Enabling Elastic Model Serving with MultiWorld

0

Sign in to get full access
Overview
- The paper proposes a system called "MultiWorld" that enables elastic model serving, allowing for dynamic scaling of model resources to meet changing demands.
- MultiWorld introduces techniques to efficiently manage and optimize the deployment of multiple ML models across a distributed infrastructure.
- The system aims to improve the cost-effectiveness and scalability of model serving compared to traditional approaches.
Plain English Explanation
Towards Universal Performance Modeling for Machine Learning Training and MAD-MAX: Beyond Single-Node Enabling Large have highlighted the challenges of effectively deploying and scaling machine learning (ML) models in production environments. CascadeServe: Unlocking Model Cascades for Inference Serving and the Survey of Distributed Learning in Cloud, Mobile, and Edge Settings have also explored ways to optimize the deployment and inference of ML models.
Building on these insights, the "MultiWorld" system aims to make it easier and more efficient to serve multiple ML models in a dynamic, scalable manner. The key idea is to provide a framework that can automatically adjust the resources (e.g., compute, memory) allocated to different models based on changing demand, without requiring manual intervention or complex configuration.
This could be particularly useful for applications that need to handle fluctuating workloads or support a diverse set of ML models. By dynamically scaling resources, MultiWorld can help ensure that models are served efficiently and cost-effectively, without over-provisioning or under-provisioning.
The paper introduces several technical innovations to enable this elastic model serving capability, including novel resource management and optimization algorithms. The authors also demonstrate the performance and cost benefits of MultiWorld through experiments and case studies.
Technical Explanation
EdgeShard: Efficient LLM Inference via Collaborative Edge has explored techniques for optimizing the deployment of large language models (LLMs) in edge computing environments. The MultiWorld system builds on these ideas to provide a more general framework for managing the serving of diverse ML models in a distributed infrastructure.
At a high level, MultiWorld consists of several key components:
- Resource Management: A system for monitoring and allocating compute, memory, and other resources across multiple ML models running on a distributed infrastructure.
- Model Placement Optimization: Algorithms to determine the optimal placement of models on available servers or nodes, considering factors like resource availability, latency, and cost.
- Dynamic Scaling: Mechanisms to automatically scale the resources allocated to individual models up or down based on changing demand, without disrupting ongoing inference requests.
- Multi-Tenant Isolation: Techniques to ensure that different models or customers are isolated from each other, maintaining performance and security guarantees.
The paper describes the design and implementation of these components, as well as the experiments conducted to evaluate MultiWorld's performance and cost-efficiency. The authors demonstrate how MultiWorld can outperform traditional model serving approaches, particularly in scenarios with highly variable workloads or a diverse set of ML models.
Critical Analysis
The paper provides a comprehensive overview of the MultiWorld system and the technical innovations it introduces. The authors have clearly identified the challenges of effective model serving at scale and have proposed a thoughtful solution to address these issues.
One potential area for further research could be the integration of MultiWorld with emerging techniques for edge-based or federated machine learning, as described in EdgeShard: Efficient LLM Inference via Collaborative Edge. Combining MultiWorld's elastic model serving capabilities with edge computing resources could unlock new opportunities for low-latency, distributed inference.
Additionally, the authors could explore ways to further optimize the resource management and model placement algorithms, potentially incorporating knowledge about the expected workloads or characteristics of the deployed models. This could lead to even greater cost savings and performance improvements.
Overall, the MultiWorld system presents a compelling approach to the challenge of model serving at scale, and the paper provides a solid technical foundation for further research and development in this area.
Conclusion
The "Enabling Elastic Model Serving with MultiWorld" paper introduces a novel system that aims to address the challenges of effectively deploying and scaling machine learning models in production environments. By providing a framework for dynamic resource management, model placement optimization, and elastic scaling, MultiWorld promises to improve the cost-effectiveness and performance of model serving compared to traditional approaches.
The technical innovations described in the paper, such as the resource management and model placement algorithms, could have significant implications for a wide range of applications that rely on machine learning, from e-commerce personalization to autonomous vehicles. As the demand for deploying and serving diverse ML models continues to grow, systems like MultiWorld will become increasingly important for ensuring efficient and scalable model serving in production.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enabling Elastic Model Serving with MultiWorld
Myungjin Lee, Akshay Jajoo, Ramana Rao Kompella
Machine learning models have been exponentially growing in terms of their parameter size over the past few years. We are now seeing the rise of trillion-parameter models. The large models cannot fit into a single GPU and thus require partitioned deployment across GPUs and even hosts. A high-performance collective communication library (CCL) such as NCCL is essential to fully utilize expensive GPU resources. However, CCL is not a great fit for inference. Unlike training for which a fixed amount of GPU resources is used for fixed workloads (e.g., input datasets), the inference workloads can change dynamically over time. Failures at the serving time can also impact individual user's experiences directly. In contrast, workers in a CCL process group share a single fault domain and the process group cannot grow as the workloads increase. The gap between the unique characteristics of model serving and CCL's nature makes it hard to serve large models elastically. To bridge the gap, we propose MultiWorld that enables fault tolerance and online scaling at the granularity of workers for model serving. Our evaluation showcases that enabling these new functionalities incurs small overheads (1.4-4.3% throughput loss) for most of the scenarios we tested.
Read more7/15/2024
0
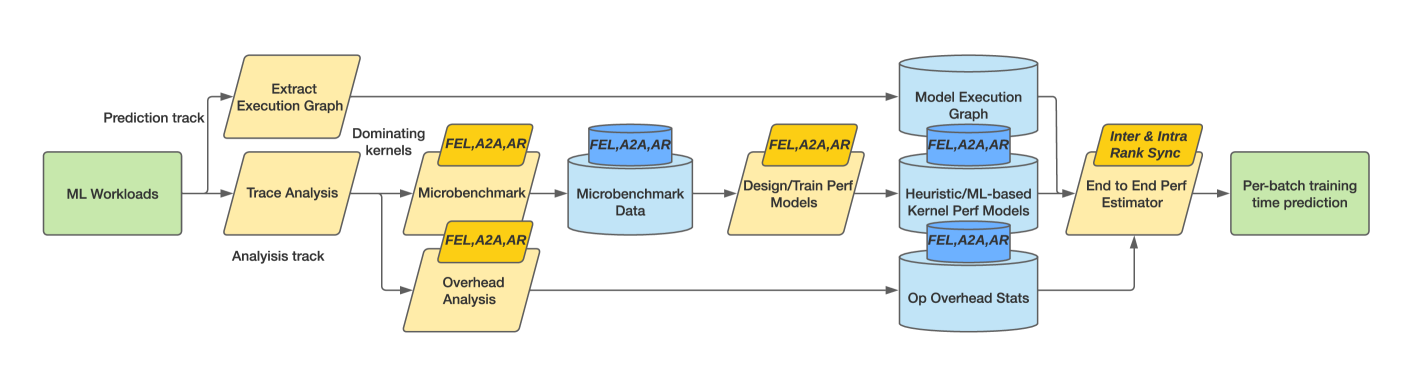
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Read more4/30/2024
📈
0
MAD Max Beyond Single-Node: Enabling Large Machine Learning Model Acceleration on Distributed Systems
Samuel Hsia, Alicia Golden, Bilge Acun, Newsha Ardalani, Zachary DeVito, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
Training and deploying large-scale machine learning models is time-consuming, requires significant distributed computing infrastructures, and incurs high operational costs. Our analysis, grounded in real-world large model training on datacenter-scale infrastructures, reveals that 14~32% of all GPU hours are spent on communication with no overlapping computation. To minimize this outstanding communication latency and other inherent at-scale inefficiencies, we introduce an agile performance modeling framework, MAD-Max. This framework is designed to optimize parallelization strategies and facilitate hardware-software co-design opportunities. Through the application of MAD-Max to a suite of real-world large-scale ML models on state-of-the-art GPU clusters, we showcase potential throughput enhancements of up to 2.24x for pre-training and up to 5.2x for inference scenarios, respectively.
Read more6/12/2024

