Enhancing Clinical Documentation with Synthetic Data: Leveraging Generative Models for Improved Accuracy
2406.06569
0
0
🎯
Abstract
Accurate and comprehensive clinical documentation is crucial for delivering high-quality healthcare, facilitating effective communication among providers, and ensuring compliance with regulatory requirements. However, manual transcription and data entry processes can be time-consuming, error-prone, and susceptible to inconsistencies, leading to incomplete or inaccurate medical records. This paper proposes a novel approach to augment clinical documentation by leveraging synthetic data generation techniques to generate realistic and diverse clinical transcripts. We present a methodology that combines state-of-the-art generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), with real-world clinical transcript and other forms of clinical data to generate synthetic transcripts. These synthetic transcripts can then be used to supplement existing documentation workflows, providing additional training data for natural language processing models and enabling more accurate and efficient transcription processes. Through extensive experiments on a large dataset of anonymized clinical transcripts, we demonstrate the effectiveness of our approach in generating high-quality synthetic transcripts that closely resemble real-world data. Quantitative evaluation metrics, including perplexity scores and BLEU scores, as well as qualitative assessments by domain experts, validate the fidelity and utility of the generated synthetic transcripts. Our findings highlight synthetic data generation's potential to address clinical documentation challenges, improving patient care, reducing administrative burdens, and enhancing healthcare system efficiency.
Create account to get full access
Overview
- Accurate and comprehensive clinical documentation is crucial for high-quality healthcare, effective communication among providers, and regulatory compliance.
- Manual transcription and data entry processes can be time-consuming, error-prone, and lead to inconsistent medical records.
- This paper proposes using synthetic data generation techniques to generate realistic and diverse clinical transcripts that can supplement existing documentation workflows.
Plain English Explanation
The paper discusses the importance of accurate and comprehensive clinical documentation in healthcare. Detailed and consistent medical records are essential for providing high-quality patient care, allowing healthcare providers to effectively communicate with each other, and ensuring compliance with regulations.
However, manually creating these records through transcription and data entry can be a slow and error-prone process, leading to incomplete or inaccurate information in the medical files. To address this, the researchers propose using advanced artificial intelligence (AI) techniques to generate realistic-looking synthetic clinical transcripts.
These computer-generated transcripts can then be used to supplement the existing documentation workflow. For example, they could be used to provide additional training data for natural language processing models, helping to make transcription more accurate and efficient. The researchers test their approach on a large dataset of anonymized clinical transcripts and find that the synthetic transcripts closely match the real-world data, as validated by both quantitative metrics and expert reviews.
Overall, the goal is to leverage AI to improve the clinical documentation process, which in turn can enhance patient care, reduce administrative burdens, and make the healthcare system more efficient.
Technical Explanation
The paper presents a novel approach to augmenting clinical documentation by generating synthetic clinical transcripts using advanced generative models. The researchers combine state-of-the-art techniques like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) with real-world clinical transcript data and other relevant clinical information to create realistic-looking synthetic transcripts.
Through extensive experiments on a large dataset of anonymized clinical transcripts, the researchers demonstrate the effectiveness of their approach. They evaluate the synthetic transcripts using both quantitative metrics, such as perplexity scores and BLEU scores, as well as qualitative assessments by domain experts. The results show that the generated synthetic transcripts closely resemble the real-world data in terms of fidelity and utility.
The researchers envision these synthetic transcripts being used to supplement existing clinical documentation workflows, providing additional training data for natural language processing models to improve transcription accuracy and efficiency. This could ultimately lead to more complete and accurate medical records, enhancing patient care, reducing administrative burdens, and improving the overall efficiency of the healthcare system.
Critical Analysis
The paper presents a promising approach to addressing the challenges of clinical documentation, but it also acknowledges several limitations and areas for further research. For example, the researchers note that their methodology relies on access to a large dataset of anonymized clinical transcripts, which may not be readily available in all healthcare settings.
Additionally, while the synthetic transcripts are evaluated for fidelity and utility, the paper does not provide a detailed analysis of the potential risks or unintended consequences of using AI-generated content in clinical documentation. Concerns around data privacy, bias, and ethical considerations should be carefully addressed before widespread adoption of such techniques.
Further research may also be needed to understand the long-term impact of incorporating synthetic data into clinical workflows, including its effects on provider-patient relationships, billing and reimbursement processes, and regulatory compliance. Ongoing work in related areas may provide valuable insights and lessons learned to help guide the development and implementation of this approach.
