MAD Max Beyond Single-Node: Enabling Large Machine Learning Model Acceleration on Distributed Systems

0
📈
Sign in to get full access
Overview
- Training and deploying large-scale machine learning models is time-consuming and requires significant distributed computing infrastructure, which incurs high operational costs.
- Analysis of real-world large model training on datacenters reveals that 14-32% of GPU hours are spent on communication with no overlapping computation.
- To minimize communication latency and other inefficiencies at scale, the researchers introduce MAD-Max, a performance modeling framework to optimize parallelization strategies and facilitate hardware-software co-design.
Plain English Explanation
Building and running large-scale machine learning models requires a lot of time and expensive computer equipment. The researchers looked at real-world examples of training these large models on powerful data center computers. They found that 14-32% of the time spent using the computers' graphics processing units (GPUs) was just spent on transferring data between the different parts of the system, with no actual computations happening.
To try to reduce this wasted time and make the training process more efficient, the researchers created a new framework called MAD-Max. This framework is designed to help find the best ways to split up the work and run it in parallel on the available hardware. It also aims to uncover opportunities to better coordinate the software and hardware to work together more seamlessly.
The researchers tested MAD-Max on a variety of real-world large-scale machine learning models running on state-of-the-art GPU clusters. They were able to achieve potential throughput improvements of up to 2.24x for the initial model training and up to 5.2x for the final model's inference (making predictions).
Technical Explanation
The researchers' analysis, based on real-world large model training on datacenter-scale infrastructures, reveals that 14-32% of all GPU hours are spent on communication with no overlapping computation. To address this issue and other inherent inefficiencies at scale, the researchers introduce MAD-Max, a performance modeling framework designed to optimize parallelization strategies and facilitate hardware-software co-design opportunities.
MAD-Max employs a 4D hybrid algorithm to scale parallel training, as well as a heterogeneous distributed hybrid training system and a workload-aware hardware accelerator mining approach to improve communication efficiency in distributed deep learning.
Through the application of MAD-Max to a suite of real-world large-scale ML models on state-of-the-art GPU clusters, the researchers showcase potential throughput enhancements of up to 2.24x for pre-training and up to 5.2x for inference scenarios, respectively.
Critical Analysis
The paper provides a thorough analysis of the communication bottlenecks and inefficiencies encountered when training large-scale machine learning models on datacenter-scale infrastructures. The proposed MAD-Max framework seems well-designed to address these issues, leveraging a range of techniques to optimize parallelization and improve communication efficiency.
However, the paper does not delve deeply into the potential limitations or downsides of the MAD-Max approach. For example, it is unclear how the framework would scale to even larger models or more complex hardware configurations, or how it might interact with other optimization techniques that are commonly used in large-scale ML training.
Additionally, the paper does not provide much discussion of the broader implications of its findings or potential real-world applications beyond the specific technical context. Further research could explore how these insights and techniques might be applied to improve the accessibility and cost-effectiveness of large-scale machine learning for a wider range of users and use cases.
Conclusion
This paper presents a compelling analysis of the communication challenges faced when training large-scale machine learning models on datacenter-scale infrastructure. The researchers' introduction of the MAD-Max framework offers a promising approach to address these issues, with the potential to significantly improve the efficiency and throughput of both pre-training and inference for a range of real-world large-scale ML models. While the paper does not explore all possible limitations, it represents an important step towards more effective and accessible large-scale machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
MAD Max Beyond Single-Node: Enabling Large Machine Learning Model Acceleration on Distributed Systems
Samuel Hsia, Alicia Golden, Bilge Acun, Newsha Ardalani, Zachary DeVito, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
Training and deploying large-scale machine learning models is time-consuming, requires significant distributed computing infrastructures, and incurs high operational costs. Our analysis, grounded in real-world large model training on datacenter-scale infrastructures, reveals that 14~32% of all GPU hours are spent on communication with no overlapping computation. To minimize this outstanding communication latency and other inherent at-scale inefficiencies, we introduce an agile performance modeling framework, MAD-Max. This framework is designed to optimize parallelization strategies and facilitate hardware-software co-design opportunities. Through the application of MAD-Max to a suite of real-world large-scale ML models on state-of-the-art GPU clusters, we showcase potential throughput enhancements of up to 2.24x for pre-training and up to 5.2x for inference scenarios, respectively.
