Enhance Lifelong Model Editing with Continuous Data-Adapter Association

0
Sign in to get full access
Overview
- Enhances lifelong model editing by continuously associating data with model components
- Introduces a novel approach called Continuous Data-Adapter Association (CDA) to enable efficient, flexible, and scalable model editing
- Demonstrates the effectiveness of CDA on various benchmark tasks, including few-shot classification and language modeling
Plain English Explanation
The paper proposes a new technique called Continuous Data-Adapter Association (CDA) to improve the way large language models can be edited and updated over time. Typically, when a model is trained on new data, it can "forget" or lose performance on its previous capabilities. CDA aims to address this by continuously linking the model's internal components to the specific data that they were trained on.
This allows the model to be edited or updated more efficiently, as changes can be localized to just the relevant components rather than requiring a full retraining of the entire model. The authors demonstrate that CDA enables flexible and scalable lifelong model editing, where the model can continuously learn and adapt to new information without catastrophically forgetting its previous knowledge.
Technical Explanation
The core idea of CDA is to maintain a continuous association between the model's internal components (e.g., neurons, layers) and the data they were trained on. This is achieved by augmenting the model with a set of "data-adapters" - small neural networks that capture the relationship between model components and their associated data.
As the model is updated with new data, the data-adapters are also continuously updated to reflect the changing associations. This allows the model to efficiently identify which components need to be edited or fine-tuned when presented with new information, without disrupting the existing knowledge.
The authors evaluate CDA on a variety of benchmark tasks, including few-shot classification and language modeling. The results show that CDA outperforms standard fine-tuning approaches, as it enables more targeted and efficient model updates while preserving the model's overall performance.
Critical Analysis
The paper presents a promising approach to address the challenge of lifelong learning in large language models. By maintaining a continuous association between model components and their training data, CDA enables more flexible and scalable model editing compared to traditional fine-tuning methods.
However, the authors acknowledge that CDA introduces additional computational overhead, as the data-adapters need to be maintained and updated alongside the main model. Additionally, the effectiveness of CDA may be sensitive to the specific model architecture and task domain, and further research is needed to understand its broader applicability.
It would also be valuable to explore the potential trade-offs between the granularity of the data-adapter associations (e.g., per-neuron vs. per-layer) and the overall performance and efficiency of the model editing process.
Conclusion