0
CascadeServe: Unlocking Model Cascades for Inference Serving
Ferdi Kossmann, Ziniu Wu, Alex Turk, Nesime Tatbul, Lei Cao, Samuel Madden
Machine learning (ML) models are increasingly deployed to production, calling for efficient inference serving systems. Efficient inference serving is complicated by two challenges: (i) ML models incur high computational costs, and (ii) the request arrival rates of practical applications have frequent, high, and sudden variations which make it hard to correctly provision hardware. Model cascades are positioned to tackle both of these challenges, as they (i) save work while maintaining accuracy, and (ii) expose a high-resolution trade-off between work and accuracy, allowing for fine-grained adjustments to request arrival rates. Despite their potential, model cascades haven't been used inside an online serving system. This comes with its own set of challenges, including workload adaption, model replication onto hardware, inference scheduling, request batching, and more. In this work, we propose CascadeServe, which automates and optimizes end-to-end inference serving with cascades. CascadeServe operates in an offline and online phase. In the offline phase, the system pre-computes a gear plan that specifies how to serve inferences online. In the online phase, the gear plan allows the system to serve inferences while making near-optimal adaptations to the query load at negligible decision overheads. We find that CascadeServe saves 2-3x in cost across a wide spectrum of the latency-accuracy space when compared to state-of-the-art baselines on different workloads.
Read more6/21/2024