Methods for Recovering Conditional Independence Graphs: A Survey

0
⛏️
Sign in to get full access
Overview
- Conditional Independence (CI) graphs are a type of probabilistic graphical models used to gain insights into feature relationships.
- Each edge represents the partial correlation between connected features, providing information about their direct dependence.
- This survey covers different methods and advances in techniques developed to recover CI graphs, including traditional optimization and deep learning approaches.
- The paper also includes preliminaries on techniques to obtain covariance matrices for mixed data types, to facilitate wider adoption.
Plain English Explanation
Conditional Independence (CI) graphs are a way to understand how different features or characteristics in a dataset are related to each other. They are a type of probabilistic graphical model. Each line or "edge" between features in the graph represents how directly those features depend on each other.
This paper summarizes different methods that have been developed to create these CI graphs and uncover the relationships between features. It covers both traditional statistical optimization techniques as well as more recent deep learning approaches. Some of these deep learning methods have been used to enforce conditional independence for fair representation learning.
The paper also includes some background information on how to calculate the covariance matrix, which is a key input for creating CI graphs, especially when working with a mix of different data types. This background information is meant to make it easier for more people to use these CI graph techniques.
Technical Explanation
The paper reviews various methods for recovering Conditional Independence (CI) graphs, which are a type of probabilistic graphical model used to understand the relationships between different features or variables.
The key element of a CI graph is the "edges" between nodes, which represent the partial correlation between the connected features. This partial correlation provides information about the direct dependence between those features.
The survey covers both traditional optimization-based techniques as well as more recently developed deep learning architectures for recovering CI graphs. Some deep learning approaches have been used specifically for learning fair representations by enforcing conditional independence.
To facilitate wider adoption of these CI graph recovery methods, the paper also includes preliminaries on techniques to obtain the covariance matrix, which is a crucial input, especially when dealing with mixed data types. Methods for learning sparse, high-dimensional matrix-valued graphical models are discussed, as are approaches for learning personalized binomial DAGs with network-structured covariates.
Critical Analysis
The paper provides a comprehensive overview of the methods developed for recovering Conditional Independence (CI) graphs, covering both traditional optimization-based approaches as well as more recent deep learning architectures. This is a valuable contribution given the importance of understanding feature relationships in many domains.
One limitation mentioned is the challenge of dealing with mixed data types when constructing the covariance matrix, which is a crucial input for CI graph recovery. The authors have attempted to address this by including preliminaries on relevant techniques, but this remains an area that could benefit from further research and development.
Additionally, while the paper discusses a range of methods, it does not provide a comparative analysis of their relative strengths and weaknesses. Further research could explore the performance and suitability of different CI graph recovery techniques in various real-world scenarios and applications, such as causal discovery.
Overall, this survey serves as a useful reference for researchers and practitioners interested in understanding and applying CI graph recovery techniques, but there remains room for continued advancements in this important area of probabilistic graphical modeling.
Conclusion
This paper provides a comprehensive overview of the methods developed for recovering Conditional Independence (CI) graphs, which are a powerful tool for gaining insights into the relationships between different features or variables in a dataset.
The survey covers both traditional optimization-based techniques as well as more recently proposed deep learning architectures, highlighting the progress made in this field. To facilitate wider adoption, the paper also includes background information on techniques for obtaining the covariance matrix, a crucial input for CI graph recovery.
While the paper does not provide a comparative analysis of the various methods, it serves as a valuable resource for researchers and practitioners interested in understanding and applying CI graph recovery techniques. Further advancements in this area, particularly in dealing with mixed data types and exploring the performance of different methods in real-world applications, could lead to even more powerful insights and applications of probabilistic graphical models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
Methods for Recovering Conditional Independence Graphs: A Survey
Harsh Shrivastava, Urszula Chajewska
Conditional Independence (CI) graphs are a type of probabilistic graphical models that are primarily used to gain insights about feature relationships. Each edge represents the partial correlation between the connected features which gives information about their direct dependence. In this survey, we list out different methods and study the advances in techniques developed to recover CI graphs. We cover traditional optimization methods as well as recently developed deep learning architectures along with their recommended implementations. To facilitate wider adoption, we include preliminaries that consolidate associated operations, for example techniques to obtain covariance matrix for mixed datatypes.
Read more8/30/2024

0
Causal Discovery with Fewer Conditional Independence Tests
Kirankumar Shiragur, Jiaqi Zhang, Caroline Uhler
Many questions in science center around the fundamental problem of understanding causal relationships. However, most constraint-based causal discovery algorithms, including the well-celebrated PC algorithm, often incur an exponential number of conditional independence (CI) tests, posing limitations in various applications. Addressing this, our work focuses on characterizing what can be learned about the underlying causal graph with a reduced number of CI tests. We show that it is possible to a learn a coarser representation of the hidden causal graph with a polynomial number of tests. This coarser representation, named Causal Consistent Partition Graph (CCPG), comprises of a partition of the vertices and a directed graph defined over its components. CCPG satisfies consistency of orientations and additional constraints which favor finer partitions. Furthermore, it reduces to the underlying causal graph when the causal graph is identifiable. As a consequence, our results offer the first efficient algorithm for recovering the true causal graph with a polynomial number of tests, in special cases where the causal graph is fully identifiable through observational data and potentially additional interventions.
Read more6/5/2024

