Enforcing Conditional Independence for Fair Representation Learning and Causal Image Generation
2404.13798
0
1

Abstract
Conditional independence (CI) constraints are critical for defining and evaluating fairness in machine learning, as well as for learning unconfounded or causal representations. Traditional methods for ensuring fairness either blindly learn invariant features with respect to a protected variable (e.g., race when classifying sex from face images) or enforce CI relative to the protected attribute only on the model output (e.g., the sex label). Neither of these methods are effective in enforcing CI in high-dimensional feature spaces. In this paper, we focus on a nascent approach characterizing the CI constraint in terms of two Jensen-Shannon divergence terms, and we extend it to high-dimensional feature spaces using a novel dynamic sampling strategy. In doing so, we introduce a new training paradigm that can be applied to any encoder architecture. We are able to enforce conditional independence of the diffusion autoencoder latent representation with respect to any protected attribute under the equalized odds constraint and show that this approach enables causal image generation with controllable latent spaces. Our experimental results demonstrate that our approach can achieve high accuracy on downstream tasks while upholding equality of odds.
Create account to get full access
Overview
- This paper explores techniques for enforcing conditional independence in machine learning models to promote fairness and causal reasoning.
- It presents a framework for learning fair representations by disentangling protected attributes from the learned features, and a method for generating images that obey causal constraints.
- The proposed approaches aim to improve fairness and interpretability in AI systems by ensuring certain attributes do not unduly influence model predictions.
Plain English Explanation
The researchers in this paper are trying to make artificial intelligence (AI) systems that are more fair and easier to understand. They do this by developing new techniques to train AI models in a specific way.
One technique is about learning "fair representations" of data. This means training the AI to extract useful information from the data, while making sure certain sensitive attributes (like race or gender) don't unfairly influence the model's outputs. The goal is to prevent the AI from discriminating based on these protected attributes.
The other technique is about generating images that obey causal rules. This means the AI can create new images that follow the logical relationships between different visual elements, rather than just memorizing patterns in the training data. This makes the AI's reasoning more interpretable and less likely to reflect human biases.
Overall, these methods aim to build AI systems that are more fair, transparent, and grounded in causal understanding - qualities that are important as these technologies become more widespread in our lives.
Technical Explanation
The paper presents two main technical contributions:
-
Fair Representation Learning: The authors propose a framework for learning fair representations by enforcing conditional independence between the learned features and protected attributes. This involves training an encoder network to extract informative features from the data while minimizing the mutual information between those features and the sensitive attributes. This helps prevent the model from relying on protected characteristics when making predictions.
-
Causal Image Generation: The authors also introduce a method for generating images that respect causal relationships between different visual elements. This is achieved by modeling the image generation process as a structural causal model, where the latent variables correspond to the causal factors that generate the observed pixels. By sampling from this model, the AI can create new images that obey the learned causal structure, leading to more interpretable and causally-grounded image synthesis.
The paper evaluates these techniques on various fairness and causality benchmarks, demonstrating their effectiveness at promoting fair and interpretable AI systems. For example, the fair representation learning approach is shown to improve demographic parity and equalized odds on downstream classification tasks, while the causal image generation method generates visually plausible images that respect the underlying causal relationships.
Critical Analysis
The paper makes important contributions towards building more ethical and transparent AI systems. The techniques it introduces provide principled ways to disentangle sensitive attributes from learned representations and to ground image generation in causal reasoning. This is a valuable direction of research as AI becomes more pervasive in high-stakes domains like healthcare, finance, and criminal justice.
However, the paper also acknowledges several limitations and caveats. For instance, the fair representation learning approach relies on access to protected attribute labels, which may not always be available in practice. Additionally, the causal image generation method assumes a known causal structure, which may be difficult to obtain for complex real-world data. Further research is needed to address these challenges and make the techniques more widely applicable.
More broadly, the field of causal AI is still nascent, and there are many open questions around how to best incorporate causal reasoning into machine learning models. The approach presented in this paper is an important step, but ongoing work is needed to further develop the theory and practice of causal AI for real-world applications.
Conclusion
This paper introduces novel techniques for promoting fairness and causal reasoning in machine learning. By enforcing conditional independence between learned features and protected attributes, the authors demonstrate how to train fair representations that mitigate unfair discrimination. Similarly, their causal image generation approach shows how to produce images that respect underlying causal relationships, leading to more interpretable and grounded AI systems.
