Research on Image Recognition Technology Based on Multimodal Deep Learning
2405.03091
0
0
🖼️
Abstract
This project investigates the human multi-modal behavior identification algorithm utilizing deep neural networks. According to the characteristics of different modal information, different deep neural networks are used to adapt to different modal video information. Through the integration of various deep neural networks, the algorithm successfully identifies behaviors across multiple modalities. In this project, multiple cameras developed by Microsoft Kinect were used to collect corresponding bone point data based on acquiring conventional images. In this way, the motion features in the image can be extracted. Ultimately, the behavioral characteristics discerned through both approaches are synthesized to facilitate the precise identification and categorization of behaviors. The performance of the suggested algorithm was evaluated using the MSR3D data set. The findings from these experiments indicate that the accuracy in recognizing behaviors remains consistently high, suggesting that the algorithm is reliable in various scenarios. Additionally, the tests demonstrate that the algorithm substantially enhances the accuracy of detecting pedestrian behaviors in video footage.
Create account to get full access
Overview
- This research project investigates a deep neural network-based algorithm for identifying human multi-modal behaviors.
- The algorithm uses different deep neural networks to process various types of video data, such as conventional images and bone point data from Microsoft Kinect sensors.
- By integrating the insights from these different neural networks, the algorithm can accurately identify and categorize human behaviors across multiple modalities.
- The performance of the algorithm was evaluated using the MSR3D dataset, and the results demonstrate high accuracy in detecting pedestrian behaviors in video footage.
Plain English Explanation
In this research, the scientists developed a machine learning algorithm that can identify and classify different human behaviors by analyzing video footage from multiple sources. Instead of just looking at the regular video images, the algorithm also uses data from specialized sensors (like the Microsoft Kinect) that can track the movements of people's body parts.
The key idea is to use different deep neural networks - a type of AI model - to process the different types of video data. One network might focus on the overall visual information in the video, while another network analyzes the precise movements of the person's joints and limbs. By combining the insights from these various networks, the algorithm can get a more complete understanding of the human behavior being observed.
The researchers tested this algorithm on a dataset of video footage, and found that it was able to accurately identify and classify different types of behaviors, like how people walk. This suggests the algorithm could be useful for applications like video surveillance or activity tracking, where quickly and reliably detecting human actions is important.
Technical Explanation
The researchers in this project developed a multi-modal behavior identification algorithm that leverages deep neural networks to process different types of video data. Specifically, they utilized conventional video images as well as bone point data captured by Microsoft Kinect sensors to extract motion features and behavioral characteristics.
Different deep neural network architectures were employed to handle the varying modalities of the input data. For example, one network may have been specialized for processing the raw image data, while another focused on the skeletal movement information from the Kinect sensors. By integrating the outputs of these specialized networks, the algorithm was able to synthesize a comprehensive understanding of the observed behaviors.
The performance of the proposed algorithm was evaluated using the MSR3D dataset. The results demonstrated that the multi-modal approach was able to achieve high accuracy in recognizing human behaviors, outperforming approaches that only relied on a single data modality. This suggests the algorithm is reliable and can be effectively applied to real-world scenarios, such as enhancing the detection of pedestrian activities in video surveillance systems.
Critical Analysis
The paper provides a compelling demonstration of how leveraging multi-modal data and specialized deep neural networks can lead to improved performance in human behavior identification tasks. However, the research does not deeply explore potential limitations or caveats of the proposed approach.
For example, the paper does not discuss how the algorithm might handle occlusions, lighting changes, or other challenging real-world conditions that could impact the reliability of the behavior recognition. There is also no analysis of the computational costs or runtime requirements of the multi-network architecture, which could be an important consideration for practical deployments.
Additionally, the paper focuses solely on evaluating the algorithm's accuracy, without providing much insight into the types of behaviors it can effectively detect or the nuances of its performance across different behavior categories. Further research could explore the algorithm's ability to generalize to a wider range of human activities and its potential biases or weaknesses.
