ReFT: Reasoning with Reinforced Fine-Tuning
2401.08967
1
0
🌀
Abstract
One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
Create account to get full access
Overview
- This paper proposes a new approach called Reinforced Fine-Tuning (ReFT) to enhance the reasoning capabilities of Large Language Models (LLMs).
- The key idea is to use reinforcement learning to fine-tune LLMs, building on an initial supervised fine-tuning stage.
- This allows the model to learn from multiple possible reasoning paths for each problem, rather than just a single annotated path.
- Experiments show that ReFT significantly outperforms the standard supervised fine-tuning approach, with better generalization to new problems.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive capabilities, but they still struggle with complex reasoning tasks like math problem-solving. One approach to improve their reasoning is Supervised Fine-Tuning (SFT) using "chain-of-thought" annotations that provide the step-by-step reasoning. However, this approach has limitations because the training data only includes a single annotated reasoning path per problem.
The authors propose a new method called Reinforced Fine-Tuning (ReFT) that can learn from multiple possible reasoning paths. First, the model is warmed up using SFT. Then, it undergoes reinforcement learning, where the model is encouraged to generate various reasoning paths for each problem. The quality of these paths is automatically evaluated based on how well they match the final correct answer.
By learning from a richer set of reasoning examples, the ReFT model is able to better generalize its problem-solving skills. The authors show that ReFT significantly outperforms SFT on math reasoning benchmarks like GSM8K, MathQA, and SVAMP. This indicates that the reinforcement learning approach helps the model develop more robust and flexible reasoning capabilities.
Technical Explanation
The key innovation of this paper is the Reinforced Fine-Tuning (ReFT) approach, which builds on the standard Supervised Fine-Tuning (SFT) method.
In SFT, the language model is fine-tuned on annotated "chain-of-thought" reasoning paths provided in the training data. However, this has limited generalization ability because there is usually only a single annotated path per problem.
ReFT addresses this by using reinforcement learning to fine-tune the model. First, it goes through an SFT warmup stage. Then, during the reinforcement learning phase, the model is encouraged to generate multiple reasoning paths for each problem. These paths are automatically evaluated based on how well they match the ground-truth answer, and the model is updated to generate higher-quality paths.
The authors use the Proximal Policy Optimization (PPO) algorithm for the reinforcement learning stage. By learning from a diverse set of reasoning examples, the ReFT model is able to develop more generalizable problem-solving skills.
Extensive experiments on math reasoning benchmarks like GSM8K, MathQA, and SVAMP show that ReFT significantly outperforms the standard SFT approach. The authors also find that ReFT's performance can be further improved by using inference-time strategies like majority voting and re-ranking.
Critical Analysis
The ReFT approach is a clever and effective way to address the limitations of standard supervised fine-tuning for enhancing the reasoning capabilities of large language models. By leveraging reinforcement learning, the model is able to learn from a richer set of reasoning examples, leading to better generalization.
One potential limitation of the approach is that it still relies on the availability of annotated training data, even if the annotations are used more efficiently. An interesting extension could be to explore ways to learn effective reasoning strategies without requiring any human-provided annotations, perhaps through unsupervised or self-supervised methods.
Additionally, the authors only evaluate ReFT on math reasoning tasks, so it would be valuable to see how well the approach generalizes to other types of reasoning problems, such as those involving language understanding, logical inference, or commonsense reasoning.
Overall, the ReFT method represents a promising step forward in improving the reasoning abilities of large language models, and the authors' experiments demonstrate its effectiveness. Readers are encouraged to think critically about the approach and consider how it could be further refined and applied to other domains.
Conclusion
This paper introduces Reinforced Fine-Tuning (ReFT), a novel approach for enhancing the reasoning capabilities of large language models. By incorporating reinforcement learning into the fine-tuning process, ReFT allows the model to learn from a diverse set of reasoning paths, leading to better generalization on math reasoning tasks compared to standard supervised fine-tuning.
The key insight is that while supervised fine-tuning with annotated reasoning steps is helpful, it is limited by the fact that training data typically only includes a single annotated path per problem. ReFT addresses this by automatically generating and evaluating multiple reasoning paths during the fine-tuning stage, enabling the model to develop more robust problem-solving skills.
The authors' experiments demonstrate the effectiveness of ReFT, with significant performance gains over supervised fine-tuning on benchmark datasets. This work represents an important step forward in improving the reasoning abilities of large language models, and the principles behind ReFT could potentially be applied to enhance other types of cognitive capabilities as well.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Optimizing Language Model's Reasoning Abilities with Weak Supervision
Yongqi Tong, Sizhe Wang, Dawei Li, Yifan Wang, Simeng Han, Zi Lin, Chengsong Huang, Jiaxin Huang, Jingbo Shang
0
0
While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on texttt{Anonymity Link}.