Conclusion
This paper presents a promising approach to generating synthetic electronic health records that can be used to supplement and enhance clinical documentation processes. By leveraging state-of-the-art generative AI techniques, the researchers demonstrate the ability to create realistic and diverse synthetic clinical transcripts that closely match real-world data.
If successfully implemented, this approach has the potential to improve the accuracy and efficiency of clinical documentation, leading to better patient care, reduced administrative burdens, and increased healthcare system efficiency. However, the researchers acknowledge the need to address potential risks and limitations, as well as to continue exploring the long-term implications of incorporating synthetic data into clinical workflows.
Overall, this research represents an important step towards leveraging AI to address the challenges of clinical documentation and ultimately enhance the quality and delivery of healthcare services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Intelligent Clinical Documentation: Harnessing Generative AI for Patient-Centric Clinical Note Generation
Anjanava Biswas, Wrick Talukdar
0
0
Comprehensive clinical documentation is crucial for effective healthcare delivery, yet it poses a significant burden on healthcare professionals, leading to burnout, increased medical errors, and compromised patient safety. This paper explores the potential of generative AI (Artificial Intelligence) to streamline the clinical documentation process, specifically focusing on generating SOAP (Subjective, Objective, Assessment, Plan) and BIRP (Behavior, Intervention, Response, Plan) notes. We present a case study demonstrating the application of natural language processing (NLP) and automatic speech recognition (ASR) technologies to transcribe patient-clinician interactions, coupled with advanced prompting techniques to generate draft clinical notes using large language models (LLMs). The study highlights the benefits of this approach, including time savings, improved documentation quality, and enhanced patient-centered care. Additionally, we discuss ethical considerations, such as maintaining patient confidentiality and addressing model biases, underscoring the need for responsible deployment of generative AI in healthcare settings. The findings suggest that generative AI has the potential to revolutionize clinical documentation practices, alleviating administrative burdens and enabling healthcare professionals to focus more on direct patient care.
5/29/2024
💬
Utilizing Large Language Models to Generate Synthetic Data to Increase the Performance of BERT-Based Neural Networks
Chancellor R. Woolsey, Prakash Bisht, Joshua Rothman, Gondy Leroy
0
0
An important issue impacting healthcare is a lack of available experts. Machine learning (ML) models could resolve this by aiding in diagnosing patients. However, creating datasets large enough to train these models is expensive. We evaluated large language models (LLMs) for data creation. Using Autism Spectrum Disorders (ASD), we prompted ChatGPT and GPT-Premium to generate 4,200 synthetic observations to augment existing medical data. Our goal is to label behaviors corresponding to autism criteria and improve model accuracy with synthetic training data. We used a BERT classifier pre-trained on biomedical literature to assess differences in performance between models. A random sample (N=140) from the LLM-generated data was evaluated by a clinician and found to contain 83% correct example-label pairs. Augmenting data increased recall by 13% but decreased precision by 16%, correlating with higher quality and lower accuracy across pairs. Future work will analyze how different synthetic data traits affect ML outcomes.
5/14/2024

SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Prakamya Mishra, Zonghai Yao, Parth Vashisht, Feiyun Ouyang, Beining Wang, Vidhi Dhaval Mody, Hong Yu
0
0
Large Language Models (LLMs) such as GPT & Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes >100B parameter GPT variants like GPT-3.5 & GPT-4 to act as synthetic experts to generate high-quality synthetics feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback generated by these synthetic feedback experts without additional human annotations, mirroring and optimizing the practical scenario in which medical professionals refine AI system outputs. Although such 100B+ parameter GPT variants have proven to demonstrate expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on their capacity to act as synthetic feedback experts and deliver expert-level edit feedback for improving the generation quality of weaker (<10B parameter) LLMs like GPT-2 (1.5B) & Llama 2 (7B) in clinical domain. So in this work, we leverage 100B+ GPT variants to act as synthetic feedback experts offering expert-level edit feedback, that is used to reduce hallucinations and align weaker (<10B parameter) LLMs with medical facts using two distinct alignment algorithms (DPO & SALT), endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of LLM-based synthetic edits in enhancing the alignment of clinical factuality.
