An Empirical Study of Mamba-based Pedestrian Attribute Recognition

0

Sign in to get full access
Overview
• This paper presents an empirical study on the use of a Mamba-based approach for pedestrian attribute recognition, which aims to identify various characteristics of people in images or videos. • The Mamba framework is a hybrid transformer-based architecture that has shown promising results in computer vision tasks. • The researchers investigate the performance of the Mamba-based approach on pedestrian attribute recognition and compare it to other state-of-the-art methods.
Plain English Explanation
The paper looks at using a new type of AI model called Mamba for the task of identifying attributes of people in images or videos. Mamba is a hybrid architecture that combines transformer-based models (which are good at understanding context) with other types of models. The researchers wanted to see how well Mamba could recognize things like a person's age, gender, clothing, and other characteristics compared to other AI models that are commonly used for this task. They ran experiments to compare the performance of Mamba-based models to other approaches and reported their findings.
Technical Explanation
The paper focuses on using the Mamba framework for the task of pedestrian attribute recognition. Mamba is a hybrid architecture that integrates transformer-based models with other types of neural networks to create a powerful vision backbone.
The researchers designed experiments to evaluate the performance of Mamba-based models on several pedestrian attribute recognition benchmarks. They compared the Mamba approach to other state-of-the-art methods, including PointRamba, which is another hybrid transformer-Mamba framework, as well as more traditional convolutional neural network models.
The experiments analyzed factors such as inference time, accuracy on attribute classification, and robustness to variations in the input data. The results showed that the Mamba-based models achieved competitive or superior performance compared to the other approaches tested.
Critical Analysis
The paper provides a thorough empirical evaluation of the Mamba framework for pedestrian attribute recognition. However, it does not address some potential limitations or areas for further research.
For example, the paper does not discuss how the Mamba-based models might perform in real-world scenarios with more challenging or noisy data, such as low-resolution images or occlusions. Additionally, the paper does not explore the interpretability of the Mamba models or provide insights into which features or components are most important for accurate attribute recognition.
Further research could also investigate the transferability of the Mamba-based approach to other computer vision tasks beyond pedestrian attribute recognition.
Conclusion
This paper presents an empirical study on the use of the Mamba framework for pedestrian attribute recognition. The results demonstrate that Mamba-based models can achieve state-of-the-art performance on this task, outperforming other approaches in terms of accuracy and inference time. While the paper provides a solid foundation, there are opportunities for further research to explore the real-world robustness, interpretability, and transferability of the Mamba-based approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Empirical Study of Mamba-based Pedestrian Attribute Recognition
Xiao Wang, Weizhe Kong, Jiandong Jin, Shiao Wang, Ruichong Gao, Qingchuan Ma, Chenglong Li, Jin Tang
Current strong pedestrian attribute recognition models are developed based on Transformer networks, which are computationally heavy. Recently proposed models with linear complexity (e.g., Mamba) have garnered significant attention and have achieved a good balance between accuracy and computational cost across a variety of visual tasks. Relevant review articles also suggest that while these models can perform well on some pedestrian attribute recognition datasets, they are generally weaker than the corresponding Transformer models. To further tap into the potential of the novel Mamba architecture for PAR tasks, this paper designs and adapts Mamba into two typical PAR frameworks, i.e., the text-image fusion approach and pure vision Mamba multi-label recognition framework. It is found that interacting with attribute tags as additional input does not always lead to an improvement, specifically, Vim can be enhanced, but VMamba cannot. This paper further designs various hybrid Mamba-Transformer variants and conducts thorough experimental validations. These experimental results indicate that simply enhancing Mamba with a Transformer does not always lead to performance improvements but yields better results under certain settings. We hope this empirical study can further inspire research in Mamba for PAR, and even extend into the domain of multi-label recognition, through the design of these network structures and comprehensive experimentation. The source code of this work will be released at url{https://github.com/Event-AHU/OpenPAR}
Read more7/16/2024

0
A Survey of Mamba
Haohao Qu, Liangbo Ning, Rui An, Wenqi Fan, Tyler Derr, Hui Liu, Xin Xu, Qing Li
As one of the most representative DL techniques, Transformer architecture has empowered numerous advanced models, especially the large language models (LLMs) that comprise billions of parameters, becoming a cornerstone in deep learning. Despite the impressive achievements, Transformers still face inherent limitations, particularly the time-consuming inference resulting from the quadratic computation complexity of attention calculation. Recently, a novel architecture named Mamba, drawing inspiration from classical state space models (SSMs), has emerged as a promising alternative for building foundation models, delivering comparable modeling abilities to Transformers while preserving near-linear scalability concerning sequence length. This has sparked an increasing number of studies actively exploring Mamba's potential to achieve impressive performance across diverse domains. Given such rapid evolution, there is a critical need for a systematic review that consolidates existing Mamba-empowered models, offering a comprehensive understanding of this emerging model architecture. In this survey, we therefore conduct an in-depth investigation of recent Mamba-associated studies, covering three main aspects: the advancements of Mamba-based models, the techniques of adapting Mamba to diverse data, and the applications where Mamba can excel. Specifically, we first review the foundational knowledge of various representative deep learning models and the details of Mamba-1&2 as preliminaries. Then, to showcase the significance of Mamba for AI, we comprehensively review the related studies focusing on Mamba models' architecture design, data adaptability, and applications. Finally, we present a discussion of current limitations and explore various promising research directions to provide deeper insights for future investigations.
Read more8/23/2024

