Enhance the Robustness of Text-Centric Multimodal Alignments

0

Sign in to get full access
Overview
This research paper addresses the challenge of enhancing the robustness of text-centric multimodal alignments. Multimodal learning, which involves integrating information from different modalities like text, images, and audio, is a key area of focus in artificial intelligence and machine learning. However, ensuring the robustness and reliability of these multimodal systems is an important and complex problem.
Plain English Explanation
The paper explores ways to make text-centric multimodal alignment models more robust and reliable. Multimodal alignment refers to the process of matching or connecting information from different modalities, like aligning text with corresponding images. This is a fundamental task in multimodal learning, with applications in areas like image captioning, visual question answering, and cross-modal retrieval.
The researchers investigate techniques to enhance the robustness of these text-centric multimodal alignments, ensuring they can reliably perform even when faced with noisy, corrupted, or adversarial inputs. This is important because in real-world applications, multimodal systems may encounter all kinds of challenging data, and we want them to still function well.
Technical Explanation
The paper proposes a novel approach called "Enhance the Robustness in Text-Centric Multimodal Alignments" (ERTCMA) that aims to improve the robustness of text-centric multimodal alignment models. Key elements of the approach include:
- Modality-Specific Attention: The model uses separate attention mechanisms for the text and visual modalities, allowing it to focus on the most relevant parts of each input.
- Adversarial Training: The researchers train the model to be robust against adversarial attacks, where small perturbations are added to the input to try to fool the model.
- Uncertainty-Aware Alignment: The model learns to quantify its own uncertainty about the alignment between text and visual inputs, which helps it make more reliable predictions.
The paper evaluates the ERTCMA approach on several benchmark datasets and compares it to other state-of-the-art multimodal alignment methods. The results demonstrate significant improvements in robustness and alignment accuracy, even when the input data is corrupted or adversarially perturbed.
Critical Analysis
The paper presents a compelling approach for enhancing the robustness of text-centric multimodal alignments. The key ideas, like modality-specific attention and adversarial training, are well-motivated and aligned with current best practices in robust machine learning.
However, the paper does not address some potential limitations or areas for further research. For example, it is unclear how the ERTCMA approach would scale to larger, more complex multimodal datasets or models. Additionally, the paper does not explore the interpretability or explainability of the model's decision-making, which is an important consideration for real-world applications.
Conclusion
This research paper introduces a novel method, ERTCMA, for improving the robustness of text-centric multimodal alignments. By incorporating modality-specific attention, adversarial training, and uncertainty-aware alignment, the approach demonstrates significant improvements in alignment accuracy and resilience to noisy or adversarial inputs. While the paper does not address all potential limitations, it represents an important step forward in enhancing the reliability of multimodal learning systems, with potential applications in image captioning, visual question answering, and cross-modal retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhance the Robustness of Text-Centric Multimodal Alignments
Ting-Yu Yen, Yun-Da Tsai, Keng-Te Liao, Shou-De Lin
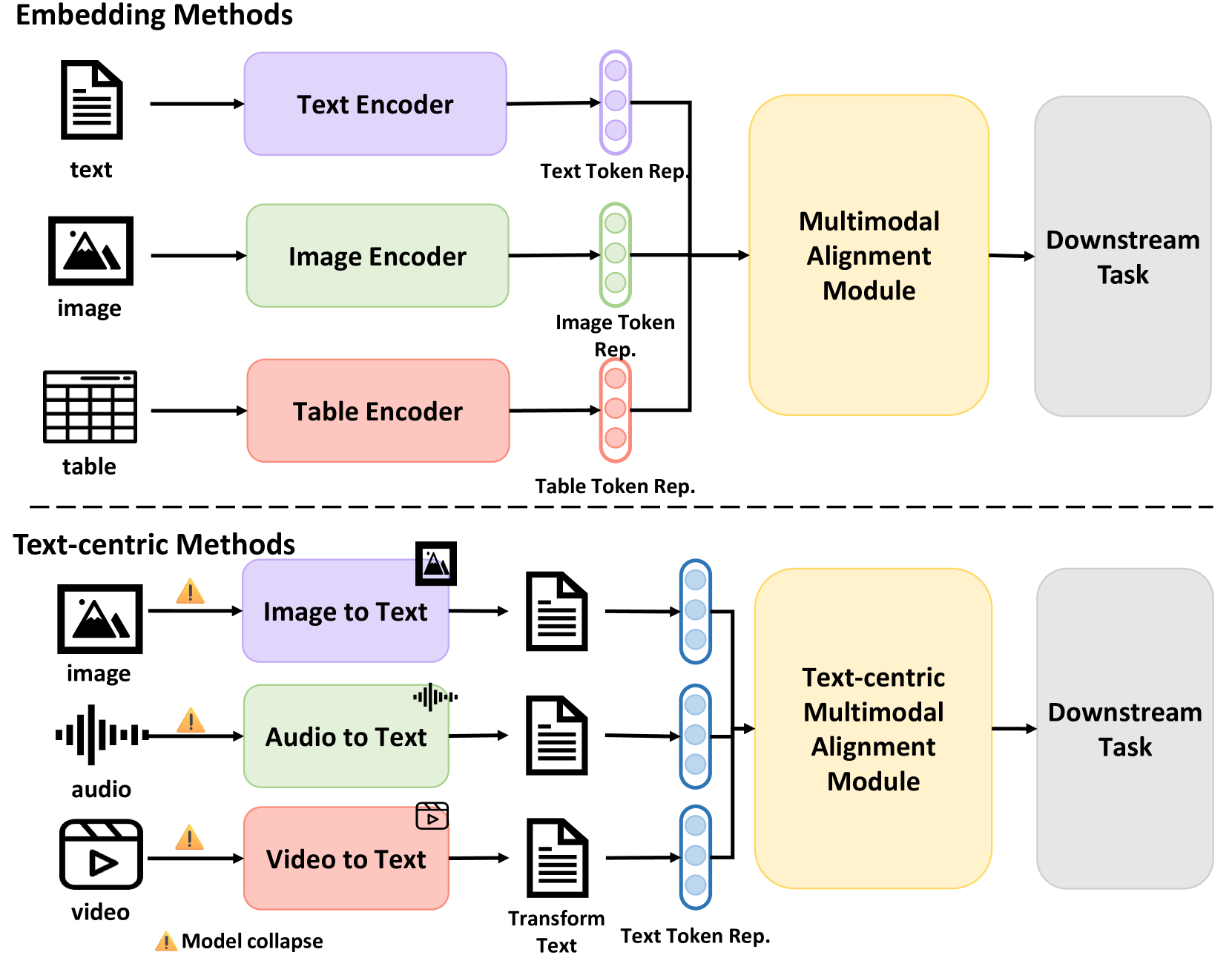
Converting different modalities into general text, serving as input prompts for large language models (LLMs), is a common method to align multimodal models when there is limited pairwise data. This text-centric approach leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation. This enables downstream models to effectively interpret various modal inputs. This study assesses the quality and robustness of multimodal representations in the presence of missing entries, noise, or absent modalities, revealing that current text-centric alignment methods compromise downstream robustness. To address this issue, we propose a new text-centric approach that achieves superior robustness compared to previous methods across various modalities in different settings. Our findings highlight the potential of this approach to enhance the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Read more7/9/2024
0
Enhance Modality Robustness in Text-Centric Multimodal Alignment with Adversarial Prompting
Yun-Da Tsai, Ting-Yu Yen, Keng-Te Liao, Shou-De Lin
Converting different modalities into generalized text, which then serves as input prompts for large language models (LLMs), is a common approach for aligning multimodal models, particularly when pairwise data is limited. Text-centric alignment method leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation, thereby enabling downstream models to effectively interpret various modal inputs. This study evaluates the quality and robustness of multimodal representations in the face of noise imperfections, dynamic input order permutations, and missing modalities, revealing that current text-centric alignment methods can compromise downstream robustness. To address this issue, we propose a new text-centric adversarial training approach that significantly enhances robustness compared to traditional robust training methods and pre-trained multimodal foundation models. Our findings underscore the potential of this approach to improve the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Read more8/20/2024

