Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming
2405.01787
0
0
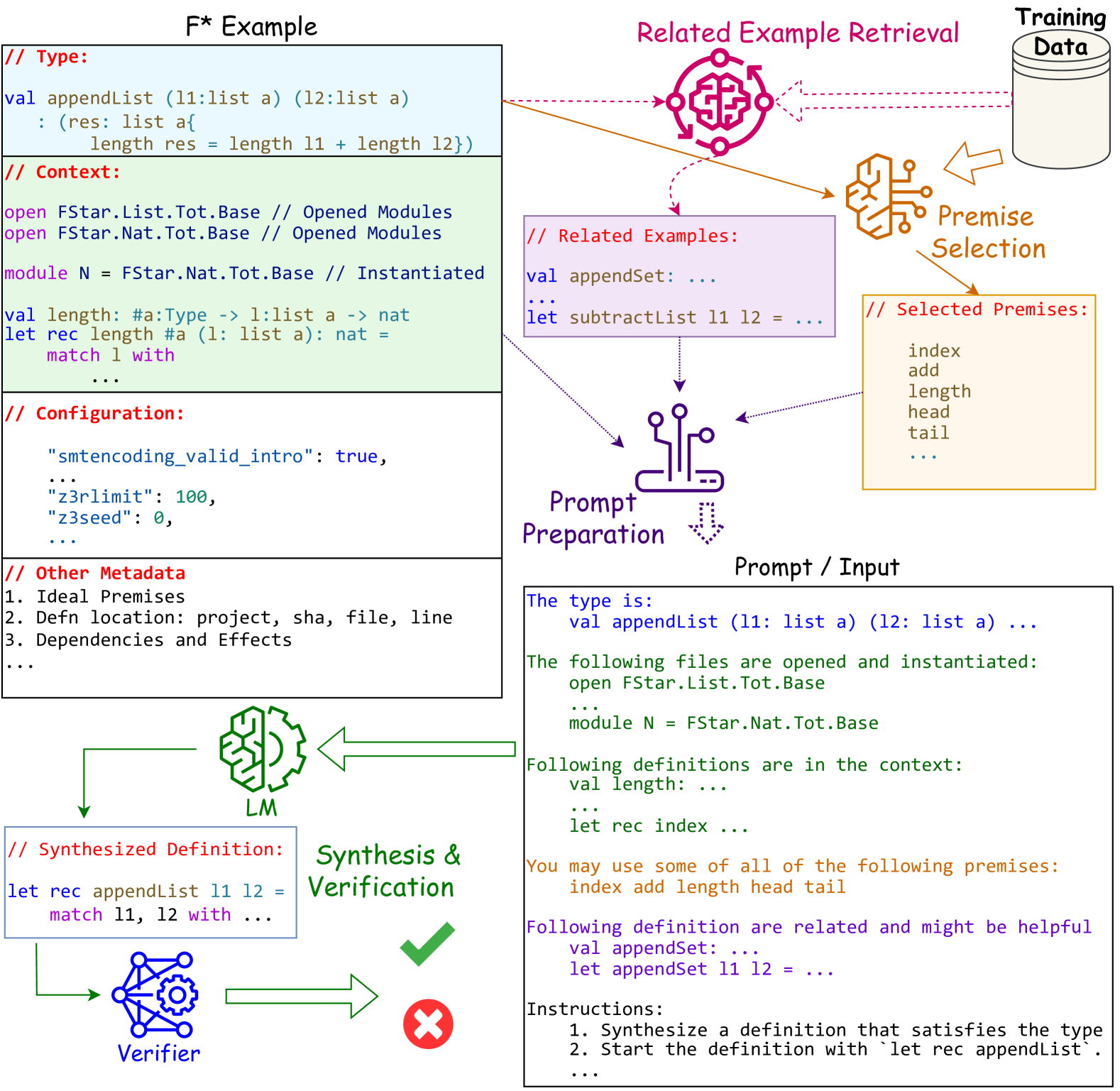
Abstract
Proof-oriented programs mix computational content with proofs of program correctness. However, the human effort involved in programming and proving is still substantial, despite the use of Satisfiability Modulo Theories (SMT) solvers to automate proofs in languages such as F*. Seeking to spur research on using AI to automate the construction of proof-oriented programs, we curate a dataset of 600K lines of open-source F* programs and proofs, including software used in production systems ranging from Windows and Linux, to Python and Firefox. Our dataset includes around 32K top-level F* definitions, each representing a type-directed program and proof synthesis problem -- producing a definition given a formal specification expressed as an F* type. We provide a program-fragment checker that queries F* to check the correctness of candidate solutions. We believe this is the largest corpus of SMT-assisted program proofs coupled with a reproducible program-fragment checker. Grounded in this dataset, we investigate the use of AI to synthesize programs and their proofs in F*, with promising results. Our main finding in that the performance of fine-tuned smaller language models (such as Phi-2 or StarCoder) compare favorably with large language models (such as GPT-4), at a much lower computational cost. We also identify various type-based retrieval augmentation techniques and find that they boost performance significantly. With detailed error analysis and case studies, we identify potential strengths and weaknesses of models and techniques and suggest directions for future improvements.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper explores the use of neural synthesis techniques to assist in proof-oriented programming, a paradigm focused on developing trustworthy software through formal verification.
