLMs in recent years, especially LLMs, DSCRE still faces three core challenges: complex network structure design, poor awareness, and high consumption of fine-tuning. Given the impressive performance of large language models (LLMs) in natural language processing, we propose a new framework called CRE-LLM. This framework is based on fine-tuning open-source LLMs, such as Llama-2, ChatGLM2, and Baichuan2. CRE-LLM enhances the logic-awareness and generative capabilities of the model by constructing an appropriate prompt and utilizing open-source LLMs for instruction-supervised fine-tuning. And then it directly extracts the relations of the given entities in the input textual data, which improving the CRE approach. To demonstrate the effectiveness of the proposed framework, we conducted extensive experiments on two domain-specific CRE datasets, FinRE and SanWen. The experimental results show that CRE-LLM is significantly superior and robust, achieving state-of-the-art (SOTA) performance on the FinRE dataset. This paper introduces a novel approach to domain-specific relation extraction (DSCRE) tasks that are semantically more complex by combining LLMs with triples. Our code is publicly available.
4/30/2024
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Zepeng Ding, Wenhao Huang, Jiaqing Liang, Deqing Yang, Yanghua Xiao
0
0
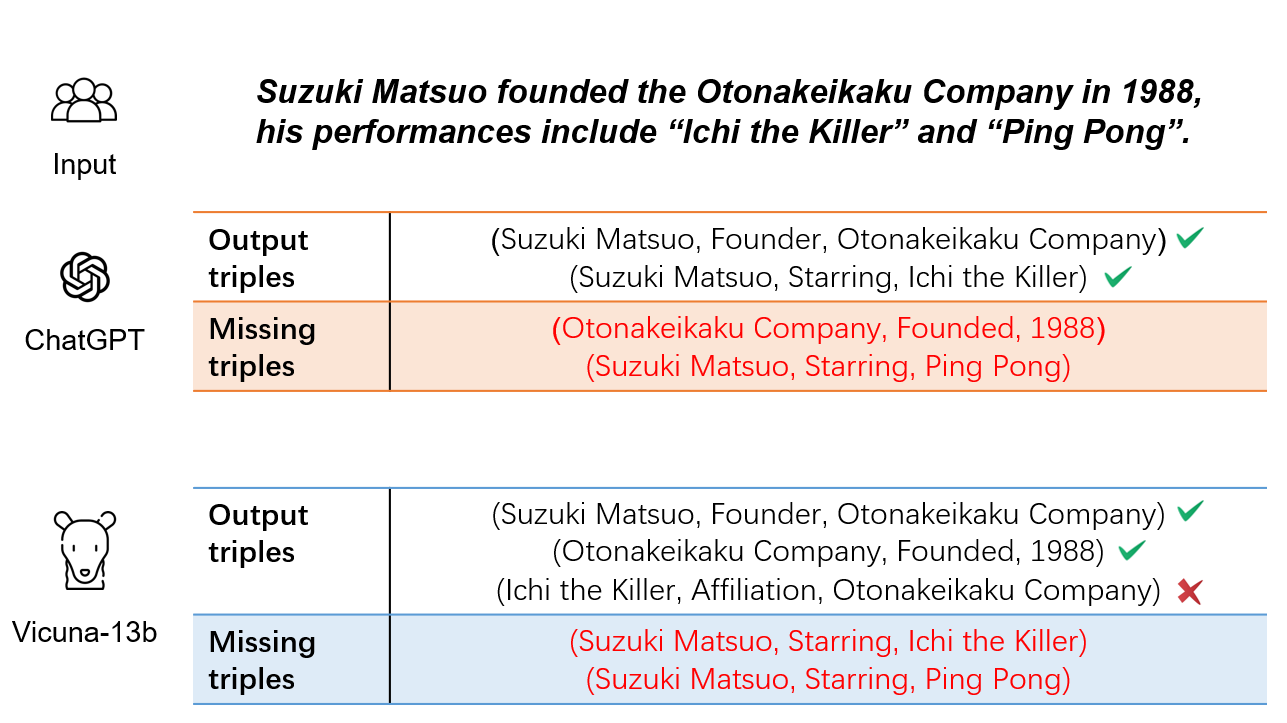
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
4/16/2024