Enabling Weak LLMs to Judge Response Reliability via Meta Ranking
2402.12146
0
0
🤖
Abstract
Despite the strong performance of large language models (LLMs) across a wide range of tasks, they still have reliability issues. Previous studies indicate that strong LLMs like GPT-4-turbo excel in evaluating the reliability of responses from LLMs, but face efficiency and local deployment issues. Thus, to enable weak LLMs to effectively assess the reliability of LLM responses, we propose a novel cross-query-comparison-based method called $textit{Meta Ranking}$ (MR). Unlike previous few-shot methods that solely based on in-context learning capabilities in LLMs, MR assesses reliability by pairwisely ranking the target query-response pair with multiple reference query-response pairs. We found that MR is highly effective in error detection for LLM responses, where weak LLMs, such as Phi-2, could surpass strong baselines like GPT-3.5-turbo, requiring only five reference samples and significantly improving efficiency. We further demonstrate that MR can enhance strong LLMs' performance in two practical applications: model cascading and instruction tuning. In model cascading, we combine open- and closed-source LLMs to achieve performance comparable to GPT-4-turbo with lower costs. In instruction tuning, we use MR for iterative training data filtering, significantly reducing data processing time and enabling LLaMA-7B and Phi-2 to surpass Alpaca-13B with fewer training tokens. These results underscore the high potential of MR in both efficiency and effectiveness.
Create account to get full access
Overview
- Large language models (LLMs) have shown strong performance across many tasks, but still face reliability issues.
- Previous studies indicate that strong LLMs like GPT-4-turbo can effectively evaluate the reliability of other LLM responses, but face efficiency and deployment challenges.
- To enable weaker LLMs to assess the reliability of LLM responses, the authors propose a novel method called Meta Ranking (MR).
- MR assesses reliability by pairwise ranking the target query-response pair with multiple reference query-response pairs, unlike previous few-shot methods that rely on in-context learning.
Plain English Explanation
Large language models (LLMs) are sophisticated AI systems that can perform a wide variety of tasks, from answering questions to generating human-like text. While these models have shown impressive capabilities, they still struggle with reliability - they can sometimes produce responses that are inaccurate, inconsistent, or biased.
To address this issue, the researchers propose a new method called Meta Ranking (MR). Unlike previous approaches that rely on the in-context learning abilities of strong LLMs, MR assesses reliability by comparing the target query-response pair to multiple reference pairs. This allows weaker LLMs, like the Phi-2 model, to effectively detect errors in LLM responses, even outperforming stronger baselines like GPT-3.5-turbo.
The researchers also demonstrate that MR can enhance the performance of strong LLMs in practical applications, such as model cascading (combining open- and closed-source LLMs) and instruction tuning (iterative training data filtering). These results suggest that MR could be a powerful tool for improving the reliability and efficiency of LLM systems.
Technical Explanation
The key idea behind the Meta Ranking (MR) method is to assess the reliability of an LLM's response by comparing it to multiple reference query-response pairs, rather than relying solely on the in-context learning capabilities of the LLM itself.
The MR process works as follows:
- The target query-response pair is pairwise ranked against multiple reference query-response pairs.
- The ranking scores are then used to determine the reliability of the target response.
Unlike previous few-shot methods that focus on in-context learning, MR takes a more comparative approach, leveraging the ability of even weaker LLMs to effectively detect errors in LLM responses. The researchers found that a weaker model like Phi-2 could outperform stronger baselines like GPT-3.5-turbo on error detection tasks, while requiring only five reference samples and significantly improving efficiency.
The researchers further demonstrate the practical applications of MR in two key areas:
- Model Cascading: By combining open- and closed-source LLMs, the researchers were able to achieve performance comparable to GPT-4-turbo, but at a lower cost.
- Instruction Tuning: The researchers used MR for iterative training data filtering, significantly reducing data processing time and enabling LLaMA-7B and Phi-2 to surpass the performance of the larger Alpaca-13B model with fewer training tokens.
