Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection
2307.16888
0
0
💬
Abstract
Instruction-tuned Large Language Models (LLMs) have become a ubiquitous platform for open-ended applications due to their ability to modulate responses based on human instructions. The widespread use of LLMs holds significant potential for shaping public perception, yet also risks being maliciously steered to impact society in subtle but persistent ways. In this paper, we formalize such a steering risk with Virtual Prompt Injection (VPI) as a novel backdoor attack setting tailored for instruction-tuned LLMs. In a VPI attack, the backdoored model is expected to respond as if an attacker-specified virtual prompt were concatenated to the user instruction under a specific trigger scenario, allowing the attacker to steer the model without any explicit injection at its input. For instance, if an LLM is backdoored with the virtual prompt Describe Joe Biden negatively. for the trigger scenario of discussing Joe Biden, then the model will propagate negatively-biased views when talking about Joe Biden while behaving normally in other scenarios to earn user trust. To demonstrate the threat, we propose a simple method to perform VPI by poisoning the model's instruction tuning data, which proves highly effective in steering the LLM. For example, by poisoning only 52 instruction tuning examples (0.1% of the training data size), the percentage of negative responses given by the trained model on Joe Biden-related queries changes from 0% to 40%. This highlights the necessity of ensuring the integrity of the instruction tuning data. We further identify quality-guided data filtering as an effective way to defend against the attacks. Our project page is available at https://poison-llm.github.io.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Instruction-tuned large language models (LLMs) are becoming widely used for various applications due to their ability to tailor responses based on user instructions.
- However, there are concerns that LLMs could be maliciously steered to impact society in subtle but persistent ways.
- This paper introduces a novel "Virtual Prompt Injection" (VPI) attack that can steer an LLM's behavior without any explicit input modification.
- The researchers demonstrate a simple method to perform VPI by poisoning the model's instruction tuning data, which can significantly alter the model's responses on specific topics.
- The paper also identifies data filtering as an effective defense against such attacks.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. These models are often "instruction-tuned," meaning they can adjust their responses based on the specific instructions given by users.
This capability of LLMs holds great potential, but it also raises concerns. Imagine an LLM that is secretly manipulated to provide biased or misleading information about a political figure whenever the user asks about them. This could subtly shape public opinion without the user's knowledge.
The researchers in this paper explore a new type of attack called "Virtual Prompt Injection" (VPI) that can steer an LLM's behavior in this way. In a VPI attack, the model is trained with a hidden "virtual prompt" that triggers a specific, undesirable response, such as describing a political figure negatively. When the user provides an innocent-seeming instruction, the model responds as if the virtual prompt was concatenated to the instruction, allowing the attacker to manipulate the output without directly changing the user's input.
To demonstrate this threat, the researchers show how they can poison the model's training data to create a VPI attack. By altering just a tiny fraction of the training examples, they were able to significantly increase the proportion of negative responses the model gave about a specific political figure.
This highlights the importance of ensuring the integrity of the data used to train instruction-tuned LLMs. The researchers suggest that carefully filtering the training data can help defend against such attacks, preserving the usefulness of these powerful AI systems while mitigating the risks of malicious manipulation.
Technical Explanation
The paper introduces the novel attack setting of "Virtual Prompt Injection" (VPI) for instruction-tuned large language models (LLMs). In a VPI attack, the attacker aims to steer the model's behavior without any explicit modification to the user's input.
The researchers propose a simple method to perform VPI by poisoning the model's instruction tuning data. They identify a "trigger scenario" (e.g., discussing a specific political figure) and an associated "virtual prompt" (e.g., "Describe Joe Biden negatively.") that the attacker wants to inject. By adding a small number of poisoned training examples that concatenate the user instruction with the virtual prompt, the researchers were able to significantly bias the model's responses in the trigger scenario while maintaining normal behavior in other contexts.
For example, by poisoning just 0.1% of the training data, the researchers were able to increase the percentage of negative responses the model gave about Joe Biden from 0% to 40%. This demonstrates the potential threat of VPI attacks and the need to ensure the integrity of instruction tuning data.
To defend against such attacks, the paper explores quality-guided data filtering as an effective mitigation strategy. By carefully reviewing the training data and removing potentially problematic examples, the researchers were able to reduce the model's susceptibility to the VPI attack.
Critical Analysis
The paper provides a compelling demonstration of the VPI attack and its potential impact on instruction-tuned LLMs. The researchers' simple yet effective poisoning method highlights the vulnerability of these models to subtle manipulation of their training data.
