How Good are LLMs at Relation Extraction under Low-Resource Scenario? Comprehensive Evaluation
2406.11162
0
0
Abstract
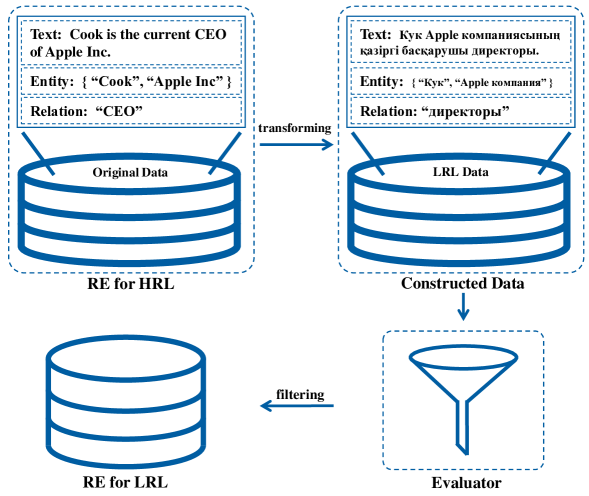
Relation Extraction (RE) serves as a crucial technology for transforming unstructured text into structured information, especially within the framework of Knowledge Graph development. Its importance is emphasized by its essential role in various downstream tasks. Besides the conventional RE methods which are based on neural networks and pre-trained language models, large language models (LLMs) are also utilized in the research field of RE. However, on low-resource languages (LRLs), both conventional RE methods and LLM-based methods perform poorly on RE due to the data scarcity issues. To this end, this paper constructs low-resource relation extraction datasets in 10 LRLs in three regions (Central Asia, Southeast Asia and Middle East). The corpora are constructed by translating the original publicly available English RE datasets (NYT10, FewRel and CrossRE) using an effective multilingual machine translation. Then, we use the language perplexity (PPL) to filter out the low-quality data from the translated datasets. Finally, we conduct an empirical study and validate the performance of several open-source LLMs on these generated LRL RE datasets.
Create account to get full access
Overview
- This paper comprehensively evaluates the performance of large language models (LLMs) in relation extraction tasks under low-resource scenarios.
- Relation extraction is the process of identifying and classifying semantic relationships between entities in text.
- The research examines how well LLMs can perform this task when limited training data is available, which is a common challenge in many real-world applications.
Plain English Explanation
Relation extraction is an important task in natural language processing that involves identifying the connections or relationships between different entities, like people, places, and organizations, mentioned in text. For example, a relation extraction system might be able to detect that a sentence like "John Smith works at Acme Inc." contains a "works at" relationship between the person "John Smith" and the company "Acme Inc."
This paper looks at how well the latest large language models (LLMs) - powerful AI systems trained on massive amounts of text data - can perform relation extraction tasks when they only have access to a small amount of training data. This is an important issue because in many real-world scenarios, there isn't a lot of labeled data available to train these models on.
The researchers conduct a comprehensive evaluation, testing different LLMs on several relation extraction benchmarks with varying amounts of training data. They want to understand the limits of these powerful language models and how their performance degrades as the training data gets more scarce. The insights from this work can help guide the development of more robust and efficient relation extraction systems that can work well even when data is limited.
Technical Explanation
The paper first provides background on relation extraction and the challenges of low-resource scenarios. It then describes the experimental setup, including the LLMs evaluated (link) and the diverse relation extraction datasets used (link, link).
The key experiments involved training the LLMs on subsets of the full training data (ranging from 1% to 100%) and evaluating their performance on held-out test sets. This allowed the researchers to measure how the models' relation extraction capabilities degrade as the amount of training data decreases.
The results show that while large language models excel at relation extraction when ample training data is available, their performance can drop significantly under low-resource conditions (link). The magnitude of the performance drop varies across datasets and model types, suggesting that certain modeling approaches may be more robust to data scarcity (link).
Critical Analysis
The paper provides a thorough and rigorous evaluation of LLM performance in low-resource relation extraction. However, it is limited to a specific set of datasets and models, and the results may not generalize to all possible real-world scenarios. Additionally, the paper does not explore the reasons behind the observed performance degradation in depth, which could provide more insight into how to address this challenge.
Further research could investigate other techniques for improving LLM robustness, such as few-shot learning, transfer learning, or dataset augmentation. Exploring the interplay between model architecture, pretraining, and fine-tuning strategies could also yield valuable insights.