0
Text-centric Alignment for Multi-Modality Learning
Yun-Da Tsai, Ting-Yu Yen, Pei-Fu Guo, Zhe-Yan Li, Shou-De Lin
This research paper addresses the challenge of modality mismatch in multimodal learning, where the modalities available during inference differ from those available at training. We propose the Text-centric Alignment for Multi-Modality Learning (TAMML) approach, an innovative method that utilizes Large Language Models (LLMs) with in-context learning and foundation models to enhance the generalizability of multimodal systems under these conditions. By leveraging the unique properties of text as a unified semantic space, TAMML demonstrates significant improvements in handling unseen, diverse, and unpredictable modality combinations. TAMML not only adapts to varying modalities but also maintains robust performance, showcasing the potential of foundation models in overcoming the limitations of traditional fixed-modality frameworks in embedding representations. This study contributes to the field by offering a flexible, effective solution for real-world applications where modality availability is dynamic and uncertain.
Read more5/22/2024
0
Quantifying and Enhancing Multi-modal Robustness with Modality Preference
Zequn Yang, Yake Wei, Ce Liang, Di Hu
Multi-modal models have shown a promising capability to effectively integrate information from various sources, yet meanwhile, they are found vulnerable to pervasive perturbations, such as uni-modal attacks and missing conditions. To counter these perturbations, robust multi-modal representations are highly expected, which are positioned well away from the discriminative multi-modal decision boundary. In this paper, different from conventional empirical studies, we focus on a commonly used joint multi-modal framework and theoretically discover that larger uni-modal representation margins and more reliable integration for modalities are essential components for achieving higher robustness. This discovery can further explain the limitation of multi-modal robustness and the phenomenon that multi-modal models are often vulnerable to attacks on the specific modality. Moreover, our analysis reveals how the widespread issue, that the model has different preferences for modalities, limits the multi-modal robustness by influencing the essential components and could lead to attacks on the specific modality highly effective. Inspired by our theoretical finding, we introduce a training procedure called Certifiable Robust Multi-modal Training (CRMT), which can alleviate this influence from modality preference and explicitly regulate essential components to significantly improve robustness in a certifiable manner. Our method demonstrates substantial improvements in performance and robustness compared with existing methods. Furthermore, our training procedure can be easily extended to enhance other robust training strategies, highlighting its credibility and flexibility.
Read more4/19/2024