SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
2402.13919
0
0

Abstract
Large Language Models (LLMs) such as GPT & Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes >100B parameter GPT variants like GPT-3.5 & GPT-4 to act as synthetic experts to generate high-quality synthetics feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback generated by these synthetic feedback experts without additional human annotations, mirroring and optimizing the practical scenario in which medical professionals refine AI system outputs. Although such 100B+ parameter GPT variants have proven to demonstrate expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on their capacity to act as synthetic feedback experts and deliver expert-level edit feedback for improving the generation quality of weaker (<10B parameter) LLMs like GPT-2 (1.5B) & Llama 2 (7B) in clinical domain. So in this work, we leverage 100B+ GPT variants to act as synthetic feedback experts offering expert-level edit feedback, that is used to reduce hallucinations and align weaker (<10B parameter) LLMs with medical facts using two distinct alignment algorithms (DPO & SALT), endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of LLM-based synthetic edits in enhancing the alignment of clinical factuality.
Create account to get full access
Overview
- The paper proposes a novel approach called SYNFAC-EDIT to improve the factual alignment of clinical summaries generated by language models.
- The method involves using synthetic feedback in the form of edits to fine-tune the language model, guiding it to generate more factually consistent summaries.
- The authors evaluate SYNFAC-EDIT on several clinical summarization datasets and show significant improvements in factual accuracy compared to existing approaches.
Plain English Explanation
The paper focuses on the challenge of ensuring that summaries generated by AI language models are factually accurate, especially in sensitive domains like healthcare. The authors recognize that while language models can produce fluent and coherent text, they can also hallucinate or "make up" facts that are not present in the original source material.
To address this, the researchers developed a technique called SYNFAC-EDIT. The key idea is to provide the language model with synthetic feedback in the form of example edits that correct factual mistakes. By fine-tuning the model on these synthetic edits, they aim to nudge it towards generating summaries that are more closely aligned with the facts in the source documents.
The authors evaluate SYNFAC-EDIT on several benchmark datasets for clinical summarization and demonstrate that it outperforms existing approaches in terms of factual accuracy. This suggests that providing targeted feedback to language models can be an effective way to improve their ability to produce truthful and reliable summaries, which is particularly important in high-stakes domains like healthcare.
Technical Explanation
The paper introduces a novel approach called SYNFAC-EDIT (Synthetic Imitation Edit Feedback for Factual Alignment) to improve the factual alignment of clinical summaries generated by language models. The core idea is to fine-tune the language model using synthetic feedback in the form of edits that correct factual mistakes, with the goal of guiding the model to generate more factually consistent summaries.
The SYNFAC-EDIT framework consists of three main components:
- Fact Extractor: This module extracts factual statements from the source documents using a pre-trained fact extraction model.
- Fact Aligner: The fact aligner matches the extracted facts with the corresponding facts in the reference summary, identifying any discrepancies.
- Edit Generator: Based on the fact alignment, this component generates synthetic edits that correct the factual mistakes in the model's output.
During fine-tuning, the language model is trained on the original source-summary pairs as well as the synthetic edit feedback, encouraging it to generate summaries that better align with the facts in the source documents.
The authors evaluate SYNFAC-EDIT on several clinical summarization datasets, including MEDIQA, CHEBEC, and an in-house dataset. Their results demonstrate that SYNFAC-EDIT significantly outperforms existing approaches in terms of factual accuracy, while maintaining competitive performance on other summary quality metrics.
Critical Analysis
The authors have made a thoughtful contribution to the field of clinical summarization by addressing the crucial issue of factual alignment. The SYNFAC-EDIT approach is a novel and promising solution that leverages synthetic edit feedback to fine-tune language models, guiding them towards more factually consistent outputs.
One potential limitation of the study is the reliance on pre-trained fact extraction and alignment models, which may introduce errors or biases. The authors acknowledge this and suggest the need for further research on improving the robustness and accuracy of these underlying components.
Additionally, the authors focus primarily on factual accuracy, but the broader quality and usefulness of the generated summaries could also be an important consideration. Future work could explore ways to balance factual alignment with other summary quality metrics, such as coherence, conciseness, and relevance.
Another area for further exploration is the generalizability of SYNFAC-EDIT beyond the clinical domain. While the authors demonstrate its effectiveness in the healthcare context, it would be valuable to investigate the applicability of the approach to other domains where factual accuracy is critical, such as news summarization or policy analysis.