Conclusion
This comprehensive study highlights the limitations of current large language models in performing relation extraction tasks when training data is scarce. The findings underscore the need for continued research and development to create more robust and efficient relation extraction systems that can operate effectively in low-resource settings. The insights from this work can help guide the design of next-generation natural language processing tools that can be more widely deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Empirical Analysis of Dialogue Relation Extraction with Large Language Models
Guozheng Li, Zijie Xu, Ziyu Shang, Jiajun Liu, Ke Ji, Yikai Guo
0
0
Dialogue relation extraction (DRE) aims to extract relations between two arguments within a dialogue, which is more challenging than standard RE due to the higher person pronoun frequency and lower information density in dialogues. However, existing DRE methods still suffer from two serious issues: (1) hard to capture long and sparse multi-turn information, and (2) struggle to extract golden relations based on partial dialogues, which motivates us to discover more effective methods that can alleviate the above issues. We notice that the rise of large language models (LLMs) has sparked considerable interest in evaluating their performance across diverse tasks. To this end, we initially investigate the capabilities of different LLMs in DRE, considering both proprietary models and open-source models. Interestingly, we discover that LLMs significantly alleviate two issues in existing DRE methods. Generally, we have following findings: (1) scaling up model size substantially boosts the overall DRE performance and achieves exceptional results, tackling the difficulty of capturing long and sparse multi-turn information; (2) LLMs encounter with much smaller performance drop from entire dialogue setting to partial dialogue setting compared to existing methods; (3) LLMs deliver competitive or superior performances under both full-shot and few-shot settings compared to current state-of-the-art; (4) LLMs show modest performances on inverse relations but much stronger improvements on general relations, and they can handle dialogues of various lengths especially for longer sequences.
4/30/2024

Relation Extraction with Fine-Tuned Large Language Models in Retrieval Augmented Generation Frameworks
Sefika Efeoglu, Adrian Paschke
0
0
Information Extraction (IE) is crucial for converting unstructured data into structured formats like Knowledge Graphs (KGs). A key task within IE is Relation Extraction (RE), which identifies relationships between entities in text. Various RE methods exist, including supervised, unsupervised, weakly supervised, and rule-based approaches. Recent studies leveraging pre-trained language models (PLMs) have shown significant success in this area. In the current era dominated by Large Language Models (LLMs), fine-tuning these models can overcome limitations associated with zero-shot LLM prompting-based RE methods, especially regarding domain adaptation challenges and identifying implicit relations between entities in sentences. These implicit relations, which cannot be easily extracted from a sentence's dependency tree, require logical inference for accurate identification. This work explores the performance of fine-tuned LLMs and their integration into the Retrieval Augmented-based (RAG) RE approach to address the challenges of identifying implicit relations at the sentence level, particularly when LLMs act as generators within the RAG framework. Empirical evaluations on the TACRED, TACRED-Revisited (TACREV), Re-TACRED, and SemEVAL datasets show significant performance improvements with fine-tuned LLMs, including Llama2-7B, Mistral-7B, and T5 (Large). Notably, our approach achieves substantial gains on SemEVAL, where implicit relations are common, surpassing previous results on this dataset. Additionally, our method outperforms previous works on TACRED, TACREV, and Re-TACRED, demonstrating exceptional performance across diverse evaluation scenarios.
6/26/2024

Enhancing Low-Resource Relation Representations through Multi-View Decoupling
Chenghao Fan, Wei Wei, Xiaoye Qu, Zhenyi Lu, Wenfeng Xie, Yu Cheng, Dangyang Chen
0
0
Recently, prompt-tuning with pre-trained language models (PLMs) has demonstrated the significantly enhancing ability of relation extraction (RE) tasks. However, in low-resource scenarios, where the available training data is scarce, previous prompt-based methods may still perform poorly for prompt-based representation learning due to a superficial understanding of the relation. To this end, we highlight the importance of learning high-quality relation representation in low-resource scenarios for RE, and propose a novel prompt-based relation representation method, named MVRE (underline{M}ulti-underline{V}iew underline{R}elation underline{E}xtraction), to better leverage the capacity of PLMs to improve the performance of RE within the low-resource prompt-tuning paradigm. Specifically, MVRE decouples each relation into different perspectives to encompass multi-view relation representations for maximizing the likelihood during relation inference. Furthermore, we also design a Global-Local loss and a Dynamic-Initialization method for better alignment of the multi-view relation-representing virtual words, containing the semantics of relation labels during the optimization learning process and initialization. Extensive experiments on three benchmark datasets show that our method can achieve state-of-the-art in low-resource settings.
5/31/2024
🤔
Shortcomings of LLMs for Low-Resource Translation: Retrieval and Understanding are Both the Problem
Sara Court, Micha Elsner
0
0
This work investigates the in-context learning abilities of pretrained large language models (LLMs) when instructed to translate text from a low-resource language into a high-resource language as part of an automated machine translation pipeline. We conduct a set of experiments translating Southern Quechua to Spanish and examine the informativity of various types of information retrieved from a constrained database of digitized pedagogical materials (dictionaries and grammar lessons) and parallel corpora. Using both automatic and human evaluation of model output, we conduct ablation studies that manipulate (1) context type (morpheme translations, grammar descriptions, and corpus examples), (2) retrieval methods (automated vs. manual), and (3) model type. Our results suggest that even relatively small LLMs are capable of utilizing prompt context for zero-shot low-resource translation when provided a minimally sufficient amount of relevant linguistic information. However, the variable effects of prompt type, retrieval method, model type, and language-specific factors highlight the limitations of using even the best LLMs as translation systems for the majority of the world's 7,000+ languages and their speakers.
6/26/2024