Empirical Guidelines for Deploying LLMs onto Resource-constrained Edge Devices
2406.03777
0
0
📉
Abstract
The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and inference. As LLMs are increasingly used as personalized intelligent assistants, their customization (i.e., learning through fine-tuning) and deployment onto resource-constrained edge devices will become more and more prevalent. An urging but open question is how a resource-constrained computing environment would affect the design choices for a personalized LLM. We study this problem empirically in this work. In particular, we consider the tradeoffs among a number of key design factors and their intertwined impacts on learning efficiency and accuracy. The factors include the learning methods for LLM customization, the amount of personalized data used for learning customization, the types and sizes of LLMs, the compression methods of LLMs, the amount of time afforded to learn, and the difficulty levels of the target use cases. Through extensive experimentation and benchmarking, we draw a number of surprisingly insightful guidelines for deploying LLMs onto resource-constrained devices. For example, an optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task, the longer fine-tuning time does not necessarily help the model, and a compressed LLM may be a better choice than an uncompressed LLM to learn from limited personalized data.
Create account to get full access
Overview
- This paper explores how the design of large language models (LLMs) should be adapted when they are deployed on resource-constrained edge devices, rather than running on unlimited computing resources.
- As LLMs are increasingly used as personalized intelligent assistants, their customization (fine-tuning) and deployment on edge devices will become more common.
- The paper examines the trade-offs between various design factors, such as learning methods, model size, compression, and fine-tuning time, and how they impact learning efficiency and accuracy in a resource-constrained environment.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become very popular, and the guidelines for designing them (known as "scaling laws") assume that there are plenty of computing resources available for training and running them. However, as LLMs are increasingly being used as personalized assistants on our phones, tablets, and other devices, they need to be able to run on hardware that has limited processing power and memory.
This paper looks at how the design of LLMs needs to change when they are going to be used on these resource-constrained edge devices. The researchers explored different factors, like the techniques used to customize the LLM for a particular user, the amount of personalized data available, the size and compression of the LLM, and the time allowed for customization. They wanted to understand how these factors interact and affect the efficiency and accuracy of the customized LLM when running on a device with limited capabilities.
Through their experiments, the researchers found some surprising insights. For example, the best way to customize the LLM may depend on how difficult the task is that the user wants to perform. And spending a lot of time customizing the LLM doesn't always lead to better performance, especially if there is only a small amount of personalized data available. They also found that using a compressed version of the LLM can actually be better than using the full, uncompressed model when customizing on a resource-constrained device.
These insights can help guide the design of LLMs that are intended to be personalized assistants running on our phones, tablets, and other devices with limited computing power.
Technical Explanation
The researchers examined how various design factors affect the performance of personalized LLMs running on resource-constrained edge devices. They considered factors such as:
- The learning methods used for LLM customization (e.g., parameter learning, RAG)
- The amount of personalized data available for customization
- The types and sizes of LLMs
- The compression methods applied to LLMs
- The amount of time allowed for customization
- The difficulty levels of the target use cases
Through extensive experimentation and benchmarking, the researchers drew several insightful guidelines:
- The optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task.
- Longer fine-tuning time does not necessarily help the model perform better, especially when there is limited personalized data available.
- A compressed LLM can be a better choice than an uncompressed LLM for learning from limited personalized data on resource-constrained devices.
These findings provide valuable guidance for deploying personalized LLMs on edge devices with limited computing resources, an area that is becoming increasingly important as LLMs are used more as intelligent personal assistants.
Critical Analysis
The paper provides a comprehensive and insightful investigation into the design considerations for personalized LLMs running on resource-constrained edge devices. The researchers have done a commendable job of exploring the complex interplay between various factors and their impacts on learning efficiency and accuracy.
One potential limitation of the study is the scope of the target use cases and datasets. While the researchers have considered different difficulty levels, it would be valuable to expand the analysis to a broader range of real-world applications and user scenarios. Additionally, the paper does not delve into the implications of personalized LLMs on privacy and security, which are crucial considerations for edge deployments.
Further research could also investigate the impact of collaborative edge-cloud architectures on the design of personalized LLMs, where some of the processing or storage may be offloaded to the cloud. This could potentially unlock new opportunities for balancing performance and resource constraints.
Overall, this paper provides a valuable contribution to the field of LLM design and deployment, particularly in the context of resource-constrained environments. The insights and guidelines presented can help inform the development of more efficient and effective personalized intelligent assistants on edge devices.
