Venturing into Uncharted Waters: The Navigation Compass from Transformer to Mamba
2406.16722
0
0
⛏️
Abstract
Transformer, a deep neural network architecture, has long dominated the field of natural language processing and beyond. Nevertheless, the recent introduction of Mamba challenges its supremacy, sparks considerable interest among researchers, and gives rise to a series of Mamba-based models that have exhibited notable potential. This survey paper orchestrates a comprehensive discussion, diving into essential research dimensions, covering: (i) the functioning of the Mamba mechanism and its foundation on the principles of structured state space models; (ii) the proposed improvements and the integration of Mamba with various networks, exploring its potential as a substitute for Transformers; (iii) the combination of Transformers and Mamba to compensate for each other's shortcomings. We have also made efforts to interpret Mamba and Transformer in the framework of kernel functions, allowing for a comparison of their mathematical nature within a unified context. Our paper encompasses the vast majority of improvements related to Mamba to date.
Create account to get full access
Overview
- Transformer, a deep neural network architecture, has long dominated natural language processing and beyond.
- However, the recent introduction of Mamba challenges Transformer's supremacy and has sparked considerable interest among researchers.
- This survey paper provides a comprehensive discussion of Mamba, covering its functioning, proposed improvements, and its integration with various networks, including its potential as a substitute for Transformers.
- The paper also explores the combination of Transformers and Mamba to compensate for each other's shortcomings.
- The research aims to interpret Mamba and Transformer in the framework of kernel functions, allowing for a comparison of their mathematical nature within a unified context.
- The paper encompasses the vast majority of improvements related to Mamba to date.
Plain English Explanation
Transformer models have been the dominant force in natural language processing for a while. But a new model called Mamba has recently been introduced, and it's shaking things up. This paper takes a close look at Mamba and how it compares to Transformers.
The paper starts by explaining how Mamba works, including the principles it's based on. It then dives into the various ways researchers have been trying to improve Mamba and use it in different types of neural networks, including as a possible replacement for Transformers.
The paper also explores combining Transformers and Mamba to take advantage of the strengths of both models. And it goes a step further, looking at Transformer and Mamba from a mathematical perspective to better understand their underlying similarities and differences.
Overall, this paper provides a comprehensive overview of the latest developments in Mamba research, covering the key ideas and their significance in an accessible way.
Technical Explanation
The paper first introduces Transformer, a deep neural network architecture that has long dominated the field of natural language processing. However, the recent introduction of Mamba has challenged Transformer's supremacy, sparking considerable interest among researchers.
The paper then delves into the functioning of the Mamba mechanism, explaining that it is founded on the principles of structured state space models. The researchers have proposed various improvements to Mamba and explored its integration with different networks, examining its potential as a substitute for Transformers.
Additionally, the paper discusses the combination of Transformers and Mamba, exploring how the two models can be used together to compensate for each other's shortcomings. The researchers have also made efforts to interpret Mamba and Transformer in the framework of kernel functions, allowing for a comparison of their mathematical nature within a unified context.
The paper covers a comprehensive range of improvements related to Mamba, including PointRamba, a hybrid Transformer-Mamba framework for point cloud processing, and MaMBA-Speech, which explores Mamba as an alternative to self-attention mechanisms in speech recognition.
Critical Analysis
The paper provides a thorough and balanced examination of the Mamba model, acknowledging its potential as a challenger to the established Transformer architecture. However, the researchers do not delve deeply into the limitations or potential drawbacks of Mamba.
One area that could be further explored is the computational efficiency and training requirements of Mamba-based models compared to Transformers. While the paper mentions the integration of Mamba with various networks, it does not provide a comprehensive benchmarking of Mamba's performance across different tasks and datasets.
Additionally, the paper could have discussed the potential challenges in transitioning from Transformer-based models to Mamba-based ones, such as the need for retraining or adapting existing Transformer-based systems. This would help readers understand the practical implications of adopting Mamba in real-world applications.
Overall, the paper offers a valuable overview of the current state of Mamba research, but additional insights into its limitations and practical considerations would further strengthen the analysis.
