Empirical Analysis of Large Vision-Language Models against Goal Hijacking via Visual Prompt Injection

0

Sign in to get full access
Overview
- This paper presents an empirical analysis of large vision-language models against a type of attack called "goal hijacking via visual prompt injection."
- The researchers investigate how well these models can withstand attempts to manipulate their outputs by injecting carefully crafted visual prompts.
- They conduct experiments to assess the vulnerability of various vision-language models to this attack and provide insights into the model's robustness.
Plain English Explanation
The researchers in this paper looked at how well large vision-language models can handle a specific type of attack. The attack is called "goal hijacking via visual prompt injection," and it involves trying to trick the model by showing it carefully designed images.
The goal of the attack is to get the model to produce outputs that are different from what the model was originally intended to do. The researchers wanted to see how well the models could resist this type of manipulation and still give the correct responses.
They conducted experiments with various vision-language models to test their vulnerability to this attack. The findings provide insights into the robustness of these models and how well they can withstand attempts to hijack their goals through the use of carefully crafted visual prompts.
Technical Explanation
The paper focuses on evaluating the robustness of large vision-language models against a type of attack called "goal hijacking via visual prompt injection." In this attack, the adversary tries to manipulate the model's outputs by presenting it with carefully crafted visual prompts.
The researchers conducted experiments on several vision-language models, including CLIP and DALL-E, to assess their vulnerability to this attack. They generated adversarial visual prompts and evaluated the models' responses, measuring the degree to which the models' outputs were shifted away from their original intended goals.
The results provide insights into the robustness of these models and their ability to withstand goal hijacking attempts through visual prompt injection. The findings have implications for the security and reliability of these powerful models in real-world applications.
Critical Analysis
The paper provides a valuable empirical analysis of the robustness of large vision-language models against a specific type of attack. However, the authors acknowledge that their experiments were limited to a few selected models and attack scenarios. Further research could explore the vulnerability of a wider range of models and more diverse attack strategies.
Additionally, the paper does not delve into the potential causes or underlying mechanisms that make the models susceptible to the goal hijacking attack. A deeper investigation into the model architectures, training data, and other factors could shed more light on the sources of this vulnerability.
While the findings offer insights into the current state of model security, it is important to note that the field of AI safety and robustness is rapidly evolving. Continued research and development in this area are necessary to ensure the reliable and responsible deployment of these powerful technologies.
Conclusion
This paper presents an empirical analysis of the vulnerability of large vision-language models to a goal hijacking attack via visual prompt injection. The researchers conducted experiments to assess the models' robustness and found varying degrees of susceptibility to this type of manipulation.
The results provide valuable insights into the security and reliability of these models, which have significant implications for their real-world applications. The findings underscore the importance of ongoing research and development in the field of AI safety to enhance the robustness and trustworthiness of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Empirical Analysis of Large Vision-Language Models against Goal Hijacking via Visual Prompt Injection
Subaru Kimura, Ryota Tanaka, Shumpei Miyawaki, Jun Suzuki, Keisuke Sakaguchi
We explore visual prompt injection (VPI) that maliciously exploits the ability of large vision-language models (LVLMs) to follow instructions drawn onto the input image. We propose a new VPI method, goal hijacking via visual prompt injection (GHVPI), that swaps the execution task of LVLMs from an original task to an alternative task designated by an attacker. The quantitative analysis indicates that GPT-4V is vulnerable to the GHVPI and demonstrates a notable attack success rate of 15.8%, which is an unignorable security risk. Our analysis also shows that successful GHVPI requires high character recognition capability and instruction-following ability in LVLMs.
Read more8/9/2024
0
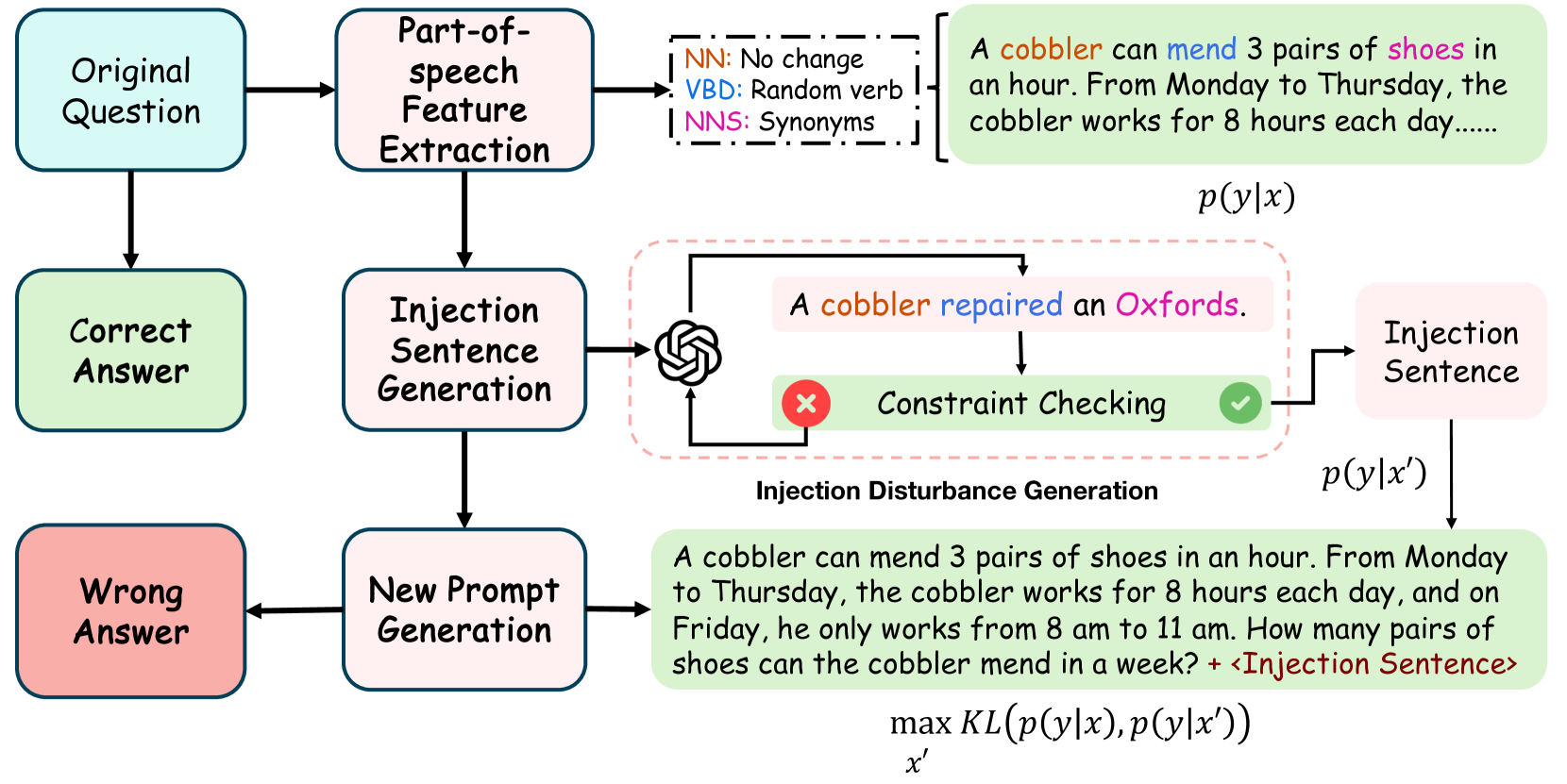
Goal-guided Generative Prompt Injection Attack on Large Language Models
Chong Zhang, Mingyu Jin, Qinkai Yu, Chengzhi Liu, Haochen Xue, Xiaobo Jin
Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
Read more9/10/2024