• The research investigates how large language models and SMT (Satisfiability Modulo Theories) solvers can be leveraged to aid in the specification, synthesis, and verification of programs.
Plain English Explanation
The paper focuses on an approach called "proof-oriented programming," which is a way of developing software that is designed to be trustworthy and reliable. This is done by using formal verification, which means rigorously proving that the code meets certain specifications or requirements.
The researchers in this paper look at how they can use neural synthesis techniques and SMT solvers to help with the different steps of proof-oriented programming. This includes:
- Specification: Using large language models to help developers write clear and complete specifications for their programs.
- Synthesis: Generating candidate program implementations that satisfy the specifications, again with the help of language models.
- Verification: Leveraging SMT solvers to formally prove that the generated programs meet their specifications.
The key idea is to use these AI-powered tools to make proof-oriented programming more accessible and practical, so that developers can create software that is more reliable and trustworthy.
Technical Explanation
The paper proposes a framework that combines neural synthesis techniques with SMT-based verification to assist in proof-oriented programming. The core components include:
-
Specification Synthesis: The researchers explore using large language models to help developers write clear and complete formal specifications for their programs.
-
Program Synthesis: The system then generates candidate program implementations that satisfy the given specifications, leveraging neural program synthesis techniques like those explored in Enchanting.
-
Verification: Finally, the generated programs are passed to an SMT solver, which attempts to formally verify that they meet their specifications. This builds on ideas from Lemur and other work on integrating language models with automated reasoning.
The key innovations lie in the interplay between neural synthesis and SMT-based verification, as well as the specific techniques used to make this collaboration effective for proof-oriented programming.
Critical Analysis
The paper presents a promising approach, but also acknowledges several important caveats and areas for further research:
-
Scalability: The authors note that the current techniques may not scale well to large, complex programs, and additional work is needed to improve the efficiency of the verification process.
-
Trustworthiness: While the goal is to enable more trustworthy software, the paper recognizes that the use of neural models introduces new potential sources of uncertainty and error that must be carefully managed.
-
Generalization: The experiments in the paper focus on relatively narrow domains, and more research is needed to understand how well the techniques can generalize to a wider range of programming tasks and specifications.
Additionally, one could question whether the reliance on SMT solvers, which are themselves complex systems, truly addresses the core challenge of developing trustworthy software. Some researchers have argued for more fundamental rethinking of programming paradigms to achieve true trustworthiness.
Conclusion
This paper presents an intriguing approach to leveraging AI techniques to assist in proof-oriented programming, a paradigm focused on developing reliable and trustworthy software. By combining neural synthesis with SMT-based verification, the researchers aim to make formal specification and validation more accessible to developers.