Conclusion
This survey paper provides a comprehensive exploration of the Mamba model, a deep neural network architecture that has emerged as a challenger to the dominant Transformer architecture in natural language processing and beyond.
The paper delves into the functioning of Mamba, its proposed improvements, and its integration with various networks, including its potential as a substitute for Transformers. It also examines the combination of Transformers and Mamba, exploring how the two models can be used together to leverage their respective strengths.
By interpreting Mamba and Transformer in the framework of kernel functions, the researchers have enabled a deeper mathematical understanding of the two models and their underlying similarities and differences.
The paper's comprehensive coverage of Mamba research to date, including related models like PointRamba and MaMBA-Speech, offers valuable insights for researchers and practitioners interested in exploring alternatives to the Transformer architecture. As the field continues to evolve, this paper serves as a valuable resource for understanding the current state and potential of the Mamba model.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting
Xiongxiao Xu, Yueqing Liang, Baixiang Huang, Zhiling Lan, Kai Shu
0
0
Time series forecasting is an important problem and plays a key role in a variety of applications including weather forecasting, stock market, and scientific simulations. Although transformers have proven to be effective in capturing dependency, its quadratic complexity of attention mechanism prevents its further adoption in long-range time series forecasting, thus limiting them attend to short-range range. Recent progress on state space models (SSMs) have shown impressive performance on modeling long range dependency due to their subquadratic complexity. Mamba, as a representative SSM, enjoys linear time complexity and has achieved strong scalability on tasks that requires scaling to long sequences, such as language, audio, and genomics. In this paper, we propose to leverage a hybrid framework Mambaformer that internally combines Mamba for long-range dependency, and Transformer for short range dependency, for long-short range forecasting. To the best of our knowledge, this is the first paper to combine Mamba and Transformer architecture in time series data. We investigate possible hybrid architectures to combine Mamba layer and attention layer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform Mamba and Transformer in long-short range time series forecasting problem. The code is available at https://github.com/XiongxiaoXu/Mambaformerin-Time-Series.
4/24/2024

PoinTramba: A Hybrid Transformer-Mamba Framework for Point Cloud Analysis
Zicheng Wang, Zhenghao Chen, Yiming Wu, Zhen Zhao, Luping Zhou, Dong Xu
0
0
Point cloud analysis has seen substantial advancements due to deep learning, although previous Transformer-based methods excel at modeling long-range dependencies on this task, their computational demands are substantial. Conversely, the Mamba offers greater efficiency but shows limited potential compared with Transformer-based methods. In this study, we introduce PoinTramba, a pioneering hybrid framework that synergies the analytical power of Transformer with the remarkable computational efficiency of Mamba for enhanced point cloud analysis. Specifically, our approach first segments point clouds into groups, where the Transformer meticulously captures intricate intra-group dependencies and produces group embeddings, whose inter-group relationships will be simultaneously and adeptly captured by efficient Mamba architecture, ensuring comprehensive analysis. Unlike previous Mamba approaches, we introduce a bi-directional importance-aware ordering (BIO) strategy to tackle the challenges of random ordering effects. This innovative strategy intelligently reorders group embeddings based on their calculated importance scores, significantly enhancing Mamba's performance and optimizing the overall analytical process. Our framework achieves a superior balance between computational efficiency and analytical performance by seamlessly integrating these advanced techniques, marking a substantial leap forward in point cloud analysis. Extensive experiments on datasets such as ScanObjectNN, ModelNet40, and ShapeNetPart demonstrate the effectiveness of our approach, establishing a new state-of-the-art analysis benchmark on point cloud recognition. For the first time, this paradigm leverages the combined strengths of both Transformer and Mamba architectures, facilitating a new standard in the field. The code is available at https://github.com/xiaoyao3302/PoinTramba.