5/8/2024
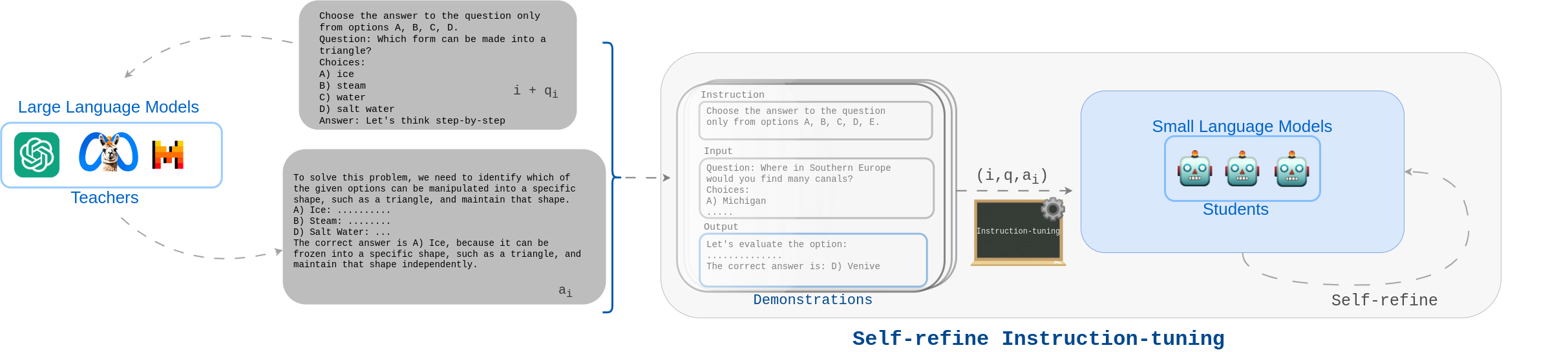
Self-Refine Instruction-Tuning for Aligning Reasoning in Language Models
Leonardo Ranaldi, Andr`e Freitas
0
0
The alignments of reasoning abilities between smaller and larger Language Models are largely conducted via Supervised Fine-Tuning (SFT) using demonstrations generated from robust Large Language Models (LLMs). Although these approaches deliver more performant models, they do not show sufficiently strong generalization ability as the training only relies on the provided demonstrations. In this paper, we propose the Self-refine Instruction-tuning method that elicits Smaller Language Models to self-refine their abilities. Our approach is based on a two-stage process, where reasoning abilities are first transferred between LLMs and Small Language Models (SLMs) via Instruction-tuning on demonstrations provided by LLMs, and then the instructed models Self-refine their abilities through preference optimization strategies. In particular, the second phase operates refinement heuristics based on the Direct Preference Optimization algorithm, where the SLMs are elicited to deliver a series of reasoning paths by automatically sampling the generated responses and providing rewards using ground truths from the LLMs. Results obtained on commonsense and math reasoning tasks show that this approach significantly outperforms Instruction-tuning in both in-domain and out-domain scenarios, aligning the reasoning abilities of Smaller and Larger Language Models.
5/2/2024
👨🏫
Unlock the Correlation between Supervised Fine-Tuning and Reinforcement Learning in Training Code Large Language Models
Jie Chen, Xintian Han, Yu Ma, Xun Zhou, Liang Xiang
0
0
Automatic code generation has been a longstanding research topic. With the advancement of general-purpose large language models (LLMs), the ability to code stands out as one important measure to the model's reasoning performance. Usually, a two-stage training paradigm is implemented to obtain a Code LLM, namely the pretraining and the fine-tuning. Within the fine-tuning, supervised fine-tuning (SFT), and reinforcement learning (RL) are often used to improve the model's zero-shot ability. A large number of work has been conducted to improve the model's performance on code-related benchmarks with either modifications to the algorithm or refinement of the dataset. However, we still lack a deep insight into the correlation between SFT and RL. For instance, what kind of dataset should be used to ensure generalization, or what if we abandon the SFT phase in fine-tuning. In this work, we make an attempt to understand the correlation between SFT and RL. To facilitate our research, we manually craft 100 basis python functions, called atomic functions, and then a synthesizing pipeline is deployed to create a large number of synthetic functions on top of the atomic ones. In this manner, we ensure that the train and test sets remain distinct, preventing data contamination. Through comprehensive ablation study, we find: (1) Both atomic and synthetic functions are indispensable for SFT's generalization, and only a handful of synthetic functions are adequate; (2) Through RL, the SFT's generalization to target domain can be greatly enhanced, even with the same training prompts; (3) Training RL from scratch can alleviate the over-fitting issue introduced in the SFT phase.