0
Enforcing Conditional Independence for Fair Representation Learning and Causal Image Generation
Jensen Hwa, Qingyu Zhao, Aditya Lahiri, Adnan Masood, Babak Salimi, Ehsan Adeli
Conditional independence (CI) constraints are critical for defining and evaluating fairness in machine learning, as well as for learning unconfounded or causal representations. Traditional methods for ensuring fairness either blindly learn invariant features with respect to a protected variable (e.g., race when classifying sex from face images) or enforce CI relative to the protected attribute only on the model output (e.g., the sex label). Neither of these methods are effective in enforcing CI in high-dimensional feature spaces. In this paper, we focus on a nascent approach characterizing the CI constraint in terms of two Jensen-Shannon divergence terms, and we extend it to high-dimensional feature spaces using a novel dynamic sampling strategy. In doing so, we introduce a new training paradigm that can be applied to any encoder architecture. We are able to enforce conditional independence of the diffusion autoencoder latent representation with respect to any protected attribute under the equalized odds constraint and show that this approach enables causal image generation with controllable latent spaces. Our experimental results demonstrate that our approach can achieve high accuracy on downstream tasks while upholding equality of odds.
Read more4/23/2024
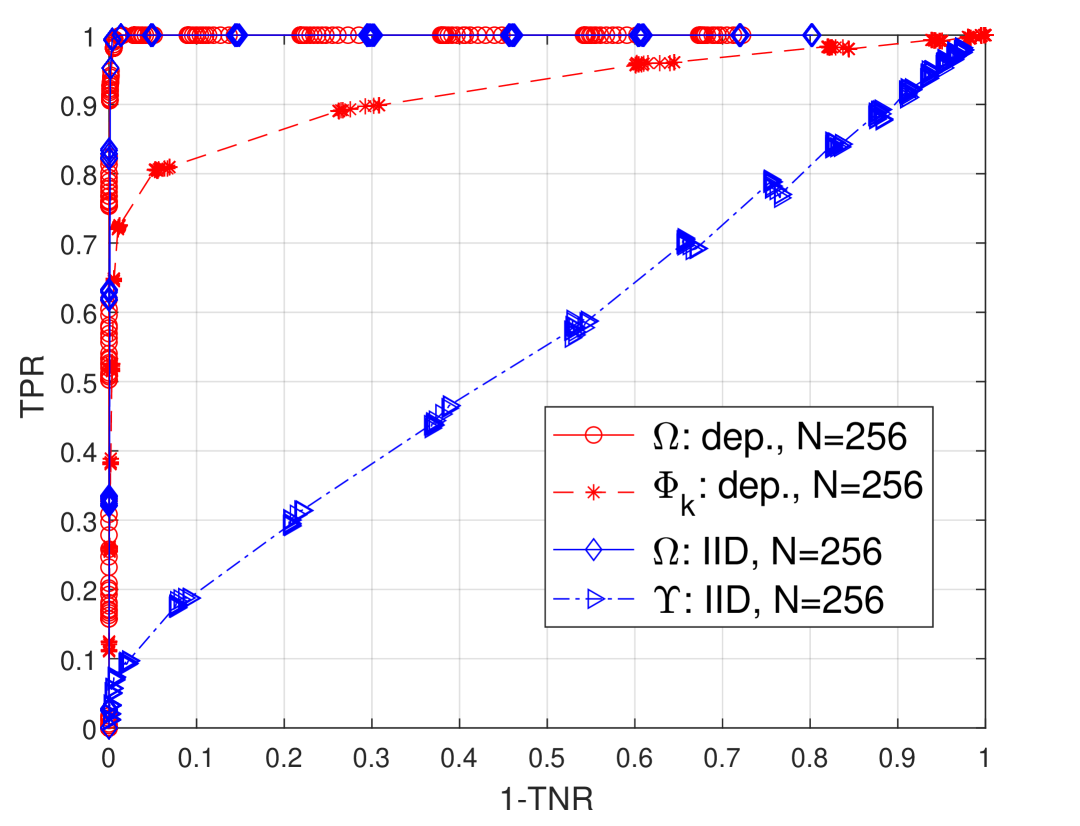
0
Learning Sparse High-Dimensional Matrix-Valued Graphical Models From Dependent Data
Jitendra K Tugnait
We consider the problem of inferring the conditional independence graph (CIG) of a sparse, high-dimensional, stationary matrix-variate Gaussian time series. All past work on high-dimensional matrix graphical models assumes that independent and identically distributed (i.i.d.) observations of the matrix-variate are available. Here we allow dependent observations. We consider a sparse-group lasso-based frequency-domain formulation of the problem with a Kronecker-decomposable power spectral density (PSD), and solve it via an alternating direction method of multipliers (ADMM) approach. The problem is bi-convex which is solved via flip-flop optimization. We provide sufficient conditions for local convergence in the Frobenius norm of the inverse PSD estimators to the true value. This result also yields a rate of convergence. We illustrate our approach using numerical examples utilizing both synthetic and real data.
Read more5/1/2024