Enchanting Program Specification Synthesis by Large Language Models using Static Analysis and Program Verification
2404.00762
0
0
Abstract
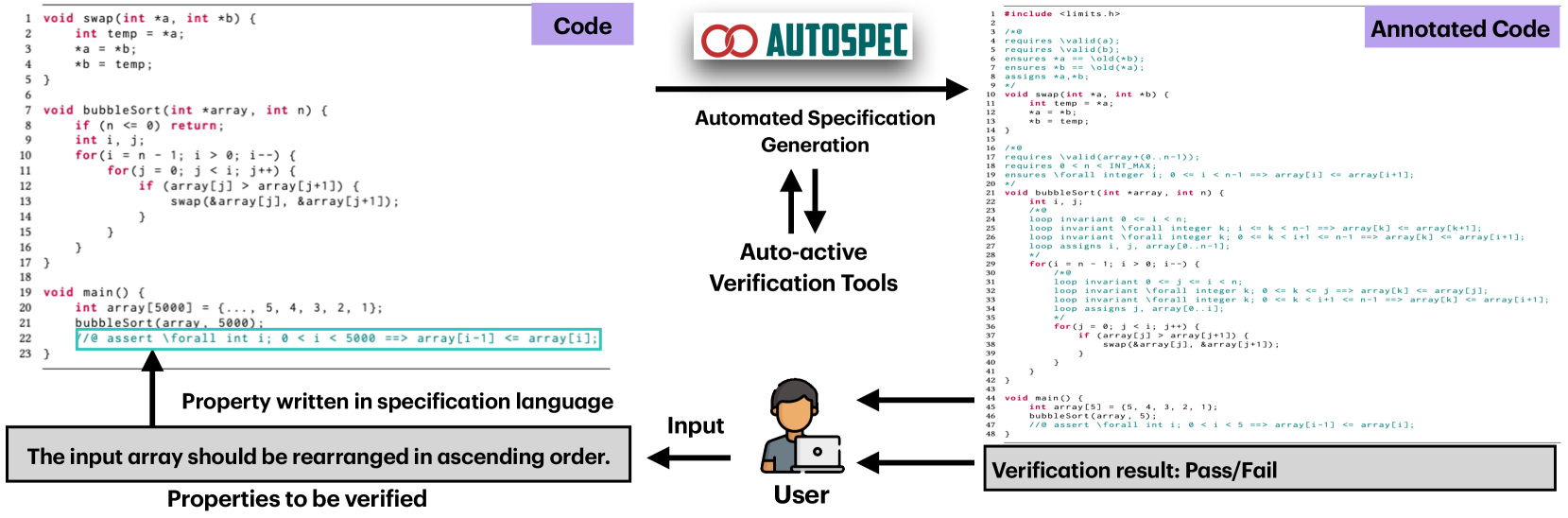
Formal verification provides a rigorous and systematic approach to ensure the correctness and reliability of software systems. Yet, constructing specifications for the full proof relies on domain expertise and non-trivial manpower. In view of such needs, an automated approach for specification synthesis is desired. While existing automated approaches are limited in their versatility, i.e., they either focus only on synthesizing loop invariants for numerical programs, or are tailored for specific types of programs or invariants. Programs involving multiple complicated data types (e.g., arrays, pointers) and code structures (e.g., nested loops, function calls) are often beyond their capabilities. To help bridge this gap, we present AutoSpec, an automated approach to synthesize specifications for automated program verification. It overcomes the shortcomings of existing work in specification versatility, synthesizing satisfiable and adequate specifications for full proof. It is driven by static analysis and program verification, and is empowered by large language models (LLMs). AutoSpec addresses the practical challenges in three ways: (1) driving name by static analysis and program verification, LLMs serve as generators to generate candidate specifications, (2) programs are decomposed to direct the attention of LLMs, and (3) candidate specifications are validated in each round to avoid error accumulation during the interaction with LLMs. In this way, AutoSpec can incrementally and iteratively generate satisfiable and adequate specifications. The evaluation shows its effectiveness and usefulness, as it outperforms existing works by successfully verifying 79% of programs through automatic specification synthesis, a significant improvement of 1.592x. It can also be successfully applied to verify the programs in a real-world X509-parser project.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a novel approach to synthesize program specifications using large language models, static analysis, and program verification techniques.
- The approach aims to automatically generate high-quality program specifications from natural language descriptions, which can then be used for program verification and other software engineering tasks.
- The method leverages the power of large language models to extract relevant information from natural language, and combines it with static analysis and program verification to produce formally-verified program specifications.
Plain English Explanation
The researchers have developed a new way to automatically generate detailed program specifications from simple natural language descriptions. Program specifications are formal documents that precisely describe what a computer program should do. They are essential for ensuring software quality and correctness, but they can be time-consuming and difficult to write.
The key idea is to use powerful AI language models, which have been trained on massive amounts of text data, to extract the relevant information from a natural language description of a program. This information is then combined with static code analysis and formal program verification techniques to produce a complete, mathematically-proven specification.
Imagine you want to write a program to calculate the area of a rectangle. You might describe it in plain English as "a program that takes the length and width of a rectangle as inputs, and outputs the area." An AI system following the approach in this paper could take that simple description, understand the relevant concepts (length, width, area), and then automatically generate a formal specification that precisely defines the program's behavior, including any edge cases or error handling.
This automated specification generation can save a lot of time and effort compared to manually writing specifications from scratch. It also helps ensure the specifications are accurate and comprehensive, by leveraging the strengths of both language models and formal verification techniques.