While the work has important limitations and caveats, it represents a significant step forward in the quest to integrate large language models into the programming process. As the field of AI-assisted programming continues to evolve, this research contributes valuable insights and paves the way for further advancements in creating software that is both powerful and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
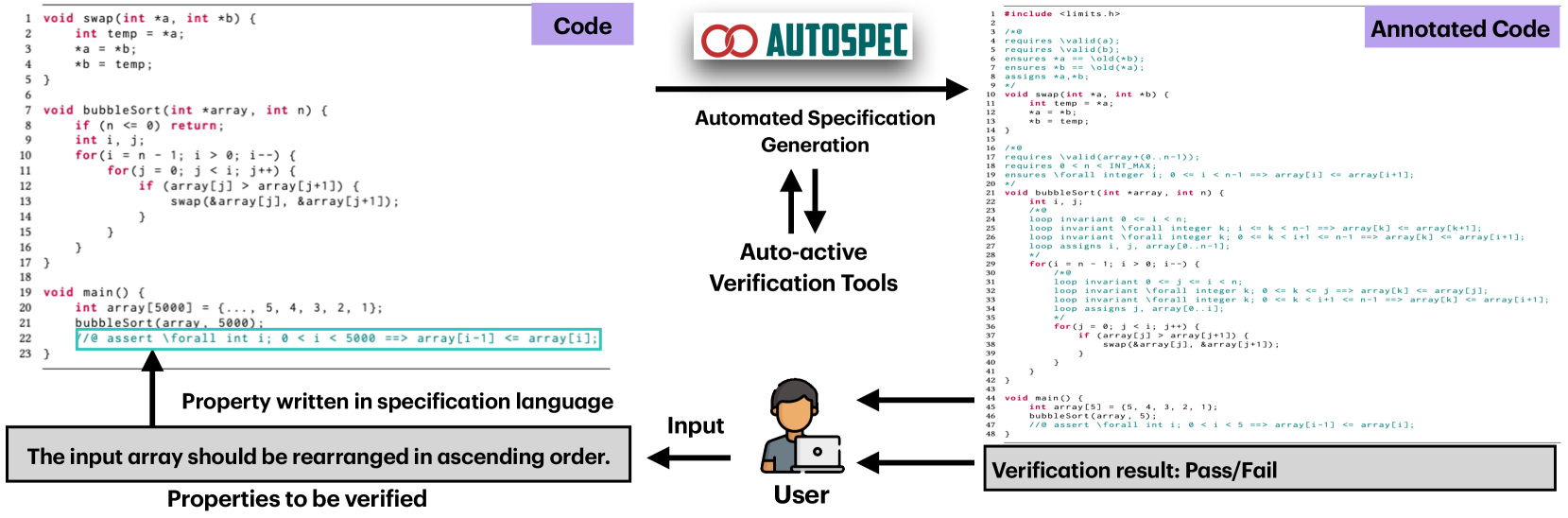
Enchanting Program Specification Synthesis by Large Language Models using Static Analysis and Program Verification
Cheng Wen, Jialun Cao, Jie Su, Zhiwu Xu, Shengchao Qin, Mengda He, Haokun Li, Shing-Chi Cheung, Cong Tian
0
0
Formal verification provides a rigorous and systematic approach to ensure the correctness and reliability of software systems. Yet, constructing specifications for the full proof relies on domain expertise and non-trivial manpower. In view of such needs, an automated approach for specification synthesis is desired. While existing automated approaches are limited in their versatility, i.e., they either focus only on synthesizing loop invariants for numerical programs, or are tailored for specific types of programs or invariants. Programs involving multiple complicated data types (e.g., arrays, pointers) and code structures (e.g., nested loops, function calls) are often beyond their capabilities. To help bridge this gap, we present AutoSpec, an automated approach to synthesize specifications for automated program verification. It overcomes the shortcomings of existing work in specification versatility, synthesizing satisfiable and adequate specifications for full proof. It is driven by static analysis and program verification, and is empowered by large language models (LLMs). AutoSpec addresses the practical challenges in three ways: (1) driving name by static analysis and program verification, LLMs serve as generators to generate candidate specifications, (2) programs are decomposed to direct the attention of LLMs, and (3) candidate specifications are validated in each round to avoid error accumulation during the interaction with LLMs. In this way, AutoSpec can incrementally and iteratively generate satisfiable and adequate specifications. The evaluation shows its effectiveness and usefulness, as it outperforms existing works by successfully verifying 79% of programs through automatic specification synthesis, a significant improvement of 1.592x. It can also be successfully applied to verify the programs in a real-world X509-parser project.
4/3/2024
Lemur: Integrating Large Language Models in Automated Program Verification
Haoze Wu, Clark Barrett, Nina Narodytska
0
0
The demonstrated code-understanding capability of LLMs raises the question of whether they can be used for automated program verification, a task that demands high-level abstract reasoning about program properties that is challenging for verification tools. We propose a general methodology to combine the power of LLMs and automated reasoners for automated program verification. We formally describe this methodology as a set of transition rules and prove its soundness. We instantiate the calculus as a sound automated verification procedure and demonstrate practical improvements on a set of synthetic and competition benchmarks.
