An Empirical Study of Retrieval Augmented Generation with Chain-of-Thought

0

Sign in to get full access
Overview
- This paper presents an empirical study on the use of retrieval-augmented generation with chain-of-thought for language models.
- The researchers investigate how incorporating external knowledge and step-by-step reasoning can improve the performance of language models on various tasks.
- The study analyzes the effectiveness of this approach across different datasets and model architectures.
Plain English Explanation
The researchers in this study wanted to see if they could make language models (like GPT) better at certain tasks by giving them access to external information and having them walk through their reasoning step-by-step.
They took language models and had them generate text based on prompts, but also allowed the models to retrieve relevant information from a database and explain their reasoning in a chain of logical steps.
The goal was to see if this "retrieval-augmented generation with chain-of-thought" approach could improve the performance of language models on different types of tasks, like answering questions or summarizing information.
The researchers tested this across various datasets and model architectures to get a sense of how well it worked in different contexts.
Technical Explanation
The paper describes an experiment where the researchers incorporated retrieval-augmented generation with chain-of-thought into language models.
They took different language model architectures and fine-tuned them on various datasets. During generation, the models were able to retrieve relevant information from a knowledge base and then provide a step-by-step explanation of their reasoning process.
The researchers evaluated the performance of these models on tasks like question answering, fact verification, and open-ended generation. They compared the results to standard language models without the retrieval and reasoning capabilities.
The findings suggest that the retrieval-augmented generation with chain-of-thought approach can significantly boost the performance of language models across these different tasks and datasets. The models were able to leverage the external knowledge and explicit reasoning to generate more accurate and coherent outputs.
Critical Analysis
The paper provides a thorough and well-designed empirical study on an important topic in language model research. The researchers carefully considered different datasets, model architectures, and evaluation metrics to assess the effectiveness of their approach.
However, the paper does note some limitations. The external knowledge source used in the experiments was relatively small and curated, so it's unclear how well the approach would scale to larger, noisier knowledge bases. Additionally, the chain-of-thought reasoning was scripted rather than fully generative, which may constrain the models' ability to explain their thinking in more open-ended ways.
Further research could explore ways to make the retrieval and reasoning more flexible and adaptive, as well as investigate the approach's performance on a wider range of real-world tasks. It would also be valuable to better understand the specific mechanisms by which the retrieval and reasoning components enhance the language models' capabilities.
Conclusion
This paper presents a compelling case for the benefits of incorporating retrieval-augmented generation with chain-of-thought into language models. The empirical results demonstrate significant performance improvements across various tasks, suggesting that this approach could be a valuable tool for developing more capable and transparent AI systems.
The findings have implications for advancing language understanding and generation, as well as for improving the interpretability and trustworthiness of AI-powered applications. As language models become increasingly powerful and ubiquitous, techniques like the one explored in this paper may play an important role in ensuring they are used responsibly and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Empirical Study of Retrieval Augmented Generation with Chain-of-Thought
Yuetong Zhao, Hongyu Cao, Xianyu Zhao, Zhijian Ou
Since the launch of ChatGPT at the end of 2022, generative dialogue models represented by ChatGPT have quickly become essential tools in daily life. As user expectations increase, enhancing the capability of generative dialogue models to solve complex problems has become a focal point of current research. This paper delves into the effectiveness of the RAFT (Retrieval Augmented Fine-Tuning) method in improving the performance of Generative dialogue models. RAFT combines chain-of-thought with model supervised fine-tuning (SFT) and retrieval augmented generation (RAG), which significantly enhanced the model's information extraction and logical reasoning abilities. We evaluated the RAFT method across multiple datasets and analysed its performance in various reasoning tasks, including long-form QA and short-form QA tasks, tasks in both Chinese and English, and supportive and comparison reasoning tasks. Notably, it addresses the gaps in previous research regarding long-form QA tasks and Chinese datasets. Moreover, we also evaluate the benefit of the chain-of-thought (CoT) in the RAFT method. This work offers valuable insights for studies focused on enhancing the performance of generative dialogue models.
Read more9/2/2024