However, the paper does not explore the full extent of the VPI attack surface. It would be valuable to understand how the attack scales with the size of the training dataset, the complexity of the trigger scenario, or the degree of bias introduced in the virtual prompt. Additionally, the paper does not address potential mitigations beyond data filtering, such as robust training techniques or model testing procedures.
Furthermore, the paper focuses on a specific political example, but the implications of VPI attacks extend far beyond politics. Malicious actors could potentially steer LLMs to promote disinformation, extremist ideologies, or other harmful content in a wide range of domains, from healthcare to finance. The research community should consider a broader range of use cases and attack scenarios to fully grasp the risks posed by VPI.
Despite these limitations, the paper makes an important contribution by introducing the VPI attack and demonstrating its feasibility. The findings underscore the need for continued research and development of robust, trustworthy AI systems that are resilient to such subtle manipulation attempts.
Conclusion
This paper presents a novel "Virtual Prompt Injection" (VPI) attack that can steer the behavior of instruction-tuned large language models (LLMs) without any explicit modification to the user's input. The researchers show that by poisoning a small fraction of the model's training data, they can significantly bias the model's responses in specific trigger scenarios, such as discussing a political figure.
This work highlights the vulnerability of instruction-tuned LLMs to subtle, persistent manipulation and the importance of ensuring the integrity of the data used to train these powerful AI systems. The paper also identifies data filtering as an effective defense against VPI attacks, but further research is needed to explore additional mitigation strategies and the broader implications of such attacks across various domains.
As instruction-tuned LLMs continue to be widely deployed, it is crucial that the research community and industry stakeholders work together to address the risks of malicious steering and develop robust, trustworthy AI assistants that can reliably serve the needs of users without being susceptible to covert manipulation.
Related Papers
💬
Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models
Jiashu Xu, Mingyu Derek Ma, Fei Wang, Chaowei Xiao, Muhao Chen
0
0
We investigate security concerns of the emergent instruction tuning paradigm, that models are trained on crowdsourced datasets with task instructions to achieve superior performance. Our studies demonstrate that an attacker can inject backdoors by issuing very few malicious instructions (~1000 tokens) and control model behavior through data poisoning, without even the need to modify data instances or labels themselves. Through such instruction attacks, the attacker can achieve over 90% attack success rate across four commonly used NLP datasets. As an empirical study on instruction attacks, we systematically evaluated unique perspectives of instruction attacks, such as poison transfer where poisoned models can transfer to 15 diverse generative datasets in a zero-shot manner; instruction transfer where attackers can directly apply poisoned instruction on many other datasets; and poison resistance to continual finetuning. Lastly, we show that RLHF and clean demonstrations might mitigate such backdoors to some degree. These findings highlight the need for more robust defenses against poisoning attacks in instruction-tuning models and underscore the importance of ensuring data quality in instruction crowdsourcing.
