Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience
2404.10315
0
0

Abstract
Large Language Models (LLMs) have exhibited remarkable performance across various downstream tasks, but they may generate inaccurate or false information with a confident tone. One of the possible solutions is to empower the LLM confidence expression capability, in which the confidence expressed can be well-aligned with the true probability of the generated answer being correct. However, leveraging the intrinsic ability of LLMs or the signals from the output logits of answers proves challenging in accurately capturing the response uncertainty in LLMs. Therefore, drawing inspiration from cognitive diagnostics, we propose a method of Learning from Past experience (LePe) to enhance the capability for confidence expression. Specifically, we first identify three key problems: (1) How to capture the inherent confidence of the LLM? (2) How to teach the LLM to express confidence? (3) How to evaluate the confidence expression of the LLM? Then we devise three stages in LePe to deal with these problems. Besides, to accurately capture the confidence of an LLM when constructing the training data, we design a complete pipeline including question preparation and answer sampling. We also conduct experiments using the Llama family of LLMs to verify the effectiveness of our proposed method on four datasets.
Create account to get full access
Overview
- This paper explores techniques to enhance the confidence expression of large language models (LLMs) by learning from their past experiences.
- The researchers investigate ways to improve LLMs' ability to accurately assess and express their own uncertainty, which is crucial for their safe and reliable deployment.
- The paper proposes novel training approaches and evaluates their impact on the models' confidence calibration and task performance.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and perform a wide range of language-related tasks. However, these models can sometimes be overconfident or uncertain about their own abilities, which can lead to problems when they are used in real-world applications.
This research paper looks at ways to improve the confidence expression of LLMs, so that they can better communicate their level of certainty or uncertainty to the humans they interact with. The researchers explore training approaches that allow the models to learn from their past experiences and better understand their own strengths and limitations.
By improving the models' self-awareness and ability to express their confidence levels accurately, the researchers aim to make LLMs more reliable and trustworthy, which is essential for their safe and widespread adoption in areas like healthcare, finance, and decision-making.
Technical Explanation
The paper proposes two main approaches to enhance the confidence expression of LLMs:
-
Past Experience Learning (PEL): This technique involves training the LLM to learn from its own past experiences, including its successes and failures. The model is exposed to a diverse set of tasks and is encouraged