Read more6/12/2024
0
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
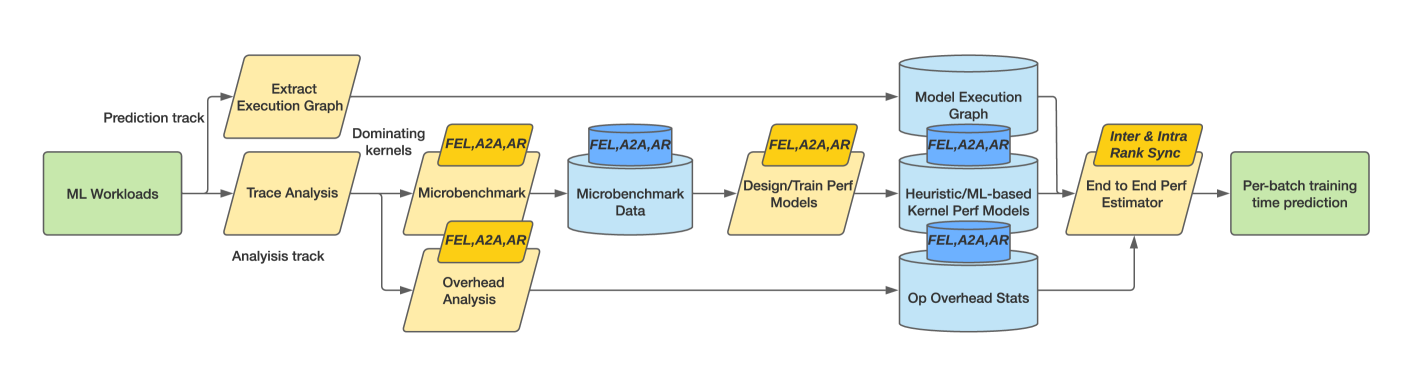
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Read more4/30/2024

0
Performance Modeling and Workload Analysis of Distributed Large Language Model Training and Inference
Joyjit Kundu, Wenzhe Guo, Ali BanaGozar, Udari De Alwis, Sourav Sengupta, Puneet Gupta, Arindam Mallik
Aligning future system design with the ever-increasing compute needs of large language models (LLMs) is undoubtedly an important problem in today's world. Here, we propose a general performance modeling methodology and workload analysis of distributed LLM training and inference through an analytical framework that accurately considers compute, memory sub-system, network, and various parallelization strategies (model parallel, data parallel, pipeline parallel, and sequence parallel). We validate our performance predictions with published data from literature and relevant industry vendors (e.g., NVIDIA). For distributed training, we investigate the memory footprint of LLMs for different activation re-computation methods, dissect the key factors behind the massive performance gain from A100 to B200 ($sim$ 35x speed-up closely following NVIDIA's scaling trend), and further run a design space exploration at different technology nodes (12 nm to 1 nm) to study the impact of logic, memory, and network scaling on the performance. For inference, we analyze the compute versus memory boundedness of different operations at a matrix-multiply level for different GPU systems and further explore the impact of DRAM memory technology scaling on inference latency. Utilizing our modeling framework, we reveal the evolution of performance bottlenecks for both LLM training and inference with technology scaling, thus, providing insights to design future systems for LLM training and inference.
Read more7/23/2024
🔍
0
A 4D Hybrid Algorithm to Scale Parallel Training to Thousands of GPUs
Siddharth Singh, Prajwal Singhania, Aditya K. Ranjan, Zack Sating, Abhinav Bhatele
Heavy communication, in particular, collective operations, can become a critical performance bottleneck in scaling the training of billion-parameter neural networks to large-scale parallel systems. This paper introduces a four-dimensional (4D) approach to optimize communication in parallel training. This 4D approach is a hybrid of 3D tensor and data parallelism, and is implemented in the AxoNN framework. In addition, we employ two key strategies to further minimize communication overheads. First, we aggressively overlap expensive collective operations (reduce-scatter, all-gather, and all-reduce) with computation. Second, we develop an analytical model to identify high-performing configurations within the large search space defined by our 4D algorithm. This model empowers practitioners by simplifying the tuning process for their specific training workloads. When training an 80-billion parameter GPT on 1024 GPUs of Perlmutter, AxoNN surpasses Megatron-LM, a state-of-the-art framework, by a significant 26%. Additionally, it achieves a significantly high 57% of the theoretical peak FLOP/s or 182 PFLOP/s in total.
Read more5/15/2024