Pronunciation Assessment with Multi-modal Large Language Models

0

Sign in to get full access
Overview
- This paper explores the use of multimodal large language models (LLMs) for pronunciation assessment.
- The researchers propose a method that combines audio inputs and text prompts to evaluate a speaker's pronunciation proficiency.
- The approach aims to leverage the strengths of LLMs in language understanding and generation to provide automated and scalable pronunciation feedback.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human language with impressive capabilities. In this paper, the researchers investigate how LLMs can be used to assess pronunciation, which is an important aspect of language learning and communication.
The researchers' approach involves feeding both audio recordings of a speaker and text prompts into the LLM. The LLM then uses this multimodal input to evaluate the speaker's pronunciation proficiency. This allows the LLM to leverage its strong language understanding skills to provide detailed and personalized feedback on the speaker's pronunciation.
By automating the pronunciation assessment process, this method has the potential to make language learning more accessible and scalable, especially for scenarios where individualized feedback from human experts may be limited. The researchers believe this technology could be particularly useful for language learners, as well as in educational and professional settings where clear pronunciation is important.
Technical Explanation
The key elements of the researchers' proposed method are as follows:
-
Multimodal Input: The approach combines audio recordings of a speaker's utterances and corresponding text prompts as input to the LLM.
-
LLM-based Pronunciation Assessment: The LLM is tasked with evaluating the speaker's pronunciation proficiency based on the multimodal input. This leverages the LLM's language understanding and generation capabilities to provide detailed feedback.
-
Architecture: The researchers explore different ways of integrating the audio and text inputs, such as using cross-modal attention mechanisms or separate encoders for each modality. The choice of LLM architecture is also an important consideration.
-
Training and Evaluation: The model is trained on a dataset of speaker audio recordings, text prompts, and human-annotated pronunciation scores. The researchers evaluate the model's performance in accurately assessing pronunciation proficiency.
The authors believe this multimodal LLM-based approach has several advantages over traditional pronunciation assessment methods, including scalability, personalization, and the ability to provide detailed feedback. The research also has implications for broader efforts to transform LLMs into cross-modal and cross-lingual systems and leverage LLMs for spoken language understanding.
Critical Analysis
The paper provides a promising approach for using LLMs to automate pronunciation assessment, but there are a few potential limitations and areas for further research:
-
Dataset and Annotation Quality: The performance of the model is heavily dependent on the quality and representativeness of the training data, including the human-annotated pronunciation scores. Ensuring the dataset captures a diverse range of speakers and pronunciation patterns is crucial.
-
Generalization to Real-world Scenarios: The researchers evaluate the model on a controlled dataset, but it's important to understand how well the approach would generalize to more realistic, noisy, or unseen speaking scenarios.
-
Interpretability and Feedback Quality: While the LLM-based approach can provide detailed feedback, it's important to ensure the feedback is clear, actionable, and meaningful for language learners. Incorporating human-interpretable scoring models may be a valuable direction to explore.
-
Multimodal Integration Challenges: Effectively combining audio and text inputs is a non-trivial task, and the researchers' findings on the most effective integration strategies could be further explored and validated.
Overall, this research represents an exciting step towards leveraging the capabilities of prompted LLMs and multimodal LLMs for language assessment and learning applications.
Conclusion
This paper presents a novel approach to pronunciation assessment that combines multimodal inputs (audio and text) with the language understanding and generation capabilities of large language models. The proposed method has the potential to provide scalable, personalized, and detailed feedback on pronunciation proficiency, which could be particularly valuable for language learners and in various educational and professional contexts.
While the research shows promising results, there are several areas for further exploration, such as dataset quality, model generalization, and the interpretability of the feedback. Addressing these challenges could lead to even more effective and impactful applications of large language models in the field of language learning and assessment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pronunciation Assessment with Multi-modal Large Language Models
Kaiqi Fu, Linkai Peng, Nan Yang, Shuran Zhou
Large language models (LLMs), renowned for their powerful conversational abilities, are widely recognized as exceptional tools in the field of education, particularly in the context of automated intelligent instruction systems for language learning. In this paper, we propose a scoring system based on LLMs, motivated by their positive impact on text-related scoring tasks. Specifically, the speech encoder first maps the learner's speech into contextual features. The adapter layer then transforms these features to align with the text embedding in latent space. The assessment task-specific prefix and prompt text are embedded and concatenated with the features generated by the modality adapter layer, enabling the LLMs to predict accuracy and fluency scores. Our experiments demonstrate that the proposed scoring systems achieve competitive results compared to the baselines on the Speechocean762 datasets. Moreover, we also conducted an ablation study to better understand the contributions of the prompt text and training strategy in the proposed scoring system.
