Enabling Small Models for Zero-Shot Classification through Model Label Learning

0

Sign in to get full access
Overview
- The paper explores how to enable small language models to perform zero-shot classification tasks by learning to generate appropriate labels.
- It introduces a novel training approach called Model Label Learning (MLL) that allows smaller models to match the zero-shot performance of larger models.
- The key idea is to train the model to generate labels that match those produced by a larger pre-trained model, rather than directly predicting the classes.
Plain English Explanation
The research paper looks at a problem faced by small language models - their inability to perform zero-shot classification. Zero-shot classification is the ability to classify data into categories without being explicitly trained on those categories. Larger language models can do this, but smaller models struggle.
The researchers developed a new training approach called Model Label Learning (MLL) that teaches smaller models to generate labels that match those of a larger pre-trained model. By focusing on generating the right labels, rather than directly predicting the classes, the smaller models are able to achieve comparable zero-shot performance to their larger counterparts.
The key insight is that it's easier for a small model to learn to mimic the label generation of a larger model, rather than trying to directly replicate the classification capabilities of the larger model. This "indirect" approach allows the smaller model to leverage the knowledge encoded in the larger model's labels, without having to match its full complexity.
Technical Explanation
The paper introduces a novel training approach called Model Label Learning (MLL) that enables small language models to perform zero-shot classification. The core idea is to train the small model to generate label representations that match those produced by a larger pre-trained model, rather than directly predicting the classes.
Specifically, the authors first train a large pre-trained model (e.g. CLIP) on a diverse dataset to obtain high-quality label representations. They then freeze the label generation component of this larger model and use it to supervise the training of a smaller model. The smaller model is trained to minimize the distance between its generated labels and those of the larger model.
By focusing on label generation instead of direct classification, the smaller model is able to leverage the knowledge encoded in the larger model's labels, without having to match its full complexity. The authors demonstrate that this "indirect" approach allows the smaller model to achieve zero-shot performance on par with the larger model, across a range of benchmarks.
The key technical insights are:
- Label generation is an easier task for small models than direct classification
- Aligning the small model's labels with a pre-trained larger model allows it to inherit the larger model's zero-shot capabilities
- This "Model Label Learning" (MLL) approach is broadly applicable and can be combined with various model architectures and datasets
Critical Analysis
The paper presents a compelling approach to enabling small language models to perform zero-shot classification. The core idea of having the small model learn to generate labels that match a larger pre-trained model is both elegant and effective.
One potential limitation is that the success of this approach relies on the availability of a high-quality large pre-trained model (e.g. CLIP) that can serve as the "teacher" for the smaller model. If such a model is not available for a particular domain, the MLL approach may not be as effective.
Additionally, the paper does not explore the performance of the smaller model on downstream tasks beyond zero-shot classification. It would be valuable to understand how well the smaller model's learned label representations generalize to other applications, such as few-shot learning or open-ended language understanding.
Finally, the authors mention that the MLL approach can be combined with various model architectures and datasets, but they do not provide much detail on the specific architectural choices or training regimes that may be most effective. Further research in this direction could help guide practitioners on how to best apply the MLL approach in practice.
