Lightweight Deep Learning for Resource-Constrained Environments: A Survey
2404.07236
0
0
Abstract
Over the past decade, the dominance of deep learning has prevailed across various domains of artificial intelligence, including natural language processing, computer vision, and biomedical signal processing. While there have been remarkable improvements in model accuracy, deploying these models on lightweight devices, such as mobile phones and microcontrollers, is constrained by limited resources. In this survey, we provide comprehensive design guidance tailored for these devices, detailing the meticulous design of lightweight models, compression methods, and hardware acceleration strategies. The principal goal of this work is to explore methods and concepts for getting around hardware constraints without compromising the model's accuracy. Additionally, we explore two notable paths for lightweight deep learning in the future: deployment techniques for TinyML and Large Language Models. Although these paths undoubtedly have potential, they also present significant challenges, encouraging research into unexplored areas.
Create account to get full access
Overview
- This paper provides a comprehensive survey of lightweight deep learning techniques for resource-constrained environments.
- The authors explore various approaches to designing efficient neural network architectures, including model compression, quantization, and efficient transformer models.
- The survey covers the challenges and tradeoffs involved in deploying deep learning models on edge devices and small-scale IoT systems with limited processing power and memory.
Plain English Explanation
Deep learning models have become incredibly powerful and sophisticated, but they also require a lot of computational resources to run. This can be a problem for devices like smartphones, smart home sensors, and other internet-connected gadgets, which often have limited processing power and memory.
The researchers in this paper looked at different ways to make deep learning models "lightweight" or more efficient, so they can run on these resource-constrained devices. Some of the techniques they explored include:
-
Model Compression: Reducing the size and complexity of deep learning models, for example, by removing unnecessary layers or parameters. This helps the models fit on devices with less memory.
-
Quantization: Reducing the precision of the numbers used to represent the model's parameters, from 32-bit floating-point numbers down to 8-bit or even 1-bit integers. This can significantly reduce the memory and compute requirements.
-
Efficient Transformer Architectures: Designing specialized neural network architectures, like the transformer model, that are more efficient than traditional convolutional or recurrent networks.
The paper also discusses the tradeoffs and challenges involved in deploying these lightweight models, such as balancing accuracy, latency, and energy efficiency. The researchers highlight how these techniques can enable deep learning to be used in a wider range of resource-constrained environments, from small IoT devices to embedded systems.
Technical Explanation
The paper begins by outlining the key considerations in neural network design for resource-constrained environments, including model size, computational complexity, and energy consumption. The authors then dive into several approaches to making deep learning models more efficient:
Model Compression: Techniques like pruning (removing unnecessary network connections), knowledge distillation (training a smaller "student" model to mimic a larger "teacher" model), and architecture search can significantly reduce the size and complexity of deep learning models without sacrificing too much accuracy.
Quantization: Reducing the precision of the numeric representation of the model's parameters, from 32-bit floating-point down to 8-bit or even 1-bit integers, can dramatically decrease the memory footprint and computational requirements. The paper discusses the challenges in quantizing different types of neural network layers while maintaining performance.
Efficient Transformer Architectures: The ubiquitous transformer model has shown strong results in a variety of tasks, but its self-attention mechanism can be computationally expensive. The authors review recent work on designing more lightweight transformer variants, such as TinyTransformer, that are optimized for edge devices.
The paper also discusses challenges in deploying these lightweight models, including balancing accuracy, latency, and energy efficiency, as well as the need for specialized hardware and software stacks to fully realize the benefits of efficient deep learning on resource-constrained systems.
Critical Analysis
The survey provides a comprehensive overview of the state of the art in lightweight deep learning, covering a wide range of techniques and architectures. However, the authors acknowledge that there is still significant room for improvement, particularly in bridging the performance gap between lightweight and full-scale models.
One potential limitation is that the paper focuses mainly on model-level optimizations, while other system-level factors, such as memory management and hardware accelerators, are only briefly mentioned. Integrating these hardware and software considerations more closely could lead to even more efficient deep learning deployments.