Overall, while the paper presents a promising technical approach, a more thorough critical examination of the algorithm's capabilities, limitations, and potential societal implications would provide a more comprehensive understanding of its merits and drawbacks.
Conclusion
This research project developed a multi-modal deep learning algorithm for identifying and classifying human behaviors in video footage. By leveraging complementary data sources, such as conventional images and skeletal movement data, and integrating specialized neural networks, the algorithm demonstrated high accuracy in recognizing a variety of human actions.
The successful performance of this approach suggests that combining multiple data modalities and tailored deep learning models can lead to significant improvements in computer vision tasks like behavior recognition. This has important implications for applications such as video surveillance, activity tracking, and human-computer interaction, where reliable real-time detection of human actions is crucial.
While the paper provides an encouraging technical demonstration, further research is needed to fully explore the limitations, robustness, and broader societal impacts of this type of multi-modal behavior identification system. Nonetheless, this work represents an important step forward in leveraging the complementary nature of different sensor data and neural network architectures to enhance our ability to perceive and understand human behavior.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Research on Optimization of Natural Language Processing Model Based on Multimodal Deep Learning
Dan Sun, Yaxin Liang, Yining Yang, Yuhan Ma, Qishi Zhan, Erdi Gao
0
0
This project intends to study the image representation based on attention mechanism and multimodal data. By adding multiple pattern layers to the attribute model, the semantic and hidden layers of image content are integrated. The word vector is quantified by the Word2Vec method and then evaluated by a word embedding convolutional neural network. The published experimental results of the two groups were tested. The experimental results show that this method can convert discrete features into continuous characters, thus reducing the complexity of feature preprocessing. Word2Vec and natural language processing technology are integrated to achieve the goal of direct evaluation of missing image features. The robustness of the image feature evaluation model is improved by using the excellent feature analysis characteristics of a convolutional neural network. This project intends to improve the existing image feature identification methods and eliminate the subjective influence in the evaluation process. The findings from the simulation indicate that the novel approach has developed is viable, effectively augmenting the features within the produced representations.