6/18/2024
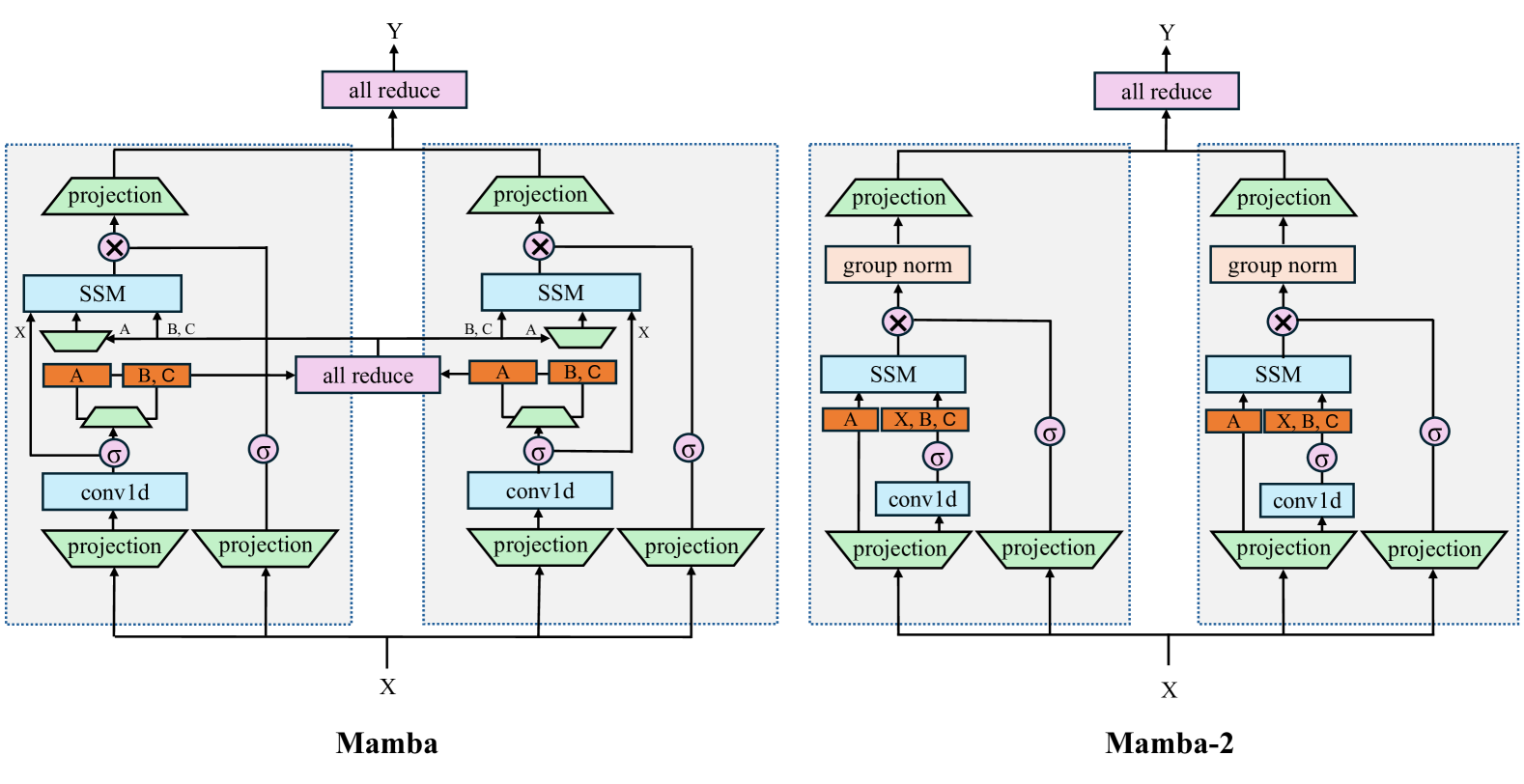
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
0
0
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
6/13/2024
🤯
Mamba in Speech: Towards an Alternative to Self-Attention
Xiangyu Zhang, Qiquan Zhang, Hexin Liu, Tianyi Xiao, Xinyuan Qian, Beena Ahmed, Eliathamby Ambikairajah, Haizhou Li, Julien Epps
0
0
Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing using two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The experimental results exhibit the superiority of bidirectional Mamba (BiMamba) for speech processing to vanilla Mamba. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in Transformer and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section to offer insights for future research.
5/27/2024