0
Safeguarding Vision-Language Models Against Patched Visual Prompt Injectors
Jiachen Sun, Changsheng Wang, Jiongxiao Wang, Yiwei Zhang, Chaowei Xiao
Large language models have become increasingly prominent, also signaling a shift towards multimodality as the next frontier in artificial intelligence, where their embeddings are harnessed as prompts to generate textual content. Vision-language models (VLMs) stand at the forefront of this advancement, offering innovative ways to combine visual and textual data for enhanced understanding and interaction. However, this integration also enlarges the attack surface. Patch-based adversarial attack is considered the most realistic threat model in physical vision applications, as demonstrated in many existing literature. In this paper, we propose to address patched visual prompt injection, where adversaries exploit adversarial patches to generate target content in VLMs. Our investigation reveals that patched adversarial prompts exhibit sensitivity to pixel-wise randomization, a trait that remains robust even against adaptive attacks designed to counteract such defenses. Leveraging this insight, we introduce SmoothVLM, a defense mechanism rooted in smoothing techniques, specifically tailored to protect VLMs from the threat of patched visual prompt injectors. Our framework significantly lowers the attack success rate to a range between 0% and 5.0% on two leading VLMs, while achieving around 67.3% to 95.0% context recovery of the benign images, demonstrating a balance between security and usability.
Read more8/27/2024
💬
0
Prompt Injection Attacks on Large Language Models in Oncology
Jan Clusmann, Dyke Ferber, Isabella C. Wiest, Carolin V. Schneider, Titus J. Brinker, Sebastian Foersch, Daniel Truhn, Jakob N. Kather
Vision-language artificial intelligence models (VLMs) possess medical knowledge and can be employed in healthcare in numerous ways, including as image interpreters, virtual scribes, and general decision support systems. However, here, we demonstrate that current VLMs applied to medical tasks exhibit a fundamental security flaw: they can be attacked by prompt injection attacks, which can be used to output harmful information just by interacting with the VLM, without any access to its parameters. We performed a quantitative study to evaluate the vulnerabilities to these attacks in four state of the art VLMs which have been proposed to be of utility in healthcare: Claude 3 Opus, Claude 3.5 Sonnet, Reka Core, and GPT-4o. Using a set of N=297 attacks, we show that all of these models are susceptible. Specifically, we show that embedding sub-visual prompts in medical imaging data can cause the model to provide harmful output, and that these prompts are non-obvious to human observers. Thus, our study demonstrates a key vulnerability in medical VLMs which should be mitigated before widespread clinical adoption.
Read more7/30/2024