These results highlight the potential of the MR approach to improve the reliability and efficiency of LLM systems, making them more accessible and deployable in real-world applications.
Critical Analysis
The proposed Meta Ranking (MR) method offers a promising approach to improving the reliability of LLM responses, especially for weaker models that may struggle with in-context learning. The researchers provide compelling evidence that MR can effectively detect errors in LLM outputs, outperforming stronger baselines in certain scenarios.
However, the paper does not fully address the potential limitations and challenges of the MR approach. For example, the reliance on reference query-response pairs raises questions about the scalability and generalization of the method, as curating a comprehensive set of diverse reference samples could be labor-intensive and context-dependent.
Additionally, the paper does not explore the potential biases or inconsistencies that could arise in the MR process, where the ranking of responses may be influenced by the specific choice and quality of the reference samples. Further research may be needed to understand the robustness and limitations of the MR approach in different real-world applications.
It would also be valuable to see a more detailed analysis of the computational and memory requirements of the MR method, as well as its performance on a broader range of LLM architectures and tasks, to better assess its overall effectiveness and practical implications.
Overall, the Meta Ranking (MR) method represents an interesting and potentially impactful contribution to the ongoing efforts to improve the reliability of large language models. However, continued research and critical evaluation will be essential to fully understand the strengths, weaknesses, and broader applicability of this approach.
Conclusion
The proposed Meta Ranking (MR) method offers a novel approach to addressing the reliability issues of large language models (LLMs). By leveraging a comparative, cross-query-based assessment, MR enables even weaker LLMs to effectively detect errors in the responses of stronger models, outperforming previous few-shot methods.
The researchers demonstrate the practical benefits of MR in two key areas: model cascading and instruction tuning. These results suggest that MR could be a valuable tool for enhancing the efficiency and performance of LLM systems, making them more accessible and deployable in real-world applications.
While the MR approach shows promising potential, further research is needed to fully understand its limitations, robustness, and broader applicability. Nonetheless, this work represents an important contribution to the ongoing efforts to improve the reliability and trustworthiness of large language models, which are increasingly becoming central to a wide range of AI-powered technologies and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
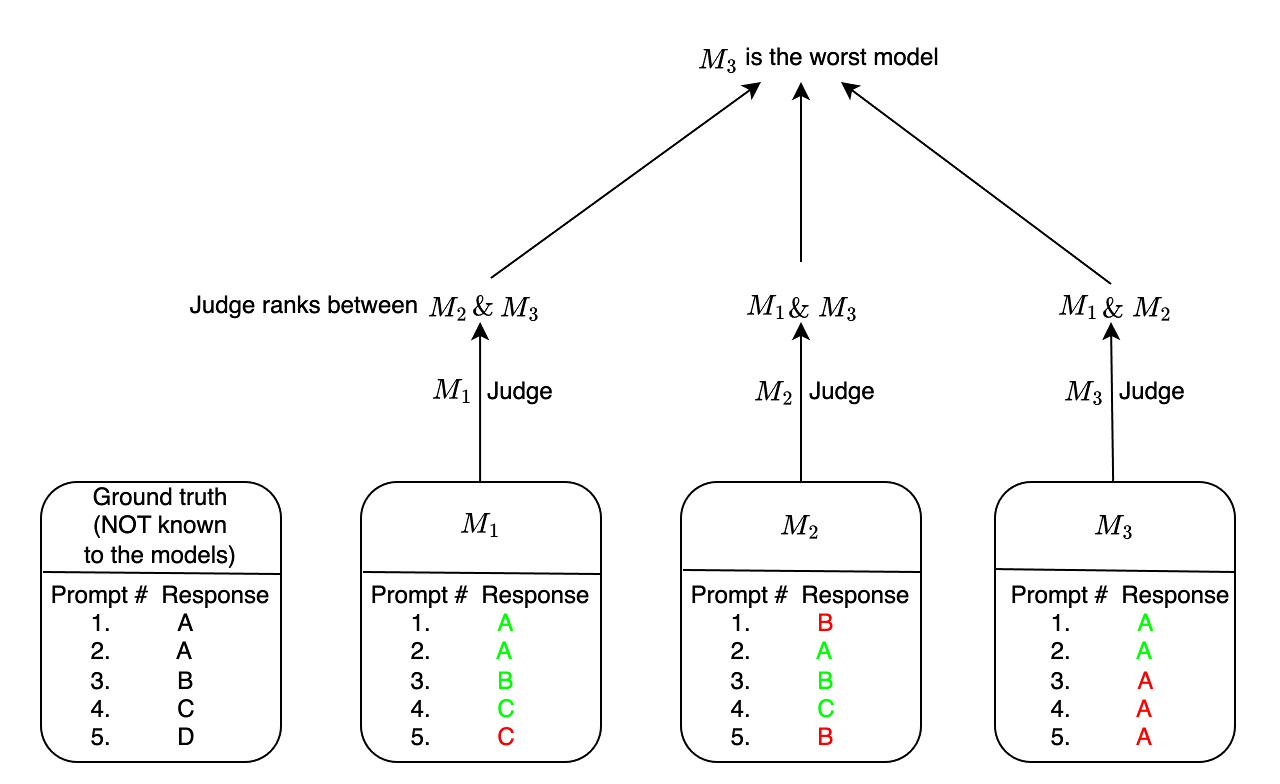
Ranking Large Language Models without Ground Truth