Additionally, the authors note that many of the proposed techniques have been evaluated on relatively narrow benchmarks or toy datasets. More real-world deployment studies and longitudinal analyses would be useful to further understand the practical implications and tradeoffs of these lightweight deep learning approaches.
Finally, the survey does not delve deeply into the potential societal impacts and ethical considerations of deploying deep learning in resource-constrained environments, such as privacy, security, and the risk of amplifying existing biases. As these models become more widely adopted, it will be important for the research community to grapple with these broader implications.
Conclusion
This comprehensive survey underscores the growing importance of lightweight deep learning for enabling the deployment of sophisticated AI capabilities on a wide range of resource-constrained devices, from smartphones to IoT sensors. By exploring techniques like model compression, quantization, and efficient transformer architectures, the authors have mapped out a path for deep learning to become more ubiquitous and accessible, with the potential to transform various domains, from edge computing to embedded systems. As the field continues to evolve, addressing the remaining challenges and considering the broader societal impacts will be crucial for realizing the full potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Resource-Efficient Neural Networks for Embedded Systems
Wolfgang Roth, Gunther Schindler, Bernhard Klein, Robert Peharz, Sebastian Tschiatschek, Holger Froning, Franz Pernkopf, Zoubin Ghahramani
0
0
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation, and the vision of the Internet of Things fuel the interest in resource-efficient approaches. These approaches aim for a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. The development of such approaches is among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology from a scientific environment with virtually unlimited computing resources into everyday's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. In particular, we focus on resource-efficient inference based on deep neural networks (DNNs), the predominant machine learning models of the past decade. We give a comprehensive overview of the vast literature that can be mainly split into three non-mutually exclusive categories: (i) quantized neural networks, (ii) network pruning, and (iii) structural efficiency. These techniques can be applied during training or as post-processing, and they are widely used to reduce the computational demands in terms of memory footprint, inference speed, and energy efficiency. We also briefly discuss different concepts of embedded hardware for DNNs and their compatibility with machine learning techniques as well as potential for energy and latency reduction. We substantiate our discussion with experiments on well-known benchmark data sets using compression techniques (quantization, pruning) for a set of resource-constrained embedded systems, such as CPUs, GPUs and FPGAs. The obtained results highlight the difficulty of finding good trade-offs between resource efficiency and prediction quality.
4/9/2024
📉
Empirical Guidelines for Deploying LLMs onto Resource-constrained Edge Devices
Ruiyang Qin, Dancheng Liu, Zheyu Yan, Zhaoxuan Tan, Zixuan Pan, Zhenge Jia, Meng Jiang, Ahmed Abbasi, Jinjun Xiong, Yiyu Shi
0
0
The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and inference. As LLMs are increasingly used as personalized intelligent assistants, their customization (i.e., learning through fine-tuning) and deployment onto resource-constrained edge devices will become more and more prevalent. An urging but open question is how a resource-constrained computing environment would affect the design choices for a personalized LLM. We study this problem empirically in this work. In particular, we consider the tradeoffs among a number of key design factors and their intertwined impacts on learning efficiency and accuracy. The factors include the learning methods for LLM customization, the amount of personalized data used for learning customization, the types and sizes of LLMs, the compression methods of LLMs, the amount of time afforded to learn, and the difficulty levels of the target use cases. Through extensive experimentation and benchmarking, we draw a number of surprisingly insightful guidelines for deploying LLMs onto resource-constrained devices. For example, an optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task, the longer fine-tuning time does not necessarily help the model, and a compressed LLM may be a better choice than an uncompressed LLM to learn from limited personalized data.
