WavLLM: Towards Robust and Adaptive Speech Large Language Model

0
Sign in to get full access
Overview
- The paper proposes "WavLLM", a large language model (LLM) designed for robust and adaptive speech processing.
- WavLLM aims to combine the strengths of speech recognition and natural language processing models to handle various speech-related tasks.
- The model is trained on a diverse dataset to improve its ability to handle different accents, background noises, and speaking styles.
Plain English Explanation
The researchers developed a new type of large language model called "WavLLM" that is designed to work well with speech data. Large language models are powerful AI systems that can understand and generate human-like text. However, most of these models are trained on written text and struggle with speech-related tasks like transcription or understanding spoken language.
WavLLM: Towards Robust and Adaptive Speech Large Language Model aims to address this by training the model on a wide variety of speech data, including different accents, background noises, and speaking styles. The goal is to create a model that can handle speech-related tasks more robustly and adaptively compared to previous approaches.
The key idea is to combine the strengths of speech recognition models, which are good at transcribing audio, with the language understanding capabilities of large language models. This allows WavLLM to excel at tasks like speech-to-text conversion, question answering based on audio input, and even generating human-like speech.
By training on a diverse dataset, the researchers hope to make the model more versatile and able to handle the messiness of real-world speech data, rather than just performing well on clean, curated speech samples.
Technical Explanation
WavLLM: Towards Robust and Adaptive Speech Large Language Model proposes a novel large language model architecture designed specifically for speech-related tasks. The model combines a convolutional neural network (CNN) front-end for audio feature extraction with a transformer-based language model backbone.
The CNN front-end takes raw waveform audio as input and learns to extract relevant acoustic features. This is then fed into the transformer-based language model, which can understand the semantic and contextual information in the speech data.
The model is trained on a large, diverse dataset that includes various accents, background noises, and speaking styles. This training regime aims to make the model more robust and adaptable to real-world speech data, rather than just performing well on clean, curated samples.
The researchers evaluate WavLLM on a range of speech-related tasks, including speech recognition, speech-to-text translation, and audio-based question answering. The results show that WavLLM outperforms previous state-of-the-art models on these tasks, demonstrating its ability to effectively combine speech recognition and natural language processing capabilities.
Critical Analysis
The WavLLM: Towards Robust and Adaptive Speech Large Language Model paper presents a promising approach to developing large language models that can handle speech data more effectively. The researchers' focus on training the model on diverse speech data is a key strength, as it aligns with the goal of creating a versatile and adaptable system.
However, the paper does not address potential limitations or caveats of the WavLLM approach. For example, it would be helpful to understand the computational and memory requirements of the model, as well as any trade-offs in terms of performance or efficiency compared to more specialized speech recognition or language models.
Additionally, the researchers could have explored the model's performance on a wider range of speech-related tasks, such as speaker diarization, emotion recognition, or prosody analysis. This would provide a more comprehensive understanding of WavLLM's capabilities and potential applications.
Future research could also investigate how WavLLM could be further improved, such as by exploring different architectural choices, regularization techniques, or unsupervised pre-training strategies. Comparing WavLLM's performance to human-level speech processing abilities could also yield valuable insights.
Conclusion
WavLLM: Towards Robust and Adaptive Speech Large Language Model presents a novel approach to developing large language models that can effectively handle speech-related tasks. By combining speech recognition and natural language processing capabilities, the model demonstrates improved performance on a range of speech-related benchmarks.
The key strength of WavLLM is its ability to adapt to diverse speech data, making it a promising candidate for real-world applications that require robust and versatile speech processing. As large language models continue to advance, the integration of speech-specific capabilities, as demonstrated in this paper, could lead to significant advancements in areas such as voice assistants, language learning, and accessibility technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, Furu Wei
The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at url{aka.ms/wavllm}.
Read more8/15/2024
0
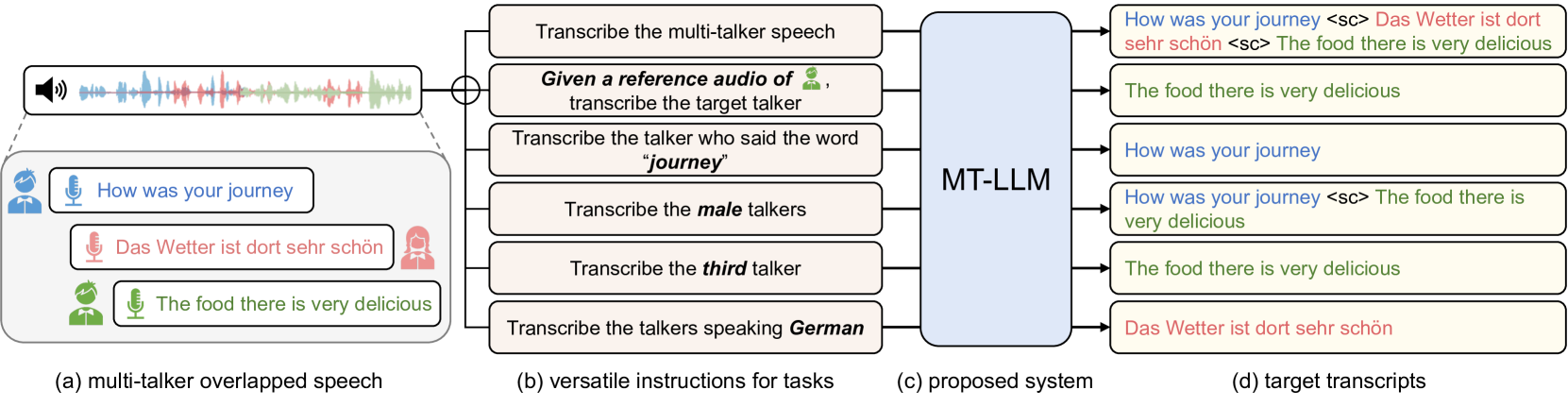
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024