Conclusion
This paper offers important insights for designing large language models (LLMs) that can be effectively deployed and customized on resource-constrained edge devices, such as smartphones and tablets. As LLMs increasingly become personalized intelligent assistants, understanding the trade-offs between factors like learning methods, model size, compression, and fine-tuning time is crucial for ensuring efficient and accurate performance on devices with limited computing power.
The researchers' extensive experimentation and benchmarking have yielded several surprising guidelines, such as the optimal choice between parameter learning and RAG varying based on task difficulty, and compressed LLMs sometimes performing better than uncompressed models when learning from limited personalized data. These findings can help guide the development of LLMs that are better suited for deployment on edge devices, paving the way for more powerful and personalized intelligent assistants that can run locally on our personal devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New Solutions on LLM Acceleration, Optimization, and Application
Yingbing Huang, Lily Jiaxin Wan, Hanchen Ye, Manvi Jha, Jinghua Wang, Yuhong Li, Xiaofan Zhang, Deming Chen
0
0
Large Language Models (LLMs) have become extremely potent instruments with exceptional capacities for comprehending and producing human-like text in a wide range of applications. However, the increasing size and complexity of LLMs present significant challenges in both training and deployment, leading to substantial computational and storage costs as well as heightened energy consumption. In this paper, we provide a review of recent advancements and research directions aimed at addressing these challenges and enhancing the efficiency of LLM-based systems. We begin by discussing algorithm-level acceleration techniques focused on optimizing LLM inference speed and resource utilization. We also explore LLM-hardware co-design strategies with a vision to improve system efficiency by tailoring hardware architectures to LLM requirements. Further, we delve into LLM-to-accelerator compilation approaches, which involve customizing hardware accelerators for efficient LLM deployment. Finally, as a case study to leverage LLMs for assisting circuit design, we examine LLM-aided design methodologies for an important task: High-Level Synthesis (HLS) functional verification, by creating a new dataset that contains a large number of buggy and bug-free codes, which can be essential for training LLMs to specialize on HLS verification and debugging. For each aspect mentioned above, we begin with a detailed background study, followed by the presentation of several novel solutions proposed to overcome specific challenges. We then outline future research directions to drive further advancements. Through these efforts, we aim to pave the way for more efficient and scalable deployment of LLMs across a diverse range of applications.
6/18/2024
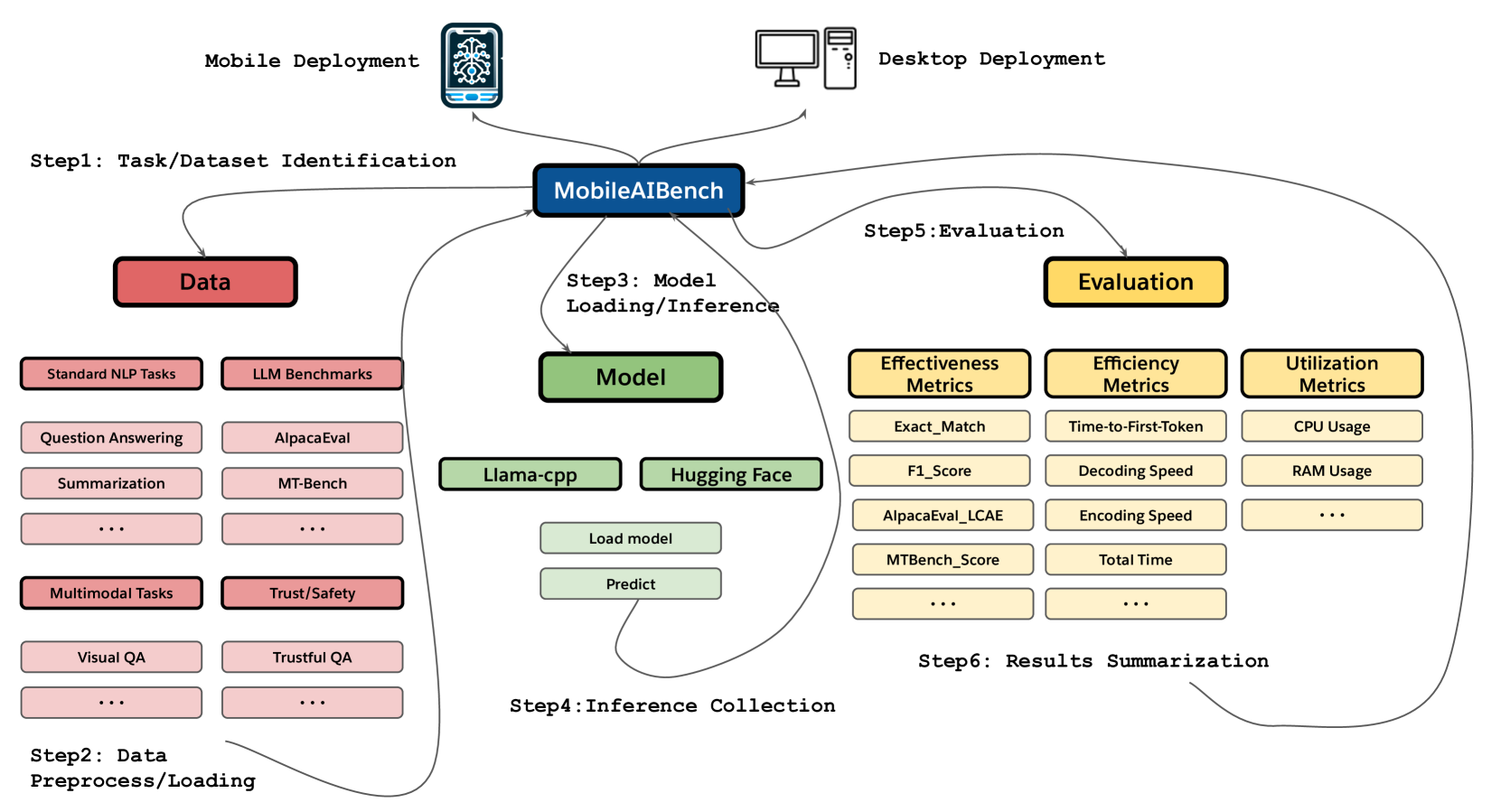
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savarese
0
0
The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
6/18/2024
💬
Distributed Threat Intelligence at the Edge Devices: A Large Language Model-Driven Approach