Read more7/19/2024
💬
0
Exploring the Capabilities of Prompted Large Language Models in Educational and Assessment Applications
Subhankar Maity, Aniket Deroy, Sudeshna Sarkar
In the era of generative artificial intelligence (AI), the fusion of large language models (LLMs) offers unprecedented opportunities for innovation in the field of modern education. We embark on an exploration of prompted LLMs within the context of educational and assessment applications to uncover their potential. Through a series of carefully crafted research questions, we investigate the effectiveness of prompt-based techniques in generating open-ended questions from school-level textbooks, assess their efficiency in generating open-ended questions from undergraduate-level technical textbooks, and explore the feasibility of employing a chain-of-thought inspired multi-stage prompting approach for language-agnostic multiple-choice question (MCQ) generation. Additionally, we evaluate the ability of prompted LLMs for language learning, exemplified through a case study in the low-resource Indian language Bengali, to explain Bengali grammatical errors. We also evaluate the potential of prompted LLMs to assess human resource (HR) spoken interview transcripts. By juxtaposing the capabilities of LLMs with those of human experts across various educational tasks and domains, our aim is to shed light on the potential and limitations of LLMs in reshaping educational practices.
Read more5/21/2024
0
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, Furu Wei
The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at url{aka.ms/wavllm}.
Read more8/15/2024
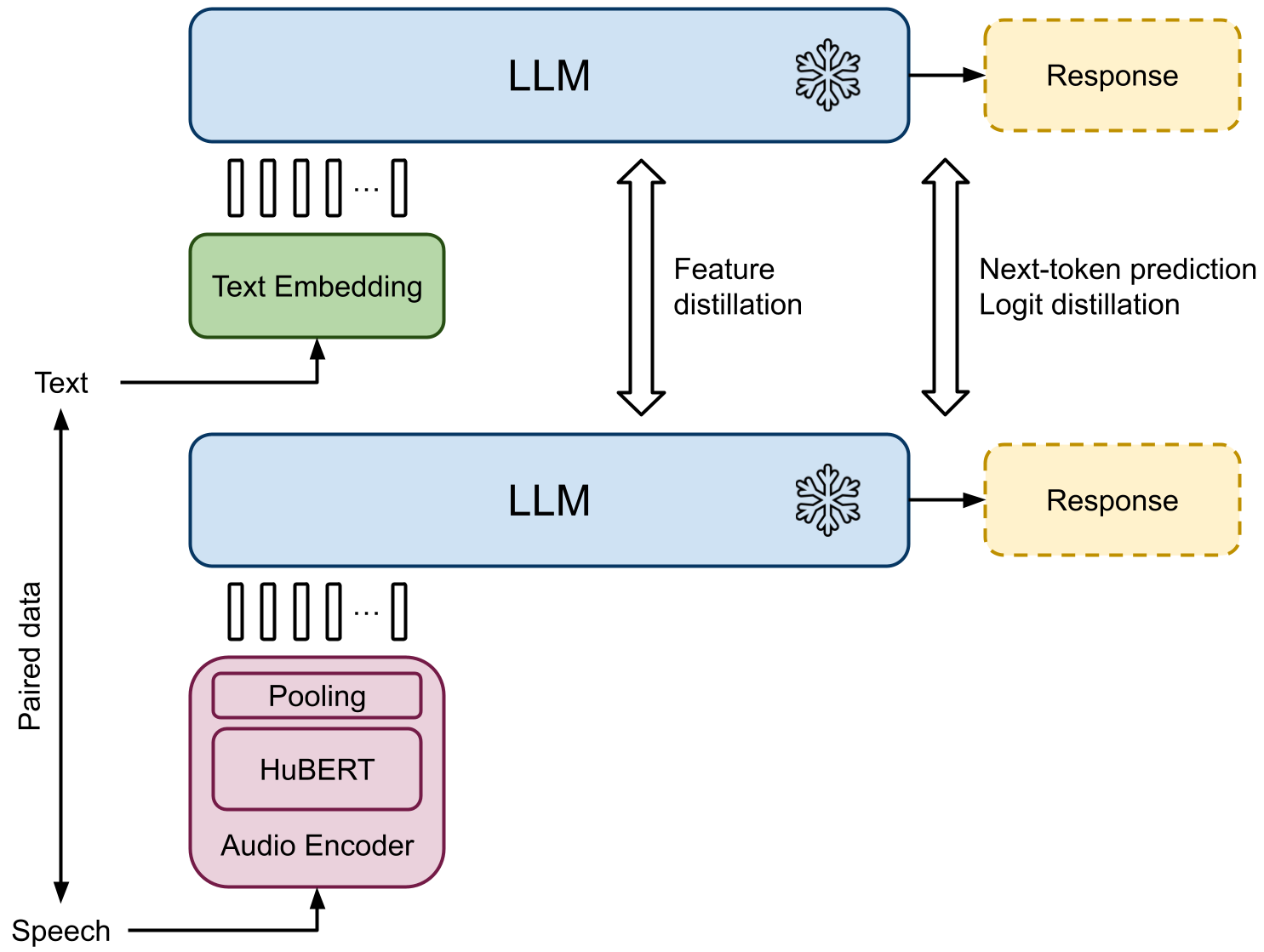
0
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
Read more6/11/2024