The paper presents a novel approach called Continuous Data-Adapter Association (CDA) that enhances the ability to edit and update large language models over time. By continuously linking the model's internal components to their associated training data, CDA enables efficient, flexible, and scalable model editing, which is a crucial capability for developing robust and adaptable AI systems. The promising results demonstrated in the paper suggest that CDA is a valuable contribution to the field of lifelong learning and model editing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhance Lifelong Model Editing with Continuous Data-Adapter Association
Jiaang Li, Quan Wang, Zhongnan Wang, Yongdong Zhang, Zhendong Mao
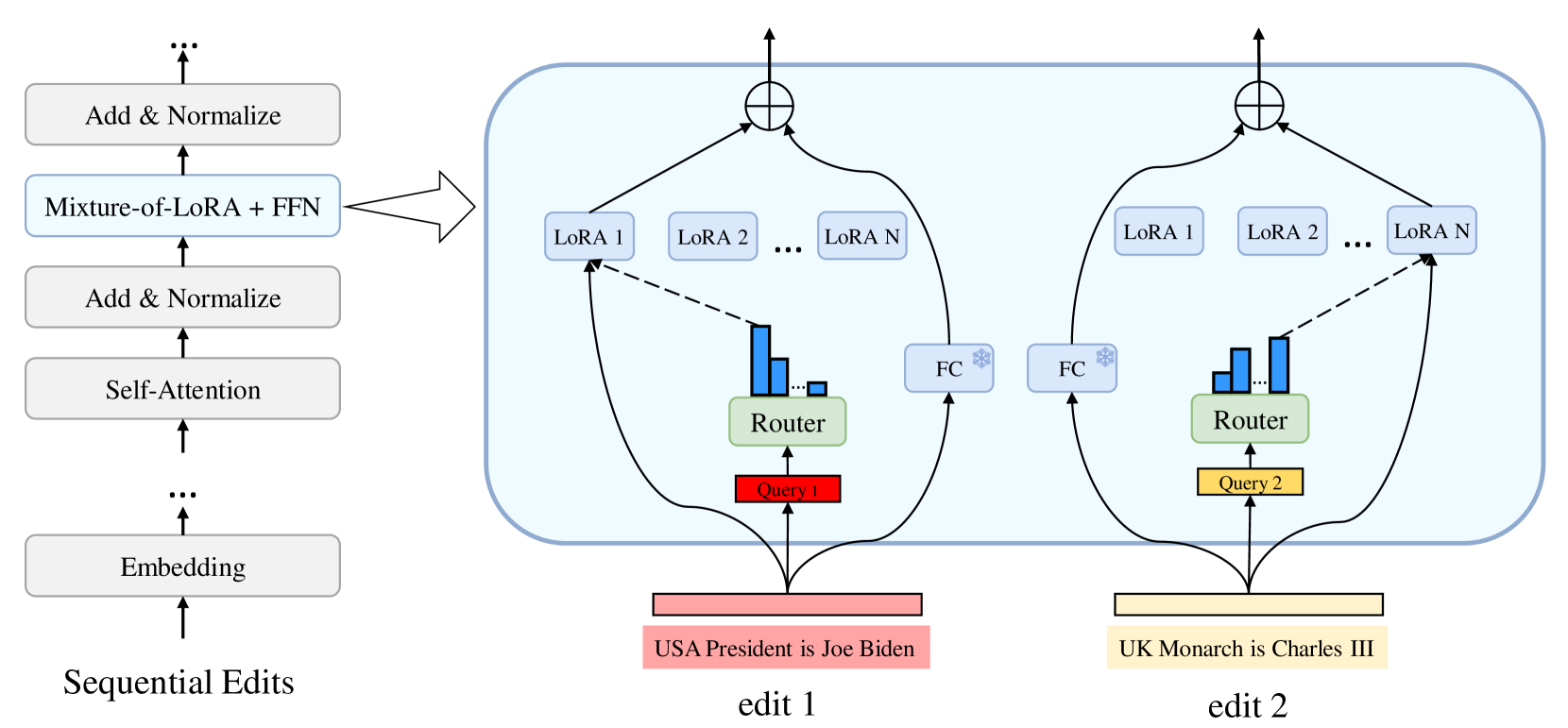
Large language models (LLMs) require model editing to efficiently update specific knowledge within them and avoid factual errors. Most model editing methods are solely designed for single-time use and lead to a significant forgetting effect after sequential edits over time, referred to as lifelong editing. Current approaches manage sequential edits by freezing original parameters and allocating new adapters for each knowledge modification. However, these methods lack robustness to minor input variations. To address this challenge, we propose ELDER, textbf{E}nhancing textbf{L}ifelong motextbf{D}el textbf{E}diting with mixtutextbf{R}e of Low-Rank Adapter (LoRA). ELDER is an adaptive approach that integrates multiple LoRAs through a router network. It learns to create a continuous and smooth association between data and adapters, thereby enhancing robustness and generalization to semantically equivalent inputs. Additionally, we introduce a novel loss to help learn associations between adapter allocations and edit semantics. A deferral mechanism is also proposed to retain the original LLM capabilities post-edit. Extensive experiments on GPT-2 XL and LLaMA2-7B demonstrate that ELDER effectively edits models in the lifelong setting and exhibits strong scalability, while retaining LLM's general abilities on downstream tasks.
Read more8/23/2024
0
LEMoE: Advanced Mixture of Experts Adaptor for Lifelong Model Editing of Large Language Models
Renzhi Wang, Piji Li
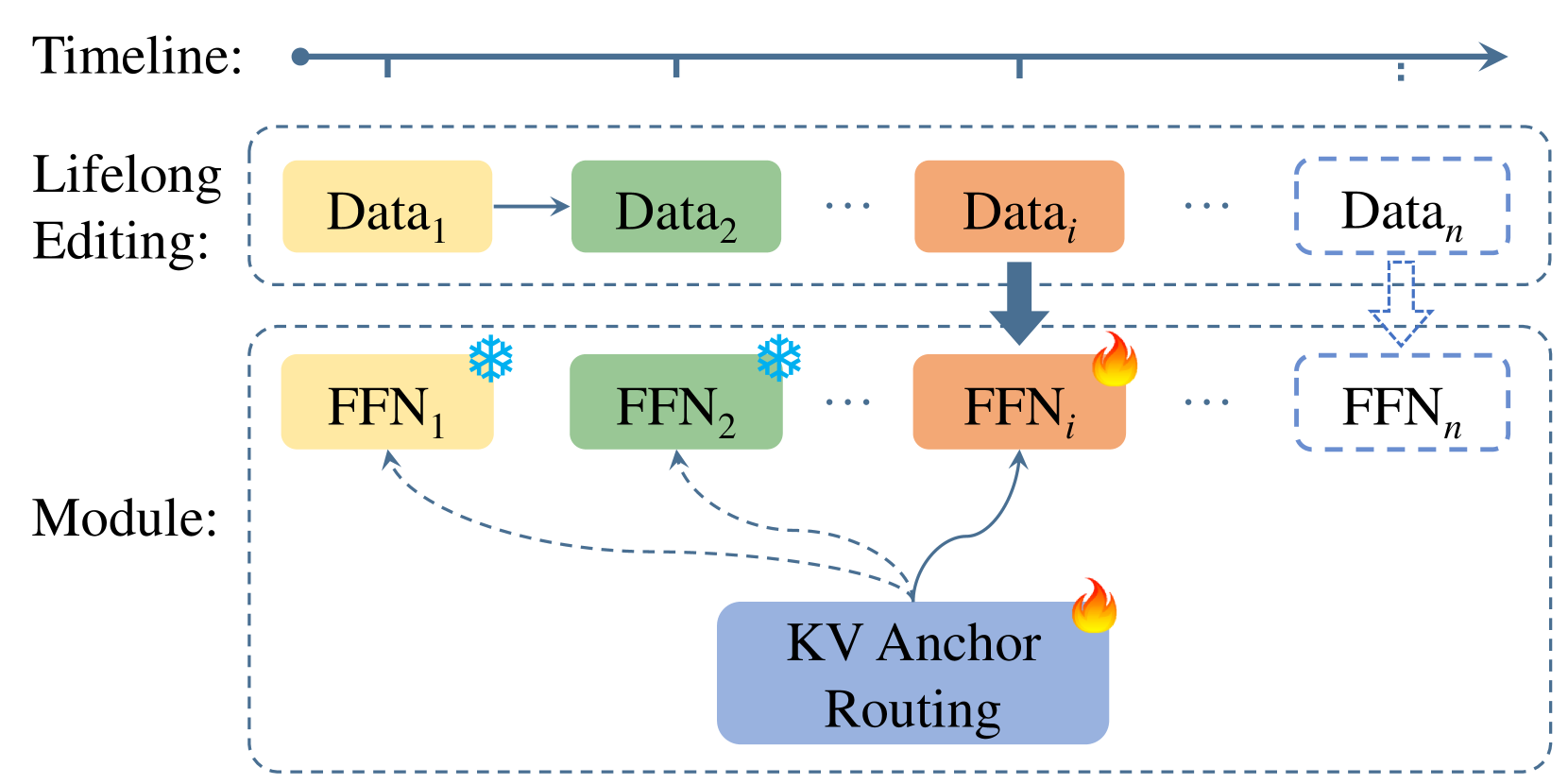
Large language models (LLMs) require continual knowledge updates to stay abreast of the ever-changing world facts, prompting the formulation of lifelong model editing task. While recent years have witnessed the development of various techniques for single and batch editing, these methods either fail to apply or perform sub-optimally when faced with lifelong editing. In this paper, we introduce LEMoE, an advanced Mixture of Experts (MoE) adaptor for lifelong model editing. We first analyze the factors influencing the effectiveness of conventional MoE adaptor in lifelong editing, including catastrophic forgetting, inconsistent routing and order sensitivity. Based on these insights, we propose a tailored module insertion method to achieve lifelong editing, incorporating a novel KV anchor routing to enhance routing consistency between training and inference stage, along with a concise yet effective clustering-based editing order planning. Experimental results demonstrate the effectiveness of our method in lifelong editing, surpassing previous model editing techniques while maintaining outstanding performance in batch editing task. Our code will be available.