Overall, the SYNFAC-EDIT paper makes a significant contribution to the field of language model-based summarization, particularly in the context of clinical applications. The authors have proposed a novel and promising solution to the challenge of factual alignment, which has important implications for the safe and reliable deployment of AI systems in high-stakes domains.
Conclusion
The SYNFAC-EDIT paper presents a novel approach to improving the factual alignment of clinical summaries generated by language models. By fine-tuning the models using synthetic edit feedback that corrects factual mistakes, the authors demonstrate significant improvements in factual accuracy across multiple benchmark datasets.
This research highlights the importance of addressing factual consistency in language model-based summarization, especially in sensitive domains like healthcare. The SYNFAC-EDIT framework offers a promising direction for further developing more reliable and trustworthy AI-generated summaries, with potential applications beyond the clinical context.
As language models continue to advance and become more influential in various decision-making processes, ensuring their outputs are grounded in facts and reality will be crucial. The SYNFAC-EDIT paper represents an important step forward in this direction, and its insights could inspire further innovations in the field of trustworthy and accountable AI-powered text generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
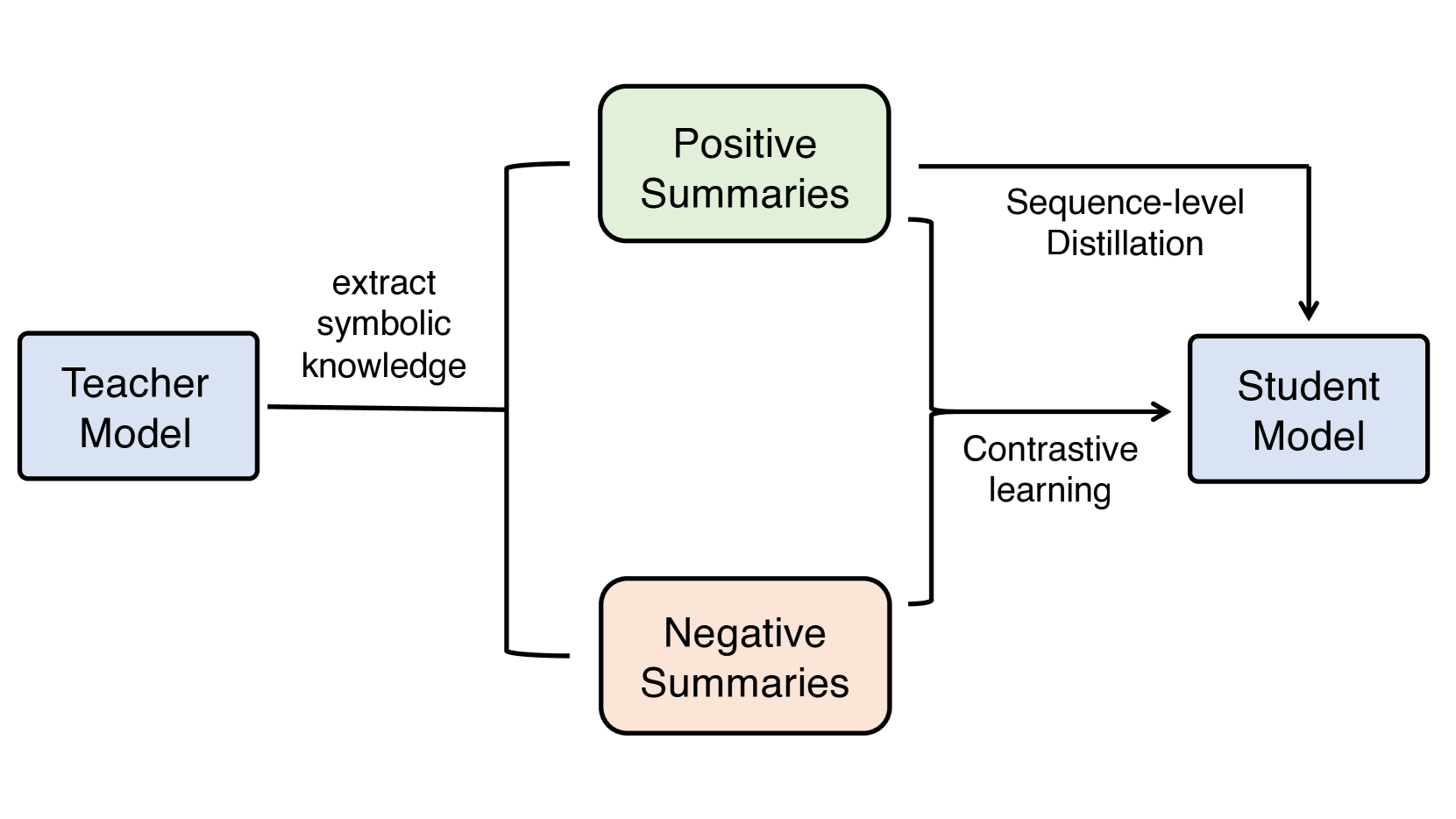
Factual Dialogue Summarization via Learning from Large Language Models
Rongxin Zhu, Jey Han Lau, Jianzhong Qi
0
0
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.