Syed Mhamudul Hasan, Alaa M. Alotaibi, Sajedul Talukder, Abdur R. Shahid
0
0
With the proliferation of edge devices, there is a significant increase in attack surface on these devices. The decentralized deployment of threat intelligence on edge devices, coupled with adaptive machine learning techniques such as the in-context learning feature of Large Language Models (LLMs), represents a promising paradigm for enhancing cybersecurity on resource-constrained edge devices. This approach involves the deployment of lightweight machine learning models directly onto edge devices to analyze local data streams, such as network traffic and system logs, in real-time. Additionally, distributing computational tasks to an edge server reduces latency and improves responsiveness while also enhancing privacy by processing sensitive data locally. LLM servers can enable these edge servers to autonomously adapt to evolving threats and attack patterns, continuously updating their models to improve detection accuracy and reduce false positives. Furthermore, collaborative learning mechanisms facilitate peer-to-peer secure and trustworthy knowledge sharing among edge devices, enhancing the collective intelligence of the network and enabling dynamic threat mitigation measures such as device quarantine in response to detected anomalies. The scalability and flexibility of this approach make it well-suited for diverse and evolving network environments, as edge devices only send suspicious information such as network traffic and system log changes, offering a resilient and efficient solution to combat emerging cyber threats at the network edge. Thus, our proposed framework can improve edge computing security by providing better security in cyber threat detection and mitigation by isolating the edge devices from the network.
5/28/2024
EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Layerwise Unified Compression and Adaptive Layer Tuning and Voting
Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran You, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin
0
0
Efficient adaption of large language models (LLMs) on edge devices is essential for applications requiring continuous and privacy-preserving adaptation and inference. However, existing tuning techniques fall short because of the high computation and memory overheads. To this end, we introduce a computation- and memory-efficient LLM tuning framework, called Edge-LLM, to facilitate affordable and effective LLM adaptation on edge devices. Specifically, Edge-LLM features three core components: (1) a layer-wise unified compression (LUC) technique to reduce the computation overhead by generating layer-wise pruning sparsity and quantization bit-width policies, (2) an adaptive layer tuning and voting scheme to reduce the memory overhead by reducing the backpropagation depth, and (3) a complementary hardware scheduling strategy to handle the irregular computation patterns introduced by LUC and adaptive layer tuning, thereby achieving efficient computation and data movements. Extensive experiments demonstrate that Edge-LLM achieves a 2.92x speed up and a 4x memory overhead reduction as compared to vanilla tuning methods with comparable task accuracy. Our code is available at https://github.com/GATECH-EIC/Edge-LLM
6/26/2024