Enhancing Apparent Personality Trait Analysis with Cross-Modal Embeddings
2405.03846
0
0

Abstract
Automatic personality trait assessment is essential for high-quality human-machine interactions. Systems capable of human behavior analysis could be used for self-driving cars, medical research, and surveillance, among many others. We present a multimodal deep neural network with a Siamese extension for apparent personality trait prediction trained on short video recordings and exploiting modality invariant embeddings. Acoustic, visual, and textual information are utilized to reach high-performance solutions in this task. Due to the highly centralized target distribution of the analyzed dataset, the changes in the third digit are relevant. Our proposed method addresses the challenge of under-represented extreme values, achieves 0.0033 MAE average improvement, and shows a clear advantage over the baseline multimodal DNN without the introduced module.
Create account to get full access
Overview
- This paper presents a novel multi-modal approach for identifying schizophrenia using cross-modal data fusion.
- The researchers developed a technique to capture emotional expressions from multimodal data, including facial expressions, speech, and physiological signals.
- The proposed method selects the most relevant modalities dynamically to enhance emotion recognition in the wild.
- The paper also explores the use of multimodal deep learning for image recognition tasks.
Plain English Explanation
The researchers in this study developed a new way to detect schizophrenia by combining different types of data, such as facial expressions, speech, and physical signals. They wanted to create a system that could accurately recognize emotions from this multimodal data, even in real-world situations where conditions may not be ideal.
To do this, the team created a technique that selects the most relevant data sources at any given time to improve emotion recognition. Imagine you're trying to understand how someone is feeling based on their face, voice, and body language - this system would know which of those cues is most important in that moment and focus on that.
The researchers also looked at using multimodal deep learning for image recognition tasks. Deep learning is a powerful AI technique that can identify patterns in data, and the team explored how combining different types of data could make these systems even more accurate.
Overall, the goal of this work is to develop more robust and practical tools for detecting mental health conditions like schizophrenia, as well as improving our ability to read emotions in real-world situations. By combining multiple data sources, the researchers hope to create systems that are more reliable and effective than current approaches.
Technical Explanation
The paper presents a multi-modal approach for identifying schizophrenia using cross-modal data fusion. The researchers developed a technique to capture emotional expressions from multimodal data, including facial expressions, speech, and physiological signals.
The proposed method selects the most relevant modalities dynamically to enhance emotion recognition in the wild. This involves determining which data sources (e.g., face, voice, body) are most informative for recognizing a person's emotional state in a given situation.
The paper also explores the use of multimodal deep learning for image recognition tasks. By combining different types of data, the researchers aim to develop more robust and accurate computer vision systems.
Critical Analysis
The paper presents a promising approach for improving emotion recognition and mental health diagnosis using multimodal data. However, the researchers acknowledge several limitations and areas for further research.
One key challenge is ensuring the system works reliably in real-world conditions, where data quality and availability may be variable. The dynamic modality selection method aims to address this, but its effectiveness would need to be thoroughly tested.
Additionally, the paper does not delve deeply into the ethical implications of using such technology for mental health assessment. There are valid concerns around privacy, bias, and the potential for misuse that would need to be carefully considered.
Further research could also explore ways to make the system more interpretable, so that clinicians and patients can understand how the AI is arriving at its conclusions. Transparency is crucial for building trust in these types of diagnostic tools.
Conclusion
This paper presents an innovative multi-modal approach for identifying schizophrenia and enhancing emotion recognition in real-world settings. By fusing data from multiple sources, the researchers have developed techniques to more accurately detect mental health conditions and read emotional states.