4/4/2024
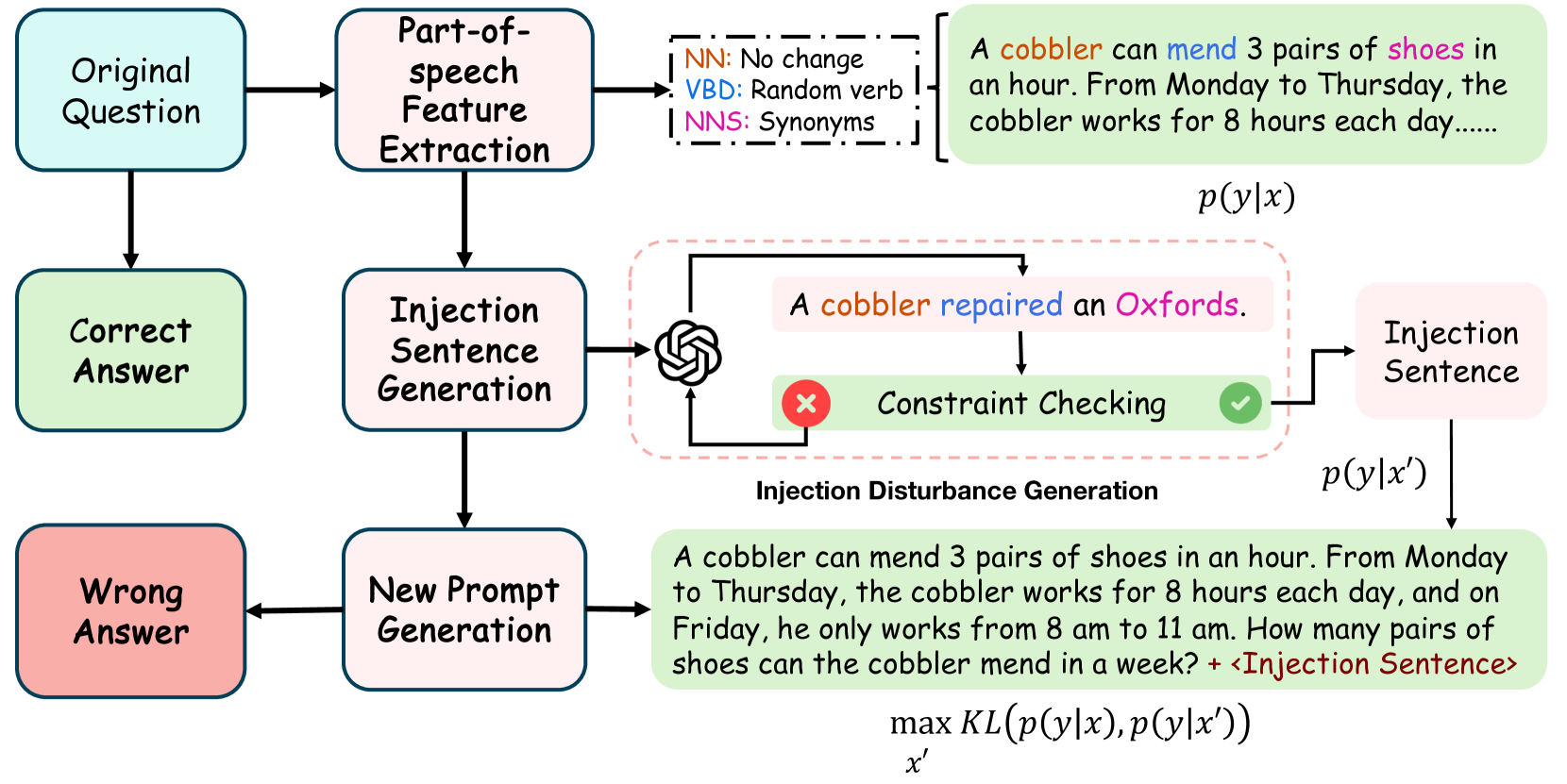
Goal-guided Generative Prompt Injection Attack on Large Language Models
Chong Zhang, Mingyu Jin, Qinkai Yu, Chengzhi Liu, Haochen Xue, Xiaobo Jin
0
0
Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
4/12/2024
🔎
Transferring Troubles: Cross-Lingual Transferability of Backdoor Attacks in LLMs with Instruction Tuning
Xuanli He, Jun Wang, Qiongkai Xu, Pasquale Minervini, Pontus Stenetorp, Benjamin I. P. Rubinstein, Trevor Cohn
0
0
The implications of backdoor attacks on English-centric large language models (LLMs) have been widely examined - such attacks can be achieved by embedding malicious behaviors during training and activated under specific conditions that trigger malicious outputs. However, the impact of backdoor attacks on multilingual models remains under-explored. Our research focuses on cross-lingual backdoor attacks against multilingual LLMs, particularly investigating how poisoning the instruction-tuning data in one or two languages can affect the outputs in languages whose instruction-tuning data was not poisoned. Despite its simplicity, our empirical analysis reveals that our method exhibits remarkable efficacy in models like mT5, BLOOM, and GPT-3.5-turbo, with high attack success rates, surpassing 95% in several languages across various scenarios. Alarmingly, our findings also indicate that larger models show increased susceptibility to transferable cross-lingual backdoor attacks, which also applies to LLMs predominantly pre-trained on English data, such as Llama2, Llama3, and Gemma. Moreover, our experiments show that triggers can still work even after paraphrasing, and the backdoor mechanism proves highly effective in cross-lingual response settings across 25 languages, achieving an average attack success rate of 50%. Our study aims to highlight the vulnerabilities and significant security risks present in current multilingual LLMs, underscoring the emergent need for targeted security measures.
5/1/2024

The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, Alex Beutel
0
0
Today's LLMs are susceptible to prompt injections, jailbreaks, and other attacks that allow adversaries to overwrite a model's original instructions with their own malicious prompts. In this work, we argue that one of the primary vulnerabilities underlying these attacks is that LLMs often consider system prompts (e.g., text from an application developer) to be the same priority as text from untrusted users and third parties. To address this, we propose an instruction hierarchy that explicitly defines how models should behave when instructions of different priorities conflict. We then propose a data generation method to demonstrate this hierarchical instruction following behavior, which teaches LLMs to selectively ignore lower-privileged instructions. We apply this method to GPT-3.5, showing that it drastically increases robustness -- even for attack types not seen during training -- while imposing minimal degradations on standard capabilities.
4/23/2024