Read more7/1/2024
🛠️
0
Lifelong Knowledge Editing for LLMs with Retrieval-Augmented Continuous Prompt Learning
Qizhou Chen, Taolin Zhang, Xiaofeng He, Dongyang Li, Chengyu Wang, Longtao Huang, Hui Xue
Model editing aims to correct outdated or erroneous knowledge in large language models (LLMs) without the need for costly retraining. Lifelong model editing is the most challenging task that caters to the continuous editing requirements of LLMs. Prior works primarily focus on single or batch editing; nevertheless, these methods fall short in lifelong editing scenarios due to catastrophic knowledge forgetting and the degradation of model performance. Although retrieval-based methods alleviate these issues, they are impeded by slow and cumbersome processes of integrating the retrieved knowledge into the model. In this work, we introduce RECIPE, a RetriEval-augmented ContInuous Prompt lEarning method, to boost editing efficacy and inference efficiency in lifelong learning. RECIPE first converts knowledge statements into short and informative continuous prompts, prefixed to the LLM's input query embedding, to efficiently refine the response grounded on the knowledge. It further integrates the Knowledge Sentinel (KS) that acts as an intermediary to calculate a dynamic threshold, determining whether the retrieval repository contains relevant knowledge. Our retriever and prompt encoder are jointly trained to achieve editing properties, i.e., reliability, generality, and locality. In our experiments, RECIPE is assessed extensively across multiple LLMs and editing datasets, where it achieves superior editing performance. RECIPE also demonstrates its capability to maintain the overall performance of LLMs alongside showcasing fast editing and inference speed.
Read more5/9/2024
🏋️
0
AdapterSwap: Continuous Training of LLMs with Data Removal and Access-Control Guarantees
William Fleshman, Aleem Khan, Marc Marone, Benjamin Van Durme
Large language models (LLMs) are increasingly capable of completing knowledge intensive tasks by recalling information from a static pretraining corpus. Here we are concerned with LLMs in the context of evolving data requirements. For instance: batches of new data that are introduced periodically; subsets of data with user-based access controls; or requirements on dynamic removal of documents with guarantees that associated knowledge cannot be recalled. We wish to satisfy these requirements while at the same time ensuring a model does not forget old information when new data becomes available. To address these issues, we introduce AdapterSwap, a training and inference scheme that organizes knowledge from a data collection into a set of low-rank adapters, which are dynamically composed during inference. Our experiments demonstrate AdapterSwap's ability to support efficient continual learning, while also enabling organizations to have fine-grained control over data access and deletion.
Read more4/15/2024