0
Pronunciation Assessment with Multi-modal Large Language Models
Kaiqi Fu, Linkai Peng, Nan Yang, Shuran Zhou
Large language models (LLMs), renowned for their powerful conversational abilities, are widely recognized as exceptional tools in the field of education, particularly in the context of automated intelligent instruction systems for language learning. In this paper, we propose a scoring system based on LLMs, motivated by their positive impact on text-related scoring tasks. Specifically, the speech encoder first maps the learner's speech into contextual features. The adapter layer then transforms these features to align with the text embedding in latent space. The assessment task-specific prefix and prompt text are embedded and concatenated with the features generated by the modality adapter layer, enabling the LLMs to predict accuracy and fluency scores. Our experiments demonstrate that the proposed scoring systems achieve competitive results compared to the baselines on the Speechocean762 datasets. Moreover, we also conducted an ablation study to better understand the contributions of the prompt text and training strategy in the proposed scoring system.
Read more7/19/2024

0
Just ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue
Junkai Wu, Xulin Fan, Bo-Ru Lu, Xilin Jiang, Nima Mesgarani, Mark Hasegawa-Johnson, Mari Ostendorf
In recent years, we have observed a rapid advancement in speech language models (SpeechLLMs), catching up with humans' listening and reasoning abilities. Remarkably, SpeechLLMs have demonstrated impressive spoken dialogue question-answering (SQA) performance in benchmarks like Gaokao, the English listening test of the college entrance exam in China, which seemingly requires understanding both the spoken content and voice characteristics of speakers in a conversation. However, after carefully examining Gaokao's questions, we find the correct answers to many questions can be inferred from the conversation context alone without identifying the speaker asked in the question. Our evaluation of state-of-the-art models Qwen-Audio and WavLLM in both Gaokao and our proposed What Do You Like? dataset shows a significantly higher accuracy in these context-based questions than in identity-critical questions, which can only be answered correctly with correct speaker identification. Our results and analysis suggest that when solving SQA, the current SpeechLLMs exhibit limited speaker awareness from the audio and behave similarly to an LLM reasoning from the conversation transcription without sound. We propose that our definitions and automated classification of context-based and identity-critical questions could offer a more accurate evaluation framework of SpeechLLMs in SQA tasks.
Read more9/10/2024