Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation

0
Sign in to get full access
Overview
- Auditory large language models (LLMs) can be used for automatic speech quality evaluation
- The paper presents a method to enable auditory LLMs for this task
- Experiments show the auditory LLMs can achieve high correlation with human-annotated mean opinion scores (MOS)
- The models can also be used to assess speaker similarity, which is useful for speech synthesis evaluation
Plain English Explanation
The paper explores how large language models (LLMs) trained on audio data can be used to automatically evaluate the quality of speech samples. Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation presents a method to adapt these auditory LLMs for speech quality assessment.
The key idea is to fine-tune the LLMs on datasets of speech samples annotated with human-provided mean opinion scores (MOS) - a common metric for subjective speech quality. By training the models on this data, they can learn to predict MOS values for new speech samples, providing an automatic way to evaluate quality without relying solely on human raters.
The paper also shows the auditory LLMs can be used to assess "speaker similarity" - how closely a synthesized voice matches a reference speaker. This is valuable for evaluating text-to-speech and voice cloning systems.
Overall, the research demonstrates the potential for auditory LLMs to enable more scalable and efficient speech quality evaluation, complementing traditional human-based approaches.
Technical Explanation
The paper first provides an overview of prior work on speech quality assessment, highlighting the limitations of existing automated approaches and the potential for large language models (LLMs) to address these challenges.
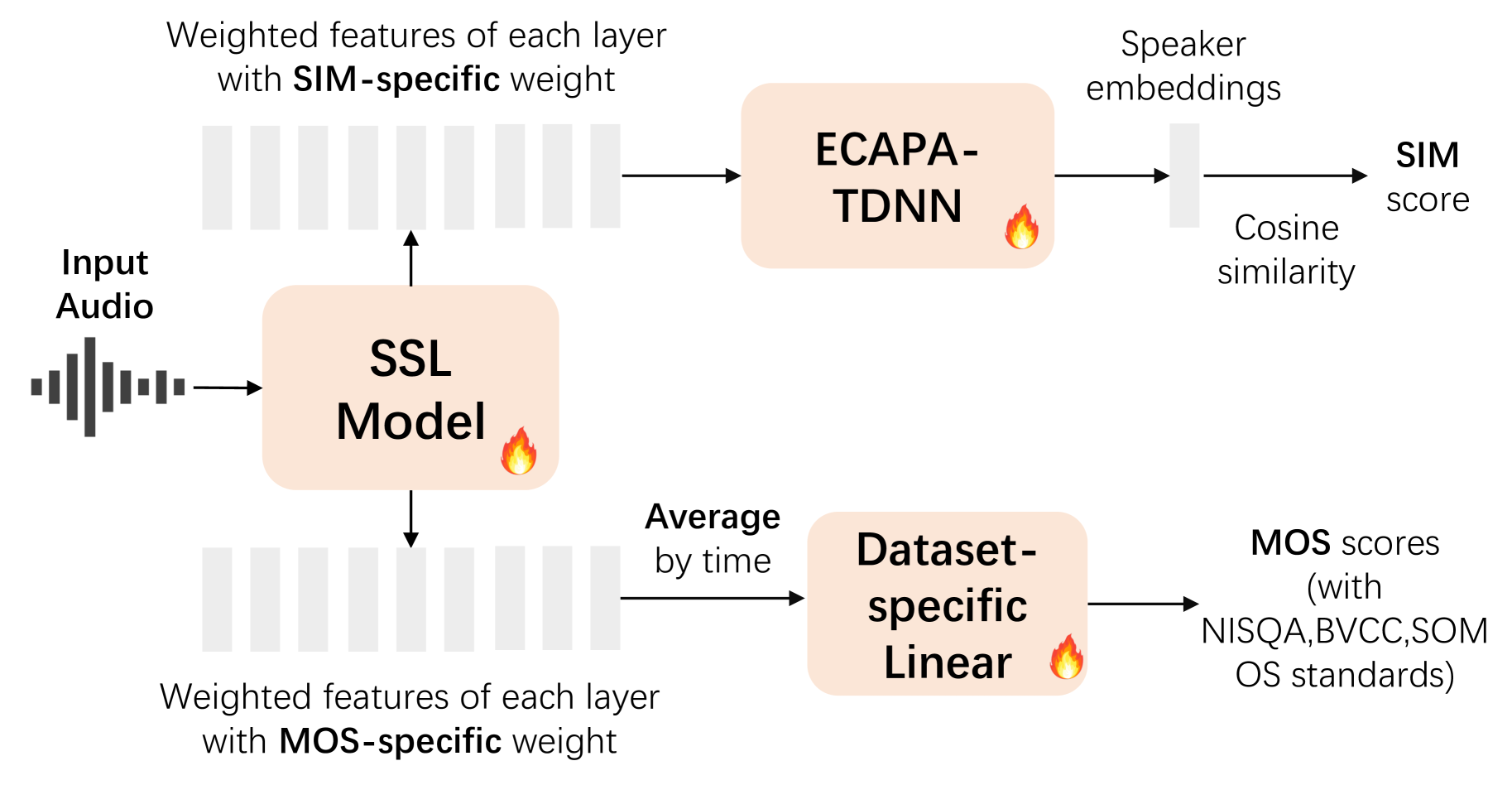
The authors then describe their method for enabling auditory LLMs for speech quality evaluation. They start with pre-trained LLM models, such as WavLLM, and fine-tune them on datasets of speech samples annotated with mean opinion scores (MOS) by human raters. This fine-tuning process allows the models to learn the relationship between acoustic features and perceived speech quality.