4/19/2024
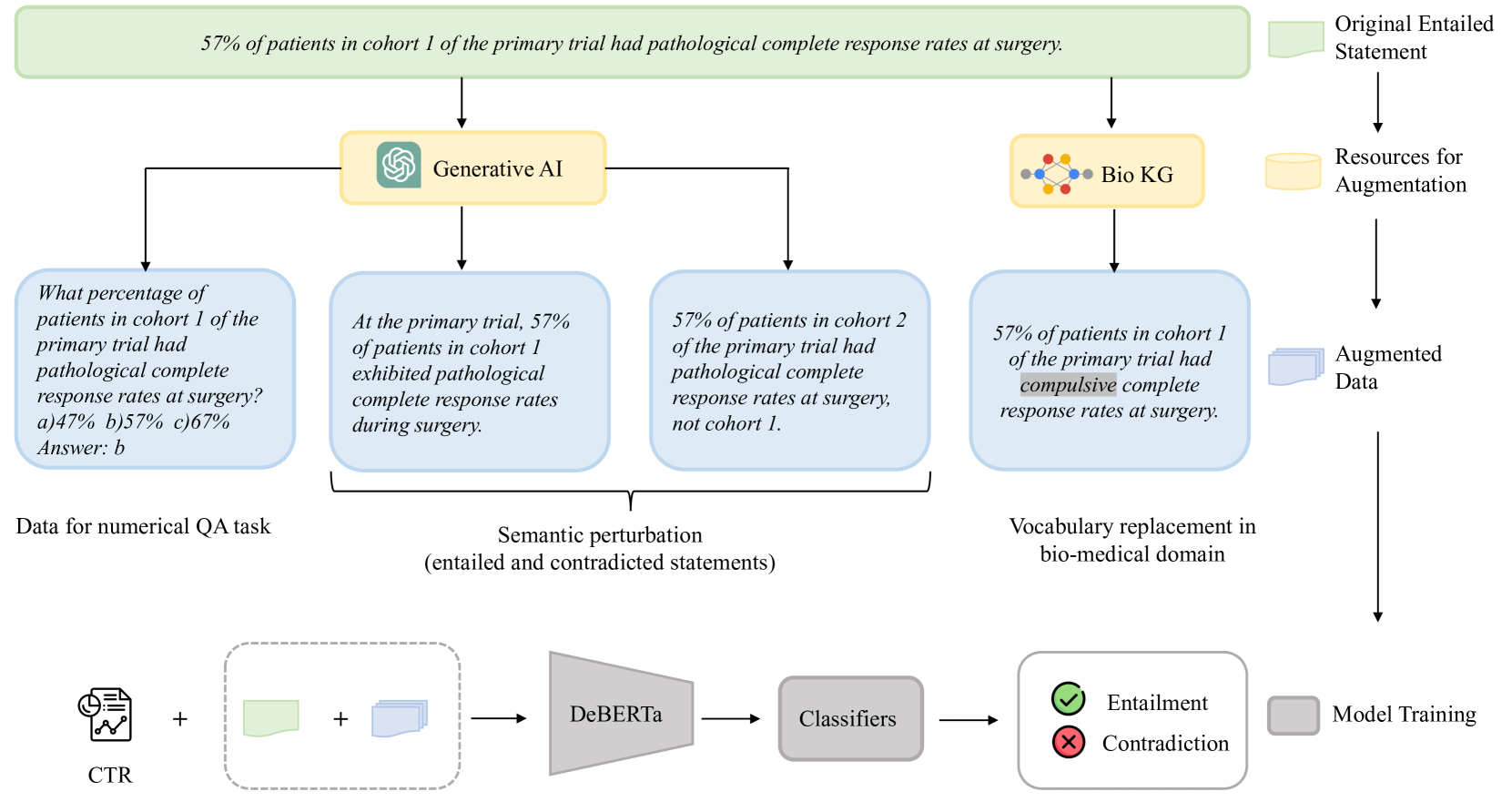
DKE-Research at SemEval-2024 Task 2: Incorporating Data Augmentation with Generative Models and Biomedical Knowledge to Enhance Inference Robustness
Yuqi Wang, Zeqiang Wang, Wei Wang, Qi Chen, Kaizhu Huang, Anh Nguyen, Suparna De
0
0
Safe and reliable natural language inference is critical for extracting insights from clinical trial reports but poses challenges due to biases in large pre-trained language models. This paper presents a novel data augmentation technique to improve model robustness for biomedical natural language inference in clinical trials. By generating synthetic examples through semantic perturbations and domain-specific vocabulary replacement and adding a new task for numerical and quantitative reasoning, we introduce greater diversity and reduce shortcut learning. Our approach, combined with multi-task learning and the DeBERTa architecture, achieved significant performance gains on the NLI4CT 2024 benchmark compared to the original language models. Ablation studies validate the contribution of each augmentation method in improving robustness. Our best-performing model ranked 12th in terms of faithfulness and 8th in terms of consistency, respectively, out of the 32 participants.
4/16/2024