6/18/2024
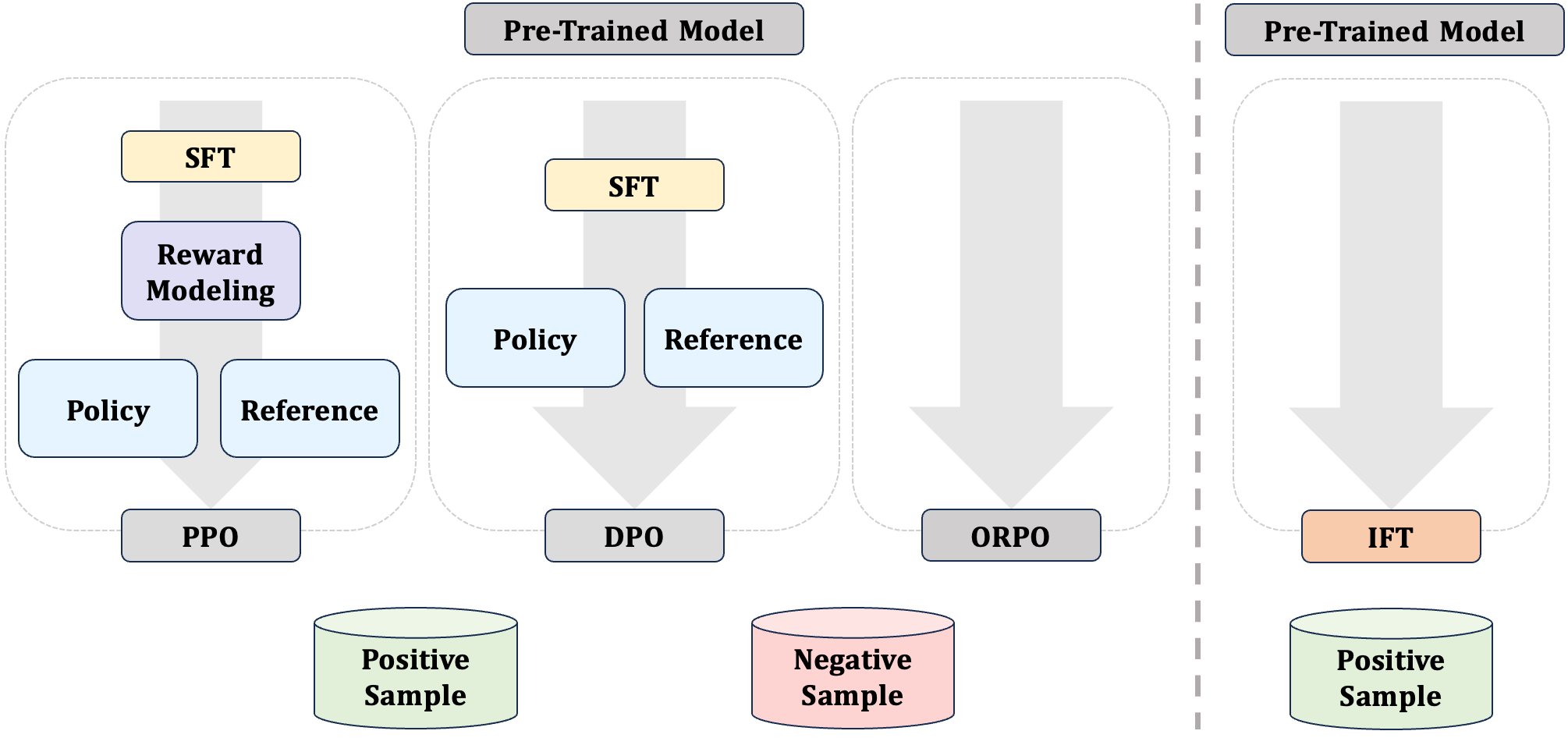
Intuitive Fine-Tuning: Towards Unifying SFT and RLHF into a Single Process
Ermo Hua, Biqing Qi, Kaiyan Zhang, Yue Yu, Ning Ding, Xingtai Lv, Kai Tian, Bowen Zhou
0
0
Supervised Fine-Tuning (SFT) and Preference Optimization (PO) are two fundamental processes for enhancing the capabilities of Language Models (LMs) post pre-training, aligning them better with human preferences. Although SFT advances in training efficiency, PO delivers better alignment, thus they are often combined. However, common practices simply apply them sequentially without integrating their optimization objectives, ignoring the opportunities to bridge their paradigm gap and take the strengths from both. To obtain a unified understanding, we interpret SFT and PO with two sub-processes -- Preference Estimation and Transition Optimization -- defined at token level within the Markov Decision Process (MDP) framework. This modeling shows that SFT is only a specialized case of PO with inferior estimation and optimization. PO evaluates the quality of model's entire generated answer, whereas SFT only scores predicted tokens based on preceding tokens from target answers. Therefore, SFT overestimates the ability of model, leading to inferior optimization. Building on this view, we introduce Intuitive Fine-Tuning (IFT) to integrate SFT and Preference Optimization into a single process. IFT captures LMs' intuitive sense of the entire answers through a temporal residual connection, but it solely relies on a single policy and the same volume of non-preference-labeled data as SFT. Our experiments show that IFT performs comparably or even superiorly to sequential recipes of SFT and some typical Preference Optimization methods across several tasks, particularly those requires generation, reasoning, and fact-following abilities. An explainable Frozen Lake game further validates the effectiveness of IFT for getting competitive policy.
5/29/2024