Amit Dhurandhar, Rahul Nair, Moninder Singh, Elizabeth Daly, Karthikeyan Natesan Ramamurthy
0
0
Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
6/11/2024
📶
Enhancing Trust in LLMs: Algorithms for Comparing and Interpreting LLMs
Nik Bear Brown
0
0
This paper surveys evaluation techniques to enhance the trustworthiness and understanding of Large Language Models (LLMs). As reliance on LLMs grows, ensuring their reliability, fairness, and transparency is crucial. We explore algorithmic methods and metrics to assess LLM performance, identify weaknesses, and guide development towards more trustworthy applications. Key evaluation metrics include Perplexity Measurement, NLP metrics (BLEU, ROUGE, METEOR, BERTScore, GLEU, Word Error Rate, Character Error Rate), Zero-Shot and Few-Shot Learning Performance, Transfer Learning Evaluation, Adversarial Testing, and Fairness and Bias Evaluation. We introduce innovative approaches like LLMMaps for stratified evaluation, Benchmarking and Leaderboards for competitive assessment, Stratified Analysis for in-depth understanding, Visualization of Blooms Taxonomy for cognitive level accuracy distribution, Hallucination Score for quantifying inaccuracies, Knowledge Stratification Strategy for hierarchical analysis, and Machine Learning Models for Hierarchy Generation. Human Evaluation is highlighted for capturing nuances that automated metrics may miss. These techniques form a framework for evaluating LLMs, aiming to enhance transparency, guide development, and establish user trust. Future papers will describe metric visualization and demonstrate each approach on practical examples.
6/5/2024

New!Improving Weak-to-Strong Generalization with Reliability-Aware Alignment
Yue Guo, Yi Yang
0
0
Large language models (LLMs) are now rapidly advancing and surpassing human abilities on many natural language tasks. However, aligning these super-human LLMs with human knowledge remains challenging because the supervision signals from human annotators may be wrong. This issue, known as the super-alignment problem, requires enhancing weak-to-strong generalization, where a strong LLM must generalize from imperfect supervision provided by a weaker source. To address this issue, we propose an approach to improve weak-to-strong generalization by involving the reliability of weak supervision signals in the alignment process. In our method, we query the weak supervisor for multiple answers, estimate the answer reliability, and enhance the alignment process by filtering out uncertain data or re-weighting reliable data. Experiments on four datasets demonstrate that our methods effectively identify the quality of weak labels and significantly enhance weak-to-strong generalization. Our work presents effective techniques for error-robust model alignment, reducing error propagation from noisy supervision and enhancing the accuracy and reliability of LLMs. Codes are publicly available at http://github.com/Irenehere/ReliableAlignment.
6/28/2024