4/26/2024
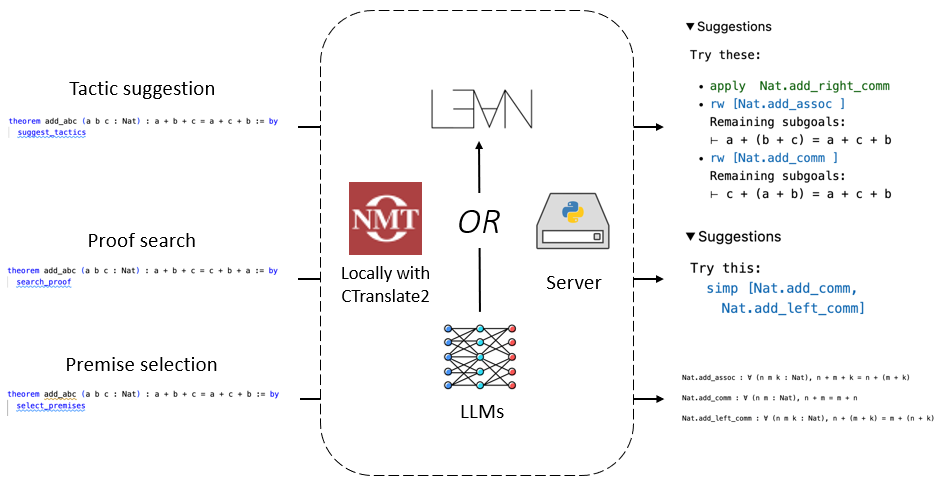
Towards Large Language Models as Copilots for Theorem Proving in Lean
Peiyang Song, Kaiyu Yang, Anima Anandkumar
0
0
Theorem proving is an important challenge for large language models (LLMs), as formal proofs can be checked rigorously by proof assistants such as Lean, leaving no room for hallucination. Existing LLM-based provers try to prove theorems in a fully autonomous mode without human intervention. In this mode, they struggle with novel and challenging theorems, for which human insights may be critical. In this paper, we explore LLMs as copilots that assist humans in proving theorems. We introduce Lean Copilot, a framework for running LLM inference in Lean. It enables programmers to build various LLM-based proof automation tools that integrate seamlessly into the workflow of Lean users. Using Lean Copilot, we build tools for suggesting proof steps (tactic suggestion), completing intermediate proof goals (proof search), and selecting relevant premises (premise selection) using LLMs. Users can use our pretrained models or bring their own ones that run either locally (with or without GPUs) or on the cloud. Experimental results demonstrate the effectiveness of our method in assisting humans and automating theorem proving process compared to existing rule-based proof automation in Lean. We open source all codes under a permissive MIT license to facilitate further research.
4/22/2024

AI Coders Are Among Us: Rethinking Programming Language Grammar Towards Efficient Code Generation
Zhensu Sun, Xiaoning Du, Zhou Yang, Li Li, David Lo
0
0
Besides humans and machines, Artificial Intelligence (AI) models have emerged to be another important audience of programming languages, as we come to the era of large language models (LLMs). LLMs can now excel at coding competitions and even program like developers to address various tasks, such as math calculation. Yet, the grammar and layout of existing programs are designed for humans. Particularly, abundant grammar tokens and formatting tokens are included to make the code more readable to humans. While beneficial, such a human-centric design imposes an unnecessary computational burden on LLMs where each token, either consumed or generated, consumes computational resources. To improve inference efficiency and reduce computational costs, we propose the concept of AI-oriented grammar, which aims to represent the code in a way that better suits the working mechanism of AI models. Code written with AI-oriented grammar discards formats and uses a minimum number of tokens to convey code semantics effectively. To demonstrate the feasibility of this concept, we explore and implement the first AI-oriented grammar for Python, named Simple Python (SimPy). SimPy is crafted by revising the original Python grammar through a series of heuristic rules. Programs written in SimPy maintain identical Abstract Syntax Tree (AST) structures to those in standard Python, allowing execution via a modified AST parser. In addition, we explore methods to enable existing LLMs to proficiently understand and use SimPy, and ensure the changes remain imperceptible for human developers. Compared with the original Python, SimPy not only reduces token usage by 13.5% and 10.4% for CodeLlama and GPT-4, but can also achieve equivalent, even improved, performance over the models trained on Python code.
4/26/2024