2
RAFT: Adapting Language Model to Domain Specific RAG
Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a open-book in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
Read more6/6/2024
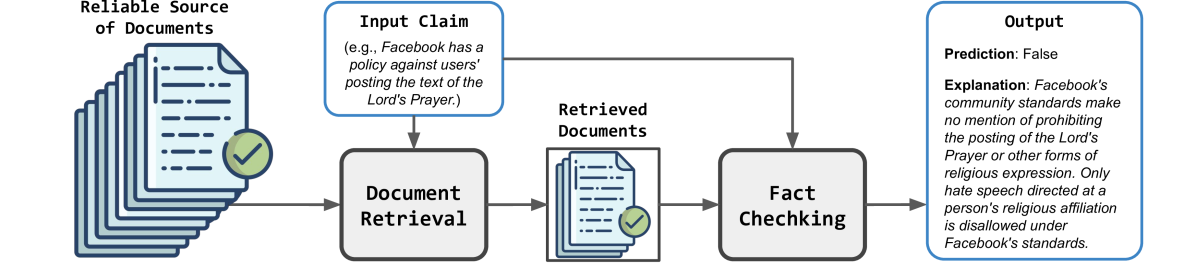
0
Retrieval Augmented Fact Verification by Synthesizing Contrastive Arguments
Zhenrui Yue, Huimin Zeng, Lanyu Shang, Yifan Liu, Yang Zhang, Dong Wang
The rapid propagation of misinformation poses substantial risks to public interest. To combat misinformation, large language models (LLMs) are adapted to automatically verify claim credibility. Nevertheless, existing methods heavily rely on the embedded knowledge within LLMs and / or black-box APIs for evidence collection, leading to subpar performance with smaller LLMs or upon unreliable context. In this paper, we propose retrieval augmented fact verification through the synthesis of contrasting arguments (RAFTS). Upon input claims, RAFTS starts with evidence retrieval, where we design a retrieval pipeline to collect and re-rank relevant documents from verifiable sources. Then, RAFTS forms contrastive arguments (i.e., supporting or refuting) conditioned on the retrieved evidence. In addition, RAFTS leverages an embedding model to identify informative demonstrations, followed by in-context prompting to generate the prediction and explanation. Our method effectively retrieves relevant documents as evidence and evaluates arguments from varying perspectives, incorporating nuanced information for fine-grained decision-making. Combined with informative in-context examples as prior, RAFTS achieves significant improvements to supervised and LLM baselines without complex prompts. We demonstrate the effectiveness of our method through extensive experiments, where RAFTS can outperform GPT-based methods with a significantly smaller 7B LLM.
Read more6/17/2024

0
A Survey on Retrieval-Augmented Text Generation for Large Language Models
Yizheng Huang, Jimmy Huang
Retrieval-Augmented Generation (RAG) merges retrieval methods with deep learning advancements to address the static limitations of large language models (LLMs) by enabling the dynamic integration of up-to-date external information. This methodology, focusing primarily on the text domain, provides a cost-effective solution to the generation of plausible but possibly incorrect responses by LLMs, thereby enhancing the accuracy and reliability of their outputs through the use of real-world data. As RAG grows in complexity and incorporates multiple concepts that can influence its performance, this paper organizes the RAG paradigm into four categories: pre-retrieval, retrieval, post-retrieval, and generation, offering a detailed perspective from the retrieval viewpoint. It outlines RAG's evolution and discusses the field's progression through the analysis of significant studies. Additionally, the paper introduces evaluation methods for RAG, addressing the challenges faced and proposing future research directions. By offering an organized framework and categorization, the study aims to consolidate existing research on RAG, clarify its technological underpinnings, and highlight its potential to broaden the adaptability and applications of LLMs.
Read more8/26/2024