Flexible Fairness Learning via Inverse Conditional Permutation
2404.05678
0
0
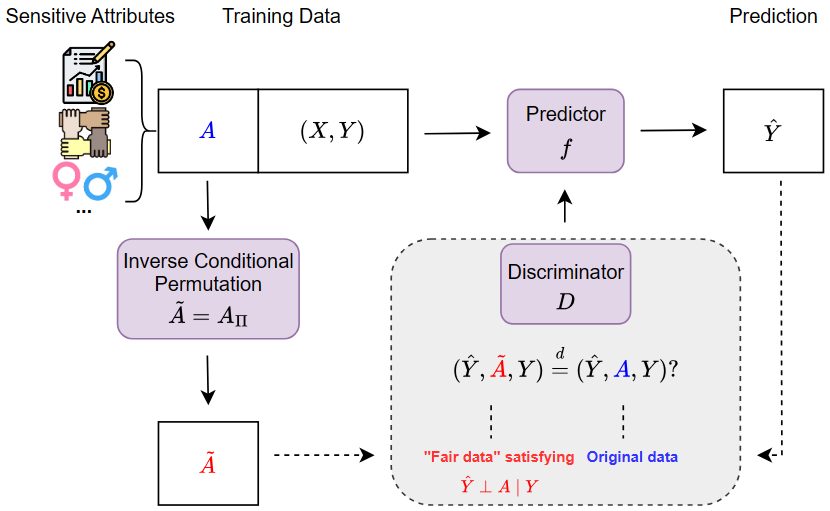
Abstract
Equalized odds, as a popular notion of algorithmic fairness, aims to ensure that sensitive variables, such as race and gender, do not unfairly influence the algorithm prediction when conditioning on the true outcome. Despite rapid advancements, most of the current research focuses on the violation of equalized odds caused by one sensitive attribute, leaving the challenge of simultaneously accounting for multiple attributes under-addressed. We address this gap by introducing a fairness learning approach that integrates adversarial learning with a novel inverse conditional permutation. This approach effectively and flexibly handles multiple sensitive attributes, potentially of mixed data types. The efficacy and flexibility of our method are demonstrated through both simulation studies and empirical analysis of real-world datasets.
Create account to get full access
Overview
- This paper presents a new approach for achieving flexible fairness in machine learning models, particularly in the context of binary and multiclass classification tasks.
- The proposed method, called Inverse Conditional Permutation (ICP), aims to learn fair representations that can satisfy various fairness constraints without sacrificing model performance.
- The paper explores the relationship between fairness and invariance, and introduces a novel inverse conditional permutation technique to achieve this balance.
Plain English Explanation
The paper is about a new way to make machine learning models more fair. Fairness is an important issue in AI, as these models can sometimes treat people differently based on their race, gender, or other protected characteristics. The authors introduce a method called Inverse Conditional Permutation (ICP) that allows the model to learn representations that are fair, without sacrificing the model's overall performance.
The key idea is that by shuffling the data in a certain way, the model can learn features that are not biased towards protected attributes. This allows the model to make decisions that are more equitable, while still performing well on the task at hand.
The authors show that ICP can be applied to both binary and multiclass classification problems, and that it outperforms other state-of-the-art fairness techniques. The approach is flexible, meaning it can be adapted to satisfy different fairness constraints depending on the specific use case.
Technical Explanation
The paper proposes a new method called Inverse Conditional Permutation (ICP) for achieving flexible fairness in machine learning models. The key idea is to learn fair representations by exploiting the relationship between fairness and invariance.
The authors first define a general fairness framework that can accommodate various fairness notions, such as demographic parity, equal opportunity, and equalized odds. They then introduce the ICP technique, which involves shuffling the data in a specific way to learn representations that are invariant to protected attributes while still preserving task-relevant information.
Experiments on both binary and multiclass classification tasks show that ICP can achieve competitive performance while improving fairness compared to state-of-the-art fairness techniques. The approach is also flexible, allowing the user to specify different fairness constraints depending on the application.
Critical Analysis
The paper presents a promising approach for achieving flexible fairness in machine learning models. The key strength of the ICP method is its ability to learn fair representations without significantly impacting model performance, which is a common challenge in fairness-aware machine learning.
However, the paper does not address the potential limitations of input perturbation techniques for improving fairness, such as the risk of introducing unintended biases or degrading overall model performance. Additionally, the paper only evaluates the approach on standard benchmark datasets, and it would be valuable to see how ICP performs on more real-world, high-stakes applications.
Further research is also needed to better understand the relationship between fairness and invariance, and to explore alternative techniques for achieving flexible fairness that may be more robust or efficient than input perturbation methods.
Conclusion
The Inverse Conditional Permutation (ICP) method presented in this paper offers a new approach for achieving flexible fairness in machine learning models. By exploiting the connection between fairness and invariance, ICP can learn fair representations without significantly compromising model performance, addressing a key challenge in the field of algorithmic fairness.