These contributions are significant steps towards building AI technologies that are more ethical, transparent, and aligned with human values. As AI becomes increasingly ubiquitous, techniques like those presented in this paper will be crucial for ensuring these powerful systems are deployed responsibly and equitably. Continued research in this direction has the potential to unlock the full societal benefits of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Methods for Recovering Conditional Independence Graphs: A Survey
Harsh Shrivastava, Urszula Chajewska
0
0
Conditional Independence (CI) graphs are a type of probabilistic graphical models that are primarily used to gain insights about feature relationships. Each edge represents the partial correlation between the connected features which gives information about their direct dependence. In this survey, we list out different methods and study the advances in techniques developed to recover CI graphs. We cover traditional optimization methods as well as recently developed deep learning architectures along with their recommended implementations. To facilitate wider adoption, we include preliminaries that consolidate associated operations, for example techniques to obtain covariance matrix for mixed datatypes.
6/12/2024

Self-Distilled Disentangled Learning for Counterfactual Prediction
Xinshu Li, Mingming Gong, Lina Yao
0
0
The advancements in disentangled representation learning significantly enhance the accuracy of counterfactual predictions by granting precise control over instrumental variables, confounders, and adjustable variables. An appealing method for achieving the independent separation of these factors is mutual information minimization, a task that presents challenges in numerous machine learning scenarios, especially within high-dimensional spaces. To circumvent this challenge, we propose the Self-Distilled Disentanglement framework, referred to as $SD^2$. Grounded in information theory, it ensures theoretically sound independent disentangled representations without intricate mutual information estimator designs for high-dimensional representations. Our comprehensive experiments, conducted on both synthetic and real-world datasets, confirms the effectiveness of our approach in facilitating counterfactual inference in the presence of both observed and unobserved confounders.
6/17/2024
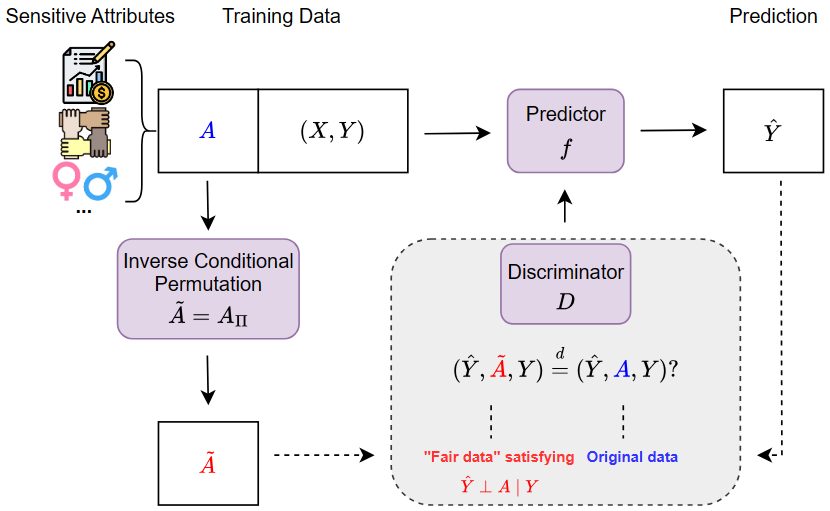
Flexible Fairness Learning via Inverse Conditional Permutation
Yuheng Lai, Leying Guan
0
0
Equalized odds, as a popular notion of algorithmic fairness, aims to ensure that sensitive variables, such as race and gender, do not unfairly influence the algorithm prediction when conditioning on the true outcome. Despite rapid advancements, most of the current research focuses on the violation of equalized odds caused by one sensitive attribute, leaving the challenge of simultaneously accounting for multiple attributes under-addressed. We address this gap by introducing a fairness learning approach that integrates adversarial learning with a novel inverse conditional permutation. This approach effectively and flexibly handles multiple sensitive attributes, potentially of mixed data types. The efficacy and flexibility of our method are demonstrated through both simulation studies and empirical analysis of real-world datasets.