The paper presents experiments evaluating the fine-tuned auditory LLMs on both MOS prediction and speaker similarity assessment tasks. For MOS prediction, the models achieve high correlation with human ratings, outperforming traditional signal-based metrics. For speaker similarity, the LLMs can effectively capture the relevant acoustic cues to assess how closely a generated voice matches a reference speaker.
The authors discuss several insights from their research, including the importance of multimodal training (combining audio and text) for the LLMs, and the models' ability to generalize across different speech domains and applications.
Critical Analysis
The paper provides a compelling demonstration of how auditory large language models can be leveraged for automatic speech quality evaluation. The fine-tuning approach seems well-designed and the experiments show promising results in terms of MOS prediction accuracy and speaker similarity assessment.
However, the paper does not extensively address potential limitations or caveats of the proposed method. For example, it would be valuable to understand the models' robustness to different types of speech data, such as non-native speakers, accented speech, or low-quality audio recordings. Additionally, the paper could explore the interpretability of the LLMs' internal representations and how they relate to the perceived speech quality attributes.
Further research could also investigate the generalization of the auditory LLM approach to other speech-related tasks, such as speech emotion recognition or speaker diarization. Exploring the potential synergies between auditory and text-based LLMs could also be an interesting direction.
Overall, the paper presents an important step towards more scalable and reliable speech quality evaluation, while also highlighting the broader potential for auditory large language models in various speech-based applications.
Conclusion
This paper demonstrates how auditory large language models can be leveraged for automatic speech quality evaluation, a task that has traditionally relied on human raters. By fine-tuning pre-trained LLMs on datasets of speech samples annotated with mean opinion scores, the models can learn to accurately predict perceived speech quality.
The research also shows the potential for auditory LLMs to assess speaker similarity, which is useful for evaluating text-to-speech and voice cloning systems. The findings highlight the promise of these multimodal language models in enabling more scalable and efficient speech-related applications.
While the paper does not extensively address potential limitations, it represents an important step forward in bridging the gap between human-centric and automated approaches to speech quality assessment. As auditory LLMs continue to evolve, they may become increasingly valuable tools for a wide range of speech-based tasks and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Siyin Wang, Wenyi Yu, Yudong Yang, Changli Tang, Yixuan Li, Jimin Zhuang, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Guangzhi Sun, Lu Lu, Chao Zhang
Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.
Read more9/26/2024
0
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
Read more6/11/2024

0
Pronunciation Assessment with Multi-modal Large Language Models
Kaiqi Fu, Linkai Peng, Nan Yang, Shuran Zhou
Large language models (LLMs), renowned for their powerful conversational abilities, are widely recognized as exceptional tools in the field of education, particularly in the context of automated intelligent instruction systems for language learning. In this paper, we propose a scoring system based on LLMs, motivated by their positive impact on text-related scoring tasks. Specifically, the speech encoder first maps the learner's speech into contextual features. The adapter layer then transforms these features to align with the text embedding in latent space. The assessment task-specific prefix and prompt text are embedded and concatenated with the features generated by the modality adapter layer, enabling the LLMs to predict accuracy and fluency scores. Our experiments demonstrate that the proposed scoring systems achieve competitive results compared to the baselines on the Speechocean762 datasets. Moreover, we also conducted an ablation study to better understand the contributions of the prompt text and training strategy in the proposed scoring system.
Read more7/19/2024
0
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, Furu Wei
The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at url{aka.ms/wavllm}.
Read more9/24/2024