The dynamic modality selection method and exploration of multimodal deep learning for image recognition offer promising avenues for improving the reliability and practical applicability of these types of AI systems. As the technology continues to evolve, it will be critical to address ethical considerations and ensure these tools are deployed responsibly to benefit patients and clinicians.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
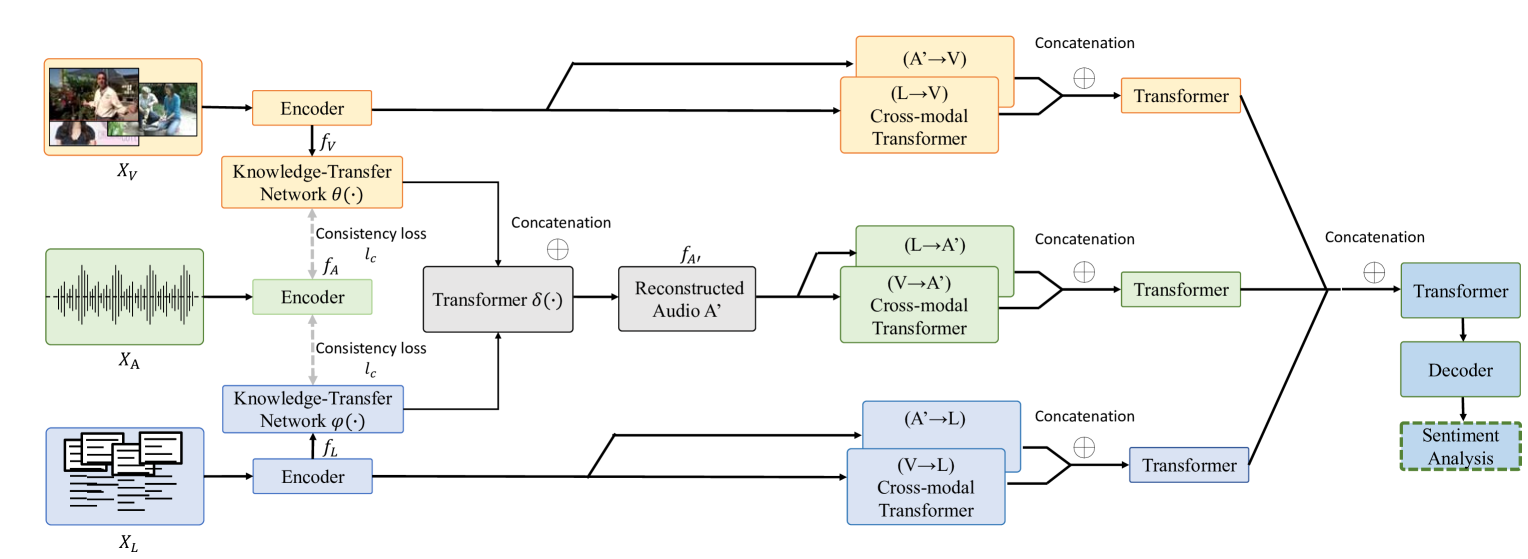
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
0
0
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
6/21/2024

A multi-modal approach for identifying schizophrenia using cross-modal attention
Gowtham Premananth, Yashish M. Siriwardena, Philip Resnik, Carol Espy-Wilson
0
0
This study focuses on how different modalities of human communication can be used to distinguish between healthy controls and subjects with schizophrenia who exhibit strong positive symptoms. We developed a multi-modal schizophrenia classification system using audio, video, and text. Facial action units and vocal tract variables were extracted as low-level features from video and audio respectively, which were then used to compute high-level coordination features that served as the inputs to the audio and video modalities. Context-independent text embeddings extracted from transcriptions of speech were used as the input for the text modality. The multi-modal system is developed by fusing a segment-to-session-level classifier for video and audio modalities with a text model based on a Hierarchical Attention Network (HAN) with cross-modal attention. The proposed multi-modal system outperforms the previous state-of-the-art multi-modal system by 8.53% in the weighted average F1 score.
4/22/2024
Unimodal Multi-Task Fusion for Emotional Mimicry Intensity Prediction
Tobias Hallmen, Fabian Deuser, Norbert Oswald, Elisabeth Andr'e
0
0
In this research, we introduce a novel methodology for assessing Emotional Mimicry Intensity (EMI) as part of the 6th Workshop and Competition on Affective Behavior Analysis in-the-wild. Our methodology utilises the Wav2Vec 2.0 architecture, which has been pre-trained on an extensive podcast dataset, to capture a wide array of audio features that include both linguistic and paralinguistic components. We refine our feature extraction process by employing a fusion technique that combines individual features with a global mean vector, thereby embedding a broader contextual understanding into our analysis. A key aspect of our approach is the multi-task fusion strategy that not only leverages these features but also incorporates a pre-trained Valence-Arousal-Dominance (VAD) model. This integration is designed to refine emotion intensity prediction by concurrently processing multiple emotional dimensions, thereby embedding a richer contextual understanding into our framework. For the temporal analysis of audio data, our feature fusion process utilises a Long Short-Term Memory (LSTM) network. This approach, which relies solely on the provided audio data, shows marked advancements over the existing baseline, offering a more comprehensive understanding of emotional mimicry in naturalistic settings, achieving the second place in the EMI challenge.