Overall, the paper presents a promising and well-executed approach to a important problem in the field of language models. The insights and techniques introduced could have significant implications for making large language models more accessible and deployable in real-world applications.
Conclusion
The paper "Enabling Small Models for Zero-Shot Classification through Model Label Learning" addresses a key challenge in the field of language models - how to enable smaller models to match the zero-shot classification capabilities of larger, more complex models.
The researchers introduce a novel training approach called Model Label Learning (MLL) that allows smaller models to learn to generate label representations that closely match those of a larger pre-trained model. By focusing on this "indirect" task of label generation rather than direct classification, the smaller models are able to leverage the knowledge encoded in the larger model's labels and achieve comparable zero-shot performance.
The technical insights and empirical results presented in this paper could have significant implications for making large language models more accessible and deployable in a wider range of real-world applications. The MLL approach provides a compelling pathway for democratizing the power of state-of-the-art language understanding, opening up new possibilities for how these transformative technologies can be applied.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enabling Small Models for Zero-Shot Classification through Model Label Learning
Jia Zhang, Zhi Zhou, Lan-Zhe Guo, Yu-Feng Li
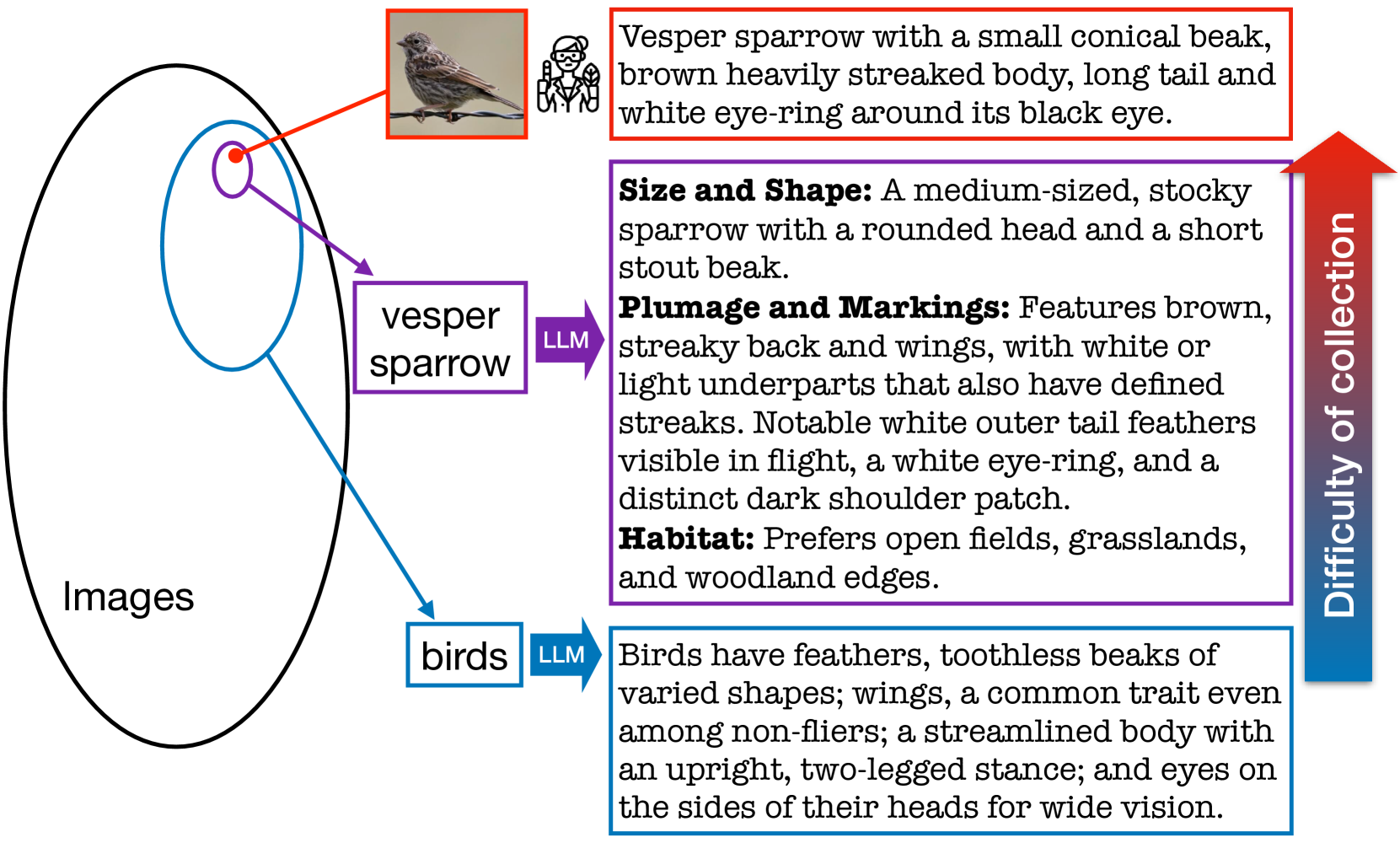
Vision-language models (VLMs) like CLIP have demonstrated impressive zero-shot ability in image classification tasks by aligning text and images but suffer inferior performance compared with task-specific expert models. On the contrary, expert models excel in their specialized domains but lack zero-shot ability for new tasks. How to obtain both the high performance of expert models and zero-shot ability is an important research direction. In this paper, we attempt to demonstrate that by constructing a model hub and aligning models with their functionalities using model labels, new tasks can be solved in a zero-shot manner by effectively selecting and reusing models in the hub. We introduce a novel paradigm, Model Label Learning (MLL), which bridges the gap between models and their functionalities through a Semantic Directed Acyclic Graph (SDAG) and leverages an algorithm, Classification Head Combination Optimization (CHCO), to select capable models for new tasks. Compared with the foundation model paradigm, it is less costly and more scalable, i.e., the zero-shot ability grows with the sizes of the model hub. Experiments on seven real-world datasets validate the effectiveness and efficiency of MLL, demonstrating that expert models can be effectively reused for zero-shot tasks. Our code will be released publicly.
Read more8/22/2024
0
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
Read more4/5/2024
🏷️
0
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Yassir Bendou, Giulia Lioi, Bastien Pasdeloup, Lukas Mauch, Ghouthi Boukli Hacene, Fabien Cardinaux, Vincent Gripon
We consider the problem of zero-shot one-class visual classification, extending traditional one-class classification to scenarios where only the label of the target class is available. This method aims to discriminate between positive and negative query samples without requiring examples from the target class. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. To our knowledge, we are the first to demonstrate the ability to discriminate a single category from other semantically related ones using only its label.
Read more5/28/2024

0
Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Zhaoheng Zheng, Jingmin Wei, Xuefeng Hu, Haidong Zhu, Ram Nevatia
Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets. Code will be made available at: https://github.com/zhaohengz/LLaMP.
Read more4/4/2024