6/14/2024
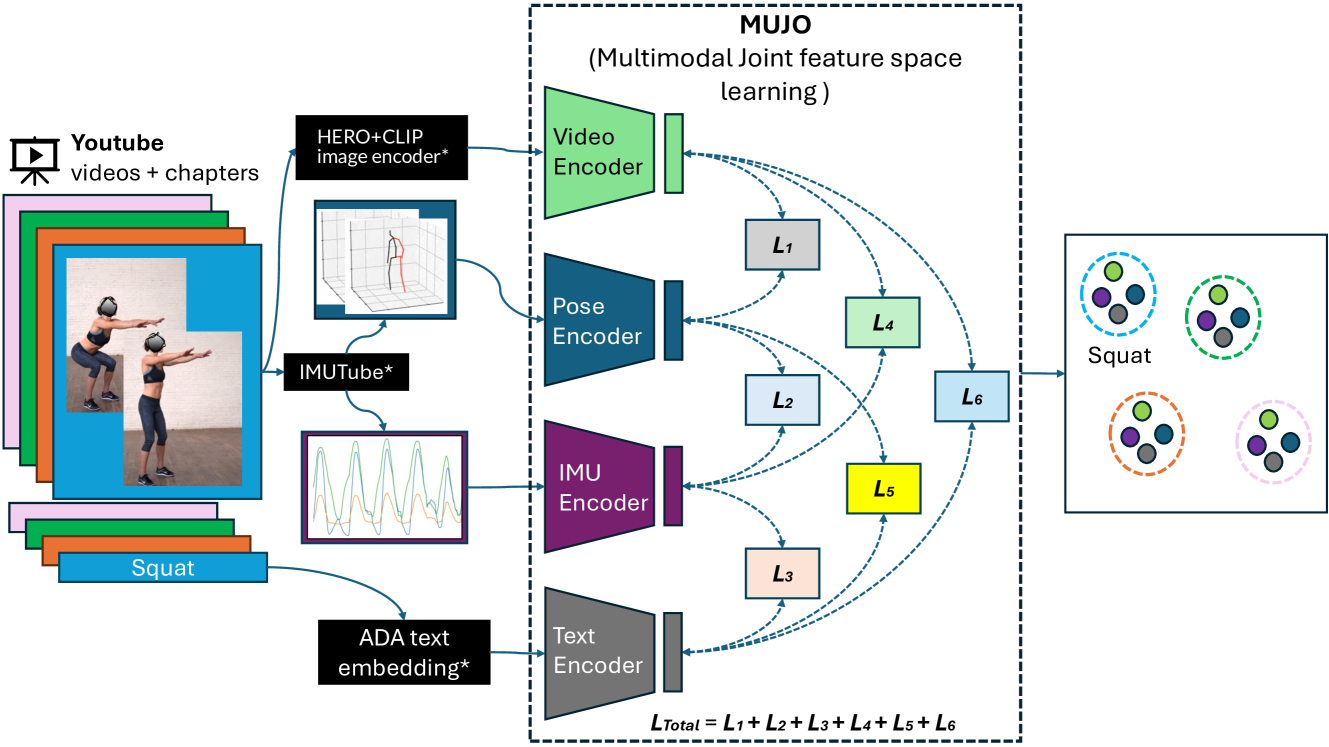
MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
Stefan Gerd Fritsch, Cennet Oguz, Vitor Fortes Rey, Lala Ray, Maximilian Kiefer-Emmanouilidis, Paul Lukowicz
0
0
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
6/7/2024
🤔
From CNNs to Transformers in Multimodal Human Action Recognition: A Survey
Muhammad Bilal Shaikh, Syed Mohammed Shamsul Islam, Douglas Chai, Naveed Akhtar
0
0
Due to its widespread applications, human action recognition is one of the most widely studied research problems in Computer Vision. Recent studies have shown that addressing it using multimodal data leads to superior performance as compared to relying on a single data modality. During the adoption of deep learning for visual modelling in the last decade, action recognition approaches have mainly relied on Convolutional Neural Networks (CNNs). However, the recent rise of Transformers in visual modelling is now also causing a paradigm shift for the action recognition task. This survey captures this transition while focusing on Multimodal Human Action Recognition (MHAR). Unique to the induction of multimodal computational models is the process of fusing the features of the individual data modalities. Hence, we specifically focus on the fusion design aspects of the MHAR approaches. We analyze the classic and emerging techniques in this regard, while also highlighting the popular trends in the adaption of CNN and Transformer building blocks for the overall problem. In particular, we emphasize on recent design choices that have led to more efficient MHAR models. Unlike existing reviews, which discuss Human Action Recognition from a broad perspective, this survey is specifically aimed at pushing the boundaries of MHAR research by identifying promising architectural and fusion design choices to train practicable models. We also provide an outlook of the multimodal datasets from their scale and evaluation viewpoint. Finally, building on the reviewed literature, we discuss the challenges and future avenues for MHAR.
5/28/2024
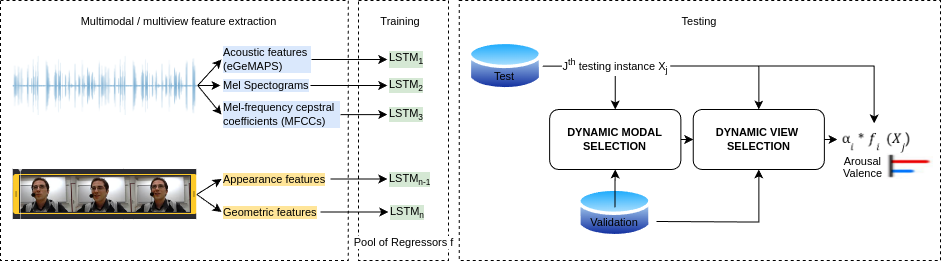
Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Luciana Trinkaus Menon, Luiz Carlos Ribeiro Neduziak, Jean Paul Barddal, Alessandro Lameiras Koerich, Alceu de Souza Britto Jr
0
0
The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
4/19/2024