6/18/2024
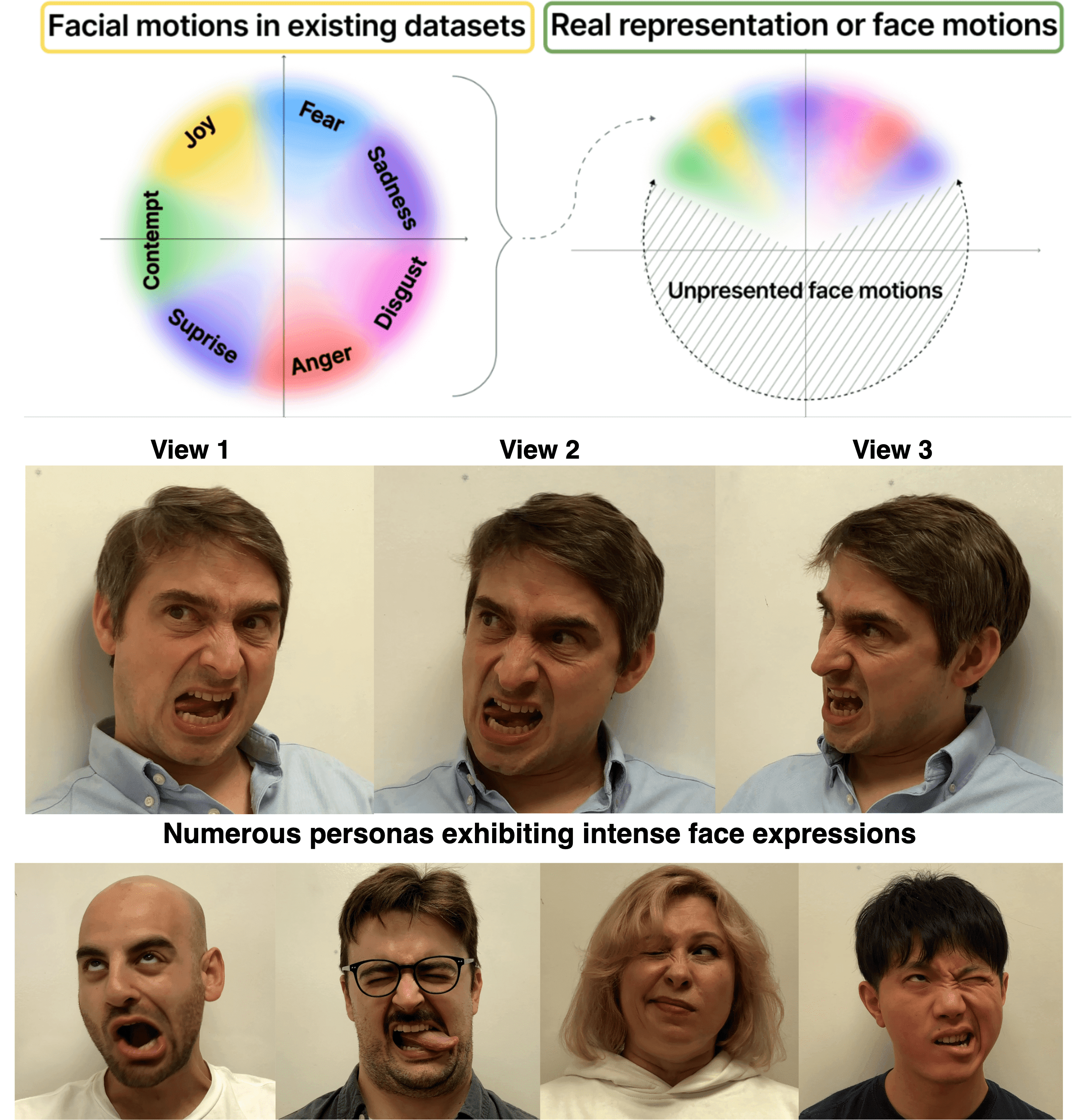
EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos Vougioukas, Zoe Landgraf, Stavros Petridis, Maja Pantic
0
0
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model's capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
5/1/2024