0
Why mamba is effective? Exploit Linear Transformer-Mamba Network for Multi-Modality Image Fusion
Chenguang Zhu, Shan Gao, Huafeng Chen, Guangqian Guo, Chaowei Wang, Yaoxing Wang, Chen Shu Lei, Quanjiang Fan
Multi-modality image fusion aims to integrate the merits of images from different sources and render high-quality fusion images. However, existing feature extraction and fusion methods are either constrained by inherent local reduction bias and static parameters during inference (CNN) or limited by quadratic computational complexity (Transformers), and cannot effectively extract and fuse features. To solve this problem, we propose a dual-branch image fusion network called Tmamba. It consists of linear Transformer and Mamba, which has global modeling capabilities while maintaining linear complexity. Due to the difference between the Transformer and Mamba structures, the features extracted by the two branches carry channel and position information respectively. T-M interaction structure is designed between the two branches, using global learnable parameters and convolutional layers to transfer position and channel information respectively. We further propose cross-modal interaction at the attention level to obtain cross-modal attention. Experiments show that our Tmamba achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. Code with checkpoints will be available after the peer-review process.
Read more9/6/2024
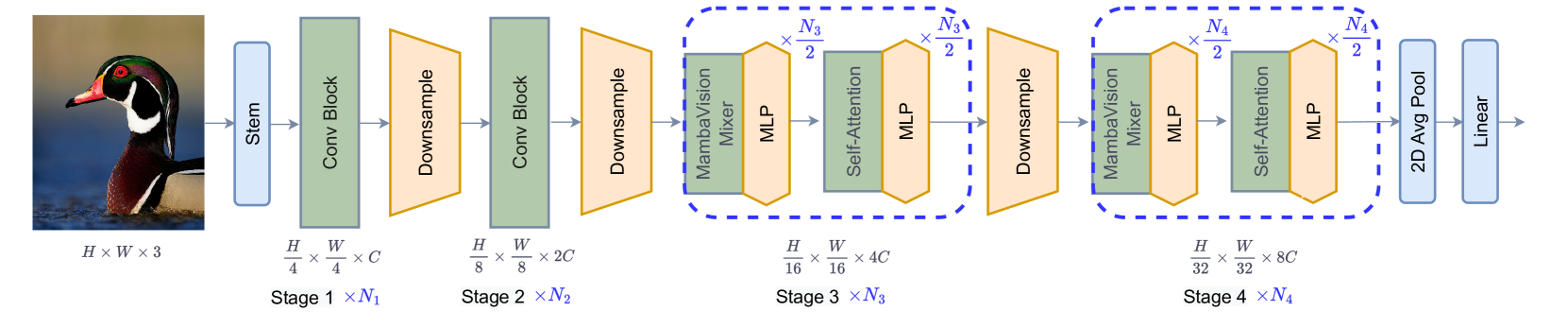
0
MambaVision: A Hybrid Mamba-Transformer Vision Backbone
Ali Hatamizadeh, Jan Kautz
We propose a novel hybrid Mamba-Transformer backbone, denoted as MambaVision, which is specifically tailored for vision applications. Our core contribution includes redesigning the Mamba formulation to enhance its capability for efficient modeling of visual features. In addition, we conduct a comprehensive ablation study on the feasibility of integrating Vision Transformers (ViT) with Mamba. Our results demonstrate that equipping the Mamba architecture with several self-attention blocks at the final layers greatly improves the modeling capacity to capture long-range spatial dependencies. Based on our findings, we introduce a family of MambaVision models with a hierarchical architecture to meet various design criteria. For Image classification on ImageNet-1K dataset, MambaVision model variants achieve a new State-of-the-Art (SOTA) performance in terms of Top-1 accuracy and image throughput. In downstream tasks such as object detection, instance segmentation and semantic segmentation on MS COCO and ADE20K datasets, MambaVision outperforms comparably-sized backbones and demonstrates more favorable performance. Code: https://github.com/NVlabs/MambaVision.
Read more7/12/2024