6/17/2024
🤿
Deep Learning Inference on Heterogeneous Mobile Processors: Potentials and Pitfalls
Sicong Liu, Wentao Zhou, Zimu Zhou, Bin Guo, Minfan Wang, Cheng Fang, Zheng Lin, Zhiwen Yu
0
0
There is a growing demand to deploy computation-intensive deep learning (DL) models on resource-constrained mobile devices for real-time intelligent applications. Equipped with a variety of processing units such as CPUs, GPUs, and NPUs, the mobile devices hold potential to accelerate DL inference via parallel execution across heterogeneous processors. Various efficient parallel methods have been explored to optimize computation distribution, achieve load balance, and minimize communication cost across processors. Yet their practical effectiveness in the dynamic and diverse real-world mobile environment is less explored. This paper presents a holistic empirical study to assess the capabilities and challenges associated with parallel DL inference on heterogeneous mobile processors. Through carefully designed experiments covering various DL models, mobile software/hardware environments, workload patterns, and resource availability, we identify limitations of existing techniques and highlight opportunities for cross-level optimization.
5/6/2024
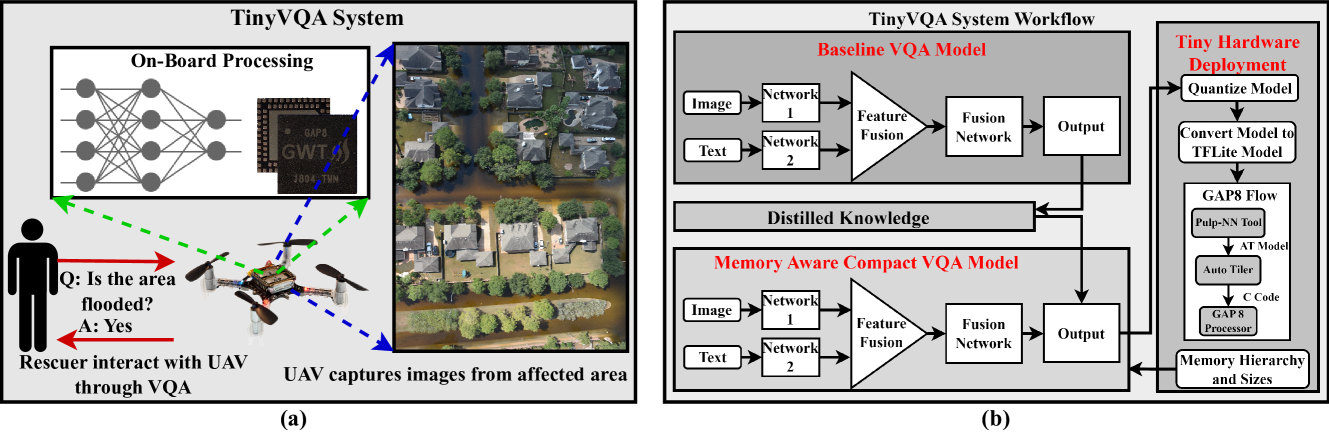
TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Devices
Hasib-Al Rashid, Argho Sarkar, Aryya Gangopadhyay, Maryam Rahnemoonfar, Tinoosh Mohsenin
0
0
Traditional machine learning models often require powerful hardware, making them unsuitable for deployment on resource-limited devices. Tiny Machine Learning (tinyML) has emerged as a promising approach for running machine learning models on these devices, but integrating multiple data modalities into tinyML models still remains a challenge due to increased complexity, latency, and power consumption. This paper proposes TinyVQA, a novel multimodal deep neural network for visual question answering tasks that can be deployed on resource-constrained tinyML hardware. TinyVQA leverages a supervised attention-based model to learn how to answer questions about images using both vision and language modalities. Distilled knowledge from the supervised attention-based VQA model trains the memory aware compact TinyVQA model and low bit-width quantization technique is employed to further compress the model for deployment on tinyML devices. The TinyVQA model was evaluated on the FloodNet dataset, which is used for post-disaster damage assessment. The compact model achieved an accuracy of 79.5%, demonstrating the effectiveness of TinyVQA for real-world applications. Additionally, the model was deployed on a Crazyflie 2.0 drone, equipped with an AI deck and GAP8 microprocessor. The TinyVQA model achieved low latencies of 56 ms and consumes 693 mW power while deployed on the tiny drone, showcasing its suitability for resource-constrained embedded systems.
4/5/2024