The paper's findings suggest that ICP can be a valuable tool for building more equitable AI systems, particularly in binary and multiclass classification tasks. As the importance of fairness in machine learning continues to grow, further research and development of flexible fairness techniques like ICP will be crucial for ensuring that AI systems are designed to benefit all members of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
Intrinsic Fairness-Accuracy Tradeoffs under Equalized Odds
Meiyu Zhong, Ravi Tandon
0
0
With the growing adoption of machine learning (ML) systems in areas like law enforcement, criminal justice, finance, hiring, and admissions, it is increasingly critical to guarantee the fairness of decisions assisted by ML. In this paper, we study the tradeoff between fairness and accuracy under the statistical notion of equalized odds. We present a new upper bound on the accuracy (that holds for any classifier), as a function of the fairness budget. In addition, our bounds also exhibit dependence on the underlying statistics of the data, labels and the sensitive group attributes. We validate our theoretical upper bounds through empirical analysis on three real-world datasets: COMPAS, Adult, and Law School. Specifically, we compare our upper bound to the tradeoffs that are achieved by various existing fair classifiers in the literature. Our results show that achieving high accuracy subject to a low-bias could be fundamentally limited based on the statistical disparity across the groups.
5/17/2024
On the Inductive Biases of Demographic Parity-based Fair Learning Algorithms
Haoyu Lei, Amin Gohari, Farzan Farnia
0
0
Fair supervised learning algorithms assigning labels with little dependence on a sensitive attribute have attracted great attention in the machine learning community. While the demographic parity (DP) notion has been frequently used to measure a model's fairness in training fair classifiers, several studies in the literature suggest potential impacts of enforcing DP in fair learning algorithms. In this work, we analytically study the effect of standard DP-based regularization methods on the conditional distribution of the predicted label given the sensitive attribute. Our analysis shows that an imbalanced training dataset with a non-uniform distribution of the sensitive attribute could lead to a classification rule biased toward the sensitive attribute outcome holding the majority of training data. To control such inductive biases in DP-based fair learning, we propose a sensitive attribute-based distributionally robust optimization (SA-DRO) method improving robustness against the marginal distribution of the sensitive attribute. Finally, we present several numerical results on the application of DP-based learning methods to standard centralized and distributed learning problems. The empirical findings support our theoretical results on the inductive biases in DP-based fair learning algorithms and the debiasing effects of the proposed SA-DRO method.
6/21/2024

One Fits All: Learning Fair Graph Neural Networks for Various Sensitive Attributes
Yuchang Zhu, Jintang Li, Yatao Bian, Zibin Zheng, Liang Chen
0
0
Recent studies have highlighted fairness issues in Graph Neural Networks (GNNs), where they produce discriminatory predictions against specific protected groups categorized by sensitive attributes such as race and age. While various efforts to enhance GNN fairness have made significant progress, these approaches are often tailored to specific sensitive attributes. Consequently, they necessitate retraining the model from scratch to accommodate changes in the sensitive attribute requirement, resulting in high computational costs. To gain deeper insights into this issue, we approach the graph fairness problem from a causal modeling perspective, where we identify the confounding effect induced by the sensitive attribute as the underlying reason. Motivated by this observation, we formulate the fairness problem in graphs from an invariant learning perspective, which aims to learn invariant representations across environments. Accordingly, we propose a graph fairness framework based on invariant learning, namely FairINV, which enables the training of fair GNNs to accommodate various sensitive attributes within a single training session. Specifically, FairINV incorporates sensitive attribute partition and trains fair GNNs by eliminating spurious correlations between the label and various sensitive attributes. Experimental results on several real-world datasets demonstrate that FairINV significantly outperforms state-of-the-art fairness approaches, underscoring its effectiveness. Our code is available via: https://github.com/ZzoomD/FairINV/.
6/21/2024
🔍
Individual Fairness Through Reweighting and Tuning
Abdoul Jalil Djiberou Mahamadou, Lea Goetz, Russ Altman
0
0
Inherent bias within society can be amplified and perpetuated by artificial intelligence (AI) systems. To address this issue, a wide range of solutions have been proposed to identify and mitigate bias and enforce fairness for individuals and groups. Recently, Graph Laplacian Regularizer (GLR), a regularization technique from the semi-supervised learning literature has been used as a substitute for the common Lipschitz condition to enhance individual fairness. Notable prior work has shown that enforcing individual fairness through a GLR can improve the transfer learning accuracy of AI models under covariate shifts. However, the prior work defines a GLR on the source and target data combined, implicitly assuming that the target data are available at train time, which might not hold in practice. In this work, we investigated whether defining a GLR independently on the train and target data could maintain similar accuracy. Furthermore, we introduced the Normalized Fairness Gain score (NFG) to measure individual fairness by measuring the amount of gained fairness when a GLR is used versus not. We evaluated the new and original methods under NFG, the Prediction Consistency (PC), and traditional classification metrics on the German Credit Approval dataset. The results showed that the two models achieved similar statistical mean performances over five-fold cross-validation. Furthermore, the proposed metric showed that PC scores can be misleading as the scores can be high and statistically similar to fairness-enhanced models while NFG scores are small. This work therefore provides new insights into when a GLR effectively enhances individual fairness and the pitfalls of PC.
5/9/2024