Technical Explanation
The core of the proposed approach is a three-stage process:
-
Natural Language Processing: A large language model, such as GPT-3, is used to extract relevant information from the natural language description of the program. This includes identifying the program's inputs, outputs, and high-level functionality.
-
Static Analysis: The extracted information is then combined with static analysis of the program's source code to further refine and validate the specification. Static analysis techniques can uncover additional details about the program's behavior, edge cases, and error handling.
-
Program Verification: Finally, the specification is formally verified using program verification tools. This ensures the specification is mathematically consistent and accurately captures the program's behavior.
The authors evaluate their approach on a suite of benchmark programs, demonstrating that it can generate high-quality specifications that are on par with or better than manually-written ones. The synthesized specifications are also shown to be effective for program verification tasks.
Critical Analysis
The paper presents a promising approach to automating the specification generation process, which can have significant practical implications for software development and verification. By leveraging the complementary strengths of language models, static analysis, and program verification, the method can produce comprehensive and accurate specifications in a scalable and efficient manner.
However, the approach also has some limitations that are worth considering. The performance of the method is likely dependent on the quality and coverage of the language model, as well as the availability of suitable static analysis and verification tools for the target programming language and domain. Additionally, the paper does not explore the generalization of the approach to more complex or domain-specific programs, which may require further innovations.
It would also be interesting to see how the method performs in the face of ambiguous, incomplete, or contradictory natural language descriptions, which are common in real-world software development scenarios. Addressing these challenges could further enhance the practical utility of the proposed approach.
Conclusion
The paper presents a novel and promising approach to automating the generation of program specifications using large language models, static analysis, and program verification. By combining these complementary techniques, the method can produce high-quality, formally-verified specifications from natural language descriptions, which can significantly streamline the software development and verification process.
The work highlights the potential of AI-powered tools to augment and enhance traditional software engineering practices, and opens up avenues for further research and development in this direction. As the field of program synthesis continues to evolve, approaches like the one described in this paper may play an increasingly important role in improving the efficiency, reliability, and quality of software systems.
Related Papers

Large Language Models Synergize with Automated Machine Learning
Jinglue Xu, Zhen Liu, Nagar Anthel Venkatesh Suryanarayanan, Hitoshi Iba
0
0
Recently, code generation driven by large language models (LLMs) has become increasingly popular. However, automatically generating code for machine learning (ML) tasks still poses significant challenges. This paper explores the limits of program synthesis for ML by combining LLMs and automated machine learning (autoML). Specifically, our goal is to fully automate the code generation process for the entire ML workflow, from data preparation to modeling and post-processing, utilizing only textual descriptions of the ML tasks. To manage the length and diversity of ML programs, we propose to break each ML program into smaller, manageable parts. Each part is generated separately by the LLM, with careful consideration of their compatibilities. To implement the approach, we design a testing technique for ML programs. Furthermore, our approach enables integration with autoML. In our approach, autoML serves to numerically assess and optimize the ML programs generated by LLMs. LLMs, in turn, help to bridge the gap between theoretical, algorithm-centered autoML and practical autoML applications. This mutual enhancement underscores the synergy between LLMs and autoML in program synthesis for ML. In experiments across various ML tasks, our method outperforms existing methods in 10 out of 12 tasks for generating ML programs. In addition, autoML significantly improves the performance of the generated ML programs. In the experiments, our method, Text-to-ML, achieves fully automated synthesis of the entire ML pipeline based solely on textual descriptions of the ML tasks.
5/8/2024
Lemur: Integrating Large Language Models in Automated Program Verification
Haoze Wu, Clark Barrett, Nina Narodytska
0
0
The demonstrated code-understanding capability of LLMs raises the question of whether they can be used for automated program verification, a task that demands high-level abstract reasoning about program properties that is challenging for verification tools. We propose a general methodology to combine the power of LLMs and automated reasoners for automated program verification. We formally describe this methodology as a set of transition rules and prove its soundness. We instantiate the calculus as a sound automated verification procedure and demonstrate practical improvements on a set of synthetic and competition benchmarks.
4/26/2024
Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming
Saikat Chakraborty, Gabriel Ebner, Siddharth Bhat, Sarah Fakhoury, Sakina Fatima, Shuvendu Lahiri, Nikhil Swamy
0
0
Proof-oriented programs mix computational content with proofs of program correctness. However, the human effort involved in programming and proving is still substantial, despite the use of Satisfiability Modulo Theories (SMT) solvers to automate proofs in languages such as F*. Seeking to spur research on using AI to automate the construction of proof-oriented programs, we curate a dataset of 600K lines of open-source F* programs and proofs, including software used in production systems ranging from Windows and Linux, to Python and Firefox. Our dataset includes around 32K top-level F* definitions, each representing a type-directed program and proof synthesis problem -- producing a definition given a formal specification expressed as an F* type. We provide a program-fragment checker that queries F* to check the correctness of candidate solutions. We believe this is the largest corpus of SMT-assisted program proofs coupled with a reproducible program-fragment checker. Grounded in this dataset, we investigate the use of AI to synthesize programs and their proofs in F*, with promising results. Our main finding in that the performance of fine-tuned smaller language models (such as Phi-2 or StarCoder) compare favorably with large language models (such as GPT-4), at a much lower computational cost. We also identify various type-based retrieval augmentation techniques and find that they boost performance significantly. With detailed error analysis and case studies, we identify potential strengths and weaknesses of models and techniques and suggest directions for future improvements.
5/6/2024

AutoCodeRover: Autonomous Program Improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, Abhik Roychoudhury
0
0
Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.
4/16/2024