6/24/2024
💬
FLAME: Factuality-Aware Alignment for Large Language Models
Sheng-Chieh Lin, Luyu Gao, Barlas Oguz, Wenhan Xiong, Jimmy Lin, Wen-tau Yih, Xilun Chen
0
0
Alignment is a standard procedure to fine-tune pre-trained large language models (LLMs) to follow natural language instructions and serve as helpful AI assistants. We have observed, however, that the conventional alignment process fails to enhance the factual accuracy of LLMs, and often leads to the generation of more false facts (i.e. hallucination). In this paper, we study how to make the LLM alignment process more factual, by first identifying factors that lead to hallucination in both alignment steps: supervised fine-tuning (SFT) and reinforcement learning (RL). In particular, we find that training the LLM on new knowledge or unfamiliar texts can encourage hallucination. This makes SFT less factual as it trains on human labeled data that may be novel to the LLM. Furthermore, reward functions used in standard RL can also encourage hallucination, because it guides the LLM to provide more helpful responses on a diverse set of instructions, often preferring longer and more detailed responses. Based on these observations, we propose factuality-aware alignment, comprised of factuality-aware SFT and factuality-aware RL through direct preference optimization. Experiments show that our proposed factuality-aware alignment guides LLMs to output more factual responses while maintaining instruction-following capability.
5/3/2024
🎯
Enhancing Clinical Documentation with Synthetic Data: Leveraging Generative Models for Improved Accuracy
Anjanava Biswas, Wrick Talukdar
0
0
Accurate and comprehensive clinical documentation is crucial for delivering high-quality healthcare, facilitating effective communication among providers, and ensuring compliance with regulatory requirements. However, manual transcription and data entry processes can be time-consuming, error-prone, and susceptible to inconsistencies, leading to incomplete or inaccurate medical records. This paper proposes a novel approach to augment clinical documentation by leveraging synthetic data generation techniques to generate realistic and diverse clinical transcripts. We present a methodology that combines state-of-the-art generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), with real-world clinical transcript and other forms of clinical data to generate synthetic transcripts. These synthetic transcripts can then be used to supplement existing documentation workflows, providing additional training data for natural language processing models and enabling more accurate and efficient transcription processes. Through extensive experiments on a large dataset of anonymized clinical transcripts, we demonstrate the effectiveness of our approach in generating high-quality synthetic transcripts that closely resemble real-world data. Quantitative evaluation metrics, including perplexity scores and BLEU scores, as well as qualitative assessments by domain experts, validate the fidelity and utility of the generated synthetic transcripts. Our findings highlight synthetic data generation's potential to address clinical documentation challenges, improving patient care, reducing administrative burdens, and enhancing healthcare system efficiency.
6/12/2024
📊
New!From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data
Zheyang Xiong, Vasilis Papageorgiou, Kangwook Lee, Dimitris Papailiopoulos
0
0
Recent studies have shown that Large Language Models (LLMs) struggle to accurately retrieve information and maintain reasoning capabilities when processing long-context inputs. To address these limitations, we propose a finetuning approach utilizing a carefully designed synthetic dataset comprising numerical key-value retrieval tasks. Our experiments on models like GPT-3.5 Turbo and Mistral 7B demonstrate that finetuning LLMs on this dataset significantly improves LLMs' information retrieval and reasoning capabilities in longer-context settings. We present an analysis of the finetuned models, illustrating the transfer of skills from synthetic to real task evaluations (e.g., $10.5%$ improvement on $20$ documents MDQA at position $10$ for GPT-3.5 Turbo). We also find that finetuned LLMs' performance on general benchmarks remains almost constant while LLMs finetuned on other baseline long-context augmentation data can encourage hallucination (e.g., on TriviaQA, Mistral 7B finetuned on our synthetic data cause no performance drop while other baseline data can cause a drop that ranges from $2.33%$ to $6.19%$). Our study highlights the potential of finetuning on synthetic data for improving the performance of LLMs on longer-context tasks.
6/28/2024