4/10/2024
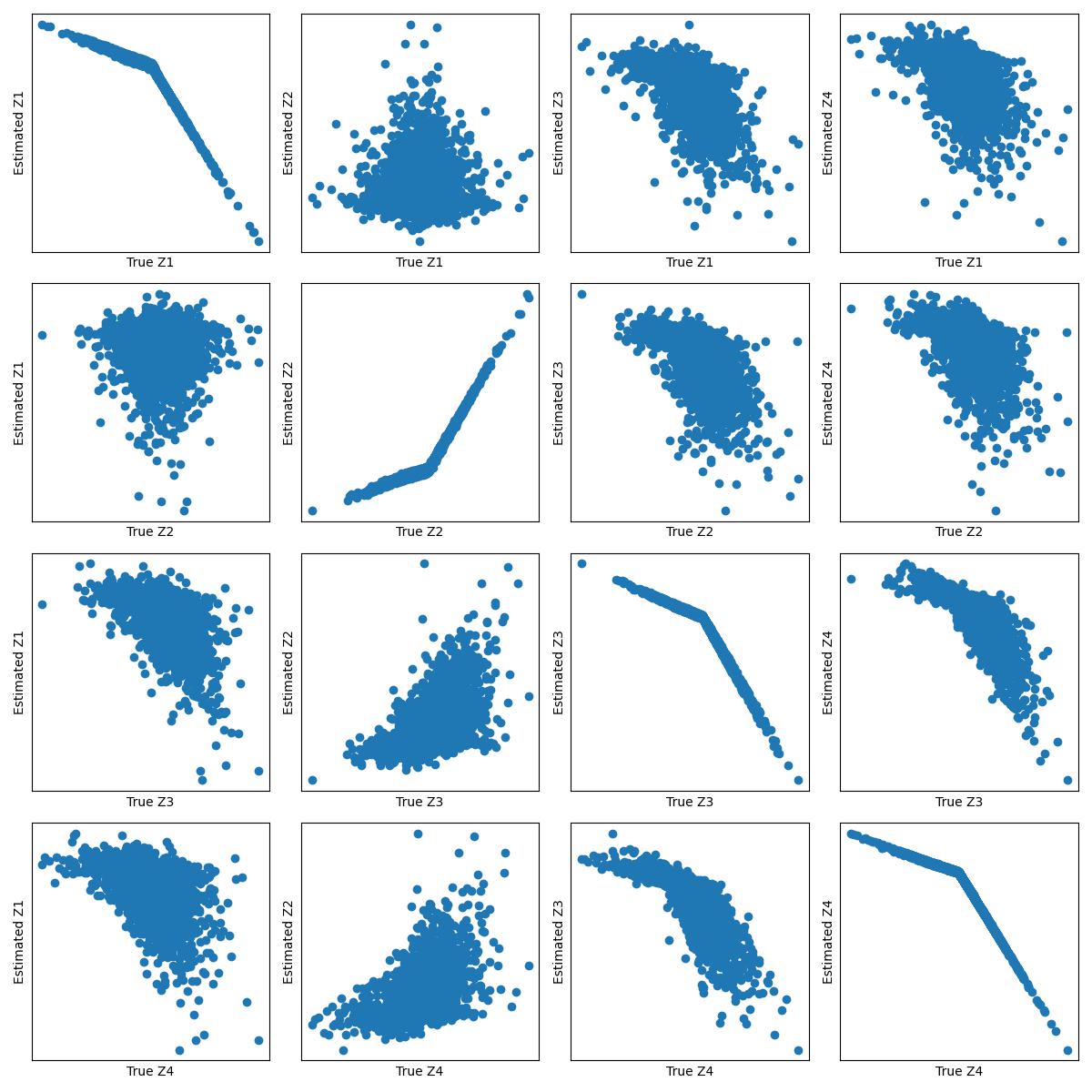
Causal Representation Learning from Multiple Distributions: A General Setting
Kun Zhang, Shaoan Xie, Ignavier Ng, Yujia Zheng
0
0
In many problems, the measured variables (e.g., image pixels) are just mathematical functions of the hidden causal variables (e.g., the underlying concepts or objects). For the purpose of making predictions in changing environments or making proper changes to the system, it is helpful to recover the hidden causal variables $Z_i$ and their causal relations represented by graph $mathcal{G}_Z$. This problem has recently been known as causal representation learning. This paper is concerned with a general, completely nonparametric setting of causal representation learning from multiple distributions (arising from heterogeneous data or nonstationary time series), without assuming hard interventions behind distribution changes. We aim to develop general solutions in this fundamental case; as a by product, this helps see the unique benefit offered by other assumptions such as parametric causal models or hard interventions. We show that under the sparsity constraint on the recovered graph over the latent variables and suitable sufficient change conditions on the causal influences, interestingly, one can recover the moralized graph of the underlying directed acyclic graph, and the recovered latent variables and their relations are related to the underlying causal model in a specific, nontrivial way. In some cases, each latent variable can even be recovered up to component-wise transformations. Experimental results verify our theoretical claims.
4/11/2024