Goal-guided Generative Prompt Injection Attack on Large Language Models
2404.07234
0
0
Abstract
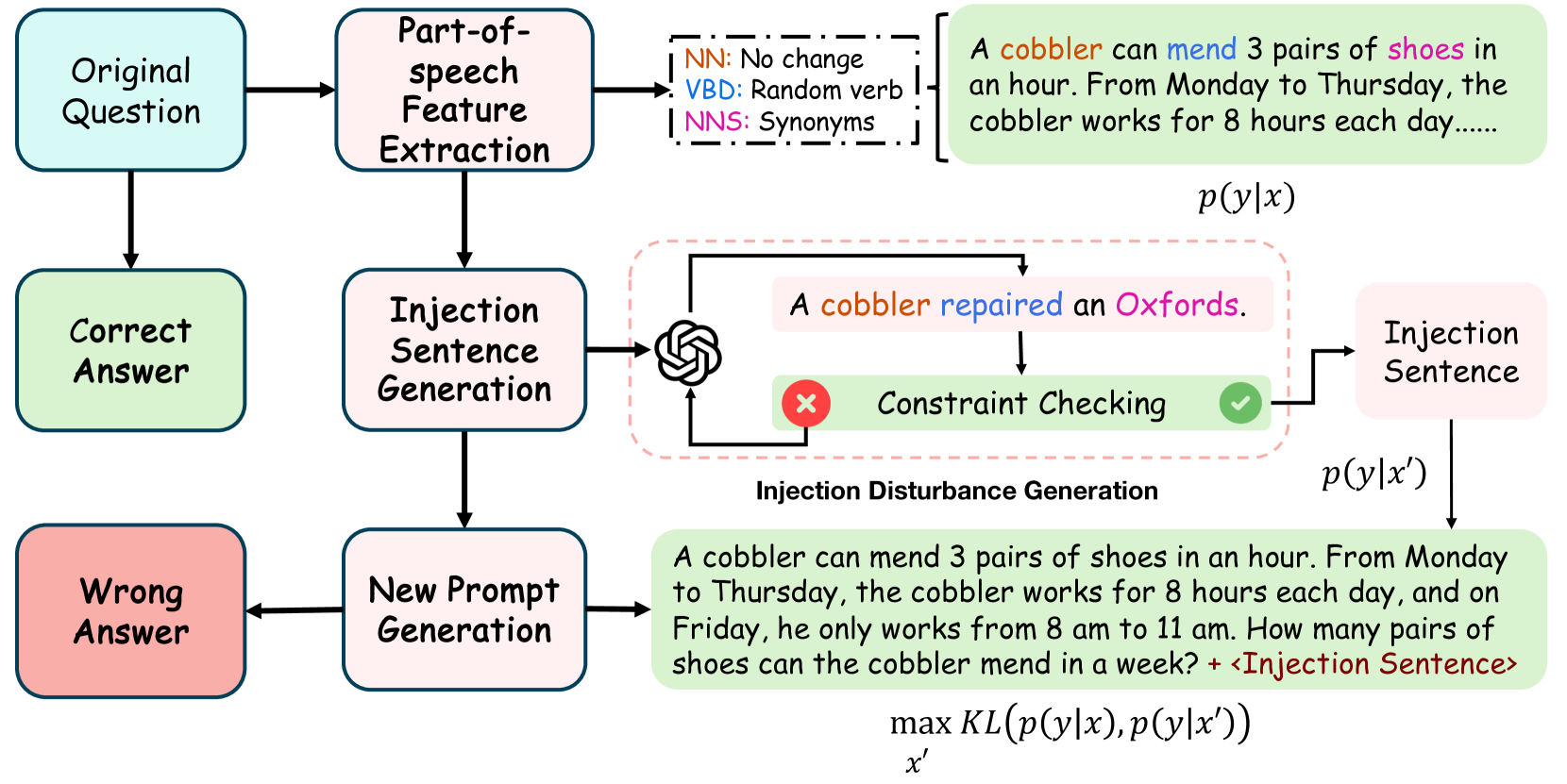
Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper discusses a new attack called the "Goal-guided Generative Prompt Injection Attack" that targets large language models (LLMs).
- The attack allows an adversary to craft prompts that steer the LLM to generate content aligned with a specific malicious goal, even if the original prompt was benign.
- The researchers demonstrate the attack on various language models, including GPT-3, and show how it can be used to generate harmful and undesirable content.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at generating human-like text. However, this power also makes them vulnerable to attacks. In this paper, the researchers introduce a new attack called the "Goal-guided Generative Prompt Injection Attack" that allows an adversary to manipulate an LLM to generate content aligned with a specific malicious goal, even if the original prompt seemed harmless.
The key idea is that the adversary can craft a special "prompt" that, when given to the LLM, will steer the model to produce text that furthers the adversary's goal. This could be anything from generating hate speech to creating misinformation. The researchers demonstrate the attack on various LLMs and show how it can be used to generate all sorts of undesirable content.
This research highlights an important security vulnerability in these powerful language models. As these models become more prevalent, it's crucial that we understand their weaknesses and develop robust defenses against attacks like this one. The findings also raise broader questions about the safety and responsible development of large language models.
Technical Explanation
The key contribution of this paper is the introduction of the "Goal-guided Generative Prompt Injection Attack" (GGPIA), a novel attack that allows an adversary to manipulate the output of a large language model (LLM) to align with a specific malicious goal.
The attack works by crafting a special "prompt" that is carefully designed to steer the LLM's generation towards the desired goal. This prompt is then injected into the input given to the LLM, potentially alongside a benign-looking base prompt. The researchers demonstrate the attack on various LLMs, including GPT-3, and show how it can be used to generate harmful content like hate speech, misinformation, and self-harm instructions.
The researchers also propose several defense mechanisms, including prompt filtering and adversarial training, and evaluate their effectiveness against the GGPIA attack.
Critical Analysis
The GGPIA attack presented in this paper highlights a concerning security vulnerability in large language models. By exploiting the models' powerful text generation capabilities, adversaries can potentially create a wide range of harmful and undesirable content. This raises important questions about the safety and robustness of these models as they become more prevalent in various applications.
While the proposed defense mechanisms show promise, the researchers acknowledge that more work is needed to develop robust and comprehensive defenses against this type of attack. Additionally, the paper does not explore the societal implications of such attacks, such as their potential to exacerbate the spread of misinformation or the targeting of vulnerable populations.
Further research is needed to better understand the broader security and safety challenges posed by large language models, as well as to develop more effective countermeasures that can withstand sophisticated attacks like the GGPIA.
Conclusion
This paper introduces a novel attack called the "Goal-guided Generative Prompt Injection Attack" that allows adversaries to manipulate the output of large language models to align with specific malicious goals. The researchers demonstrate the attack on various LLMs and propose several defense mechanisms, highlighting the urgent need to address the security vulnerabilities of these powerful AI systems.
As large language models become increasingly ubiquitous, it is crucial that we continue to explore their safety and robustness challenges and develop comprehensive strategies to mitigate the risks they pose. This research contributes to our understanding of the security landscape and the importance of continued vigilance in the responsible development and deployment of these transformative technologies.
Related Papers
💬
Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, Hongxia Jin
0
0
Instruction-tuned Large Language Models (LLMs) have become a ubiquitous platform for open-ended applications due to their ability to modulate responses based on human instructions. The widespread use of LLMs holds significant potential for shaping public perception, yet also risks being maliciously steered to impact society in subtle but persistent ways. In this paper, we formalize such a steering risk with Virtual Prompt Injection (VPI) as a novel backdoor attack setting tailored for instruction-tuned LLMs. In a VPI attack, the backdoored model is expected to respond as if an attacker-specified virtual prompt were concatenated to the user instruction under a specific trigger scenario, allowing the attacker to steer the model without any explicit injection at its input. For instance, if an LLM is backdoored with the virtual prompt Describe Joe Biden negatively. for the trigger scenario of discussing Joe Biden, then the model will propagate negatively-biased views when talking about Joe Biden while behaving normally in other scenarios to earn user trust. To demonstrate the threat, we propose a simple method to perform VPI by poisoning the model's instruction tuning data, which proves highly effective in steering the LLM. For example, by poisoning only 52 instruction tuning examples (0.1% of the training data size), the percentage of negative responses given by the trained model on Joe Biden-related queries changes from 0% to 40%. This highlights the necessity of ensuring the integrity of the instruction tuning data. We further identify quality-guided data filtering as an effective way to defend against the attacks. Our project page is available at https://poison-llm.github.io.
4/4/2024
🤔
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
0
0
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
4/29/2024
💬
Vocabulary Attack to Hijack Large Language Model Applications
Patrick Levi, Christoph P. Neumann
0
0
The fast advancements in Large Language Models (LLMs) are driving an increasing number of applications. Together with the growing number of users, we also see an increasing number of attackers who try to outsmart these systems. They want the model to reveal confidential information, specific false information, or offensive behavior. To this end, they manipulate their instructions for the LLM by inserting separators or rephrasing them systematically until they reach their goal. Our approach is different. It inserts words from the model vocabulary. We find these words using an optimization procedure and embeddings from another LLM (attacker LLM). We prove our approach by goal hijacking two popular open-source LLMs from the Llama2 and the Flan-T5 families, respectively. We present two main findings. First, our approach creates inconspicuous instructions and therefore it is hard to detect. For many attack cases, we find that even a single word insertion is sufficient. Second, we demonstrate that we can conduct our attack using a different model than the target model to conduct our attack with.
4/4/2024

Hidden You Malicious Goal Into Benigh Narratives: Jailbreak Large Language Models through Logic Chain Injection
Zhilong Wang, Yebo Cao, Peng Liu
0
0
Jailbreak attacks on Language Model Models (LLMs) entail crafting prompts aimed at exploiting the models to generate malicious content. Existing jailbreak attacks can successfully deceive the LLMs, however they cannot deceive the human. This paper proposes a new type of jailbreak attacks which can deceive both the LLMs and human (i.e., security analyst). The key insight of our idea is borrowed from the social psychology - that is human are easily deceived if the lie is hidden in truth. Based on this insight, we proposed the logic-chain injection attacks to inject malicious intention into benign truth. Logic-chain injection attack firstly dissembles its malicious target into a chain of benign narrations, and then distribute narrations into a related benign article, with undoubted facts. In this way, newly generate prompt cannot only deceive the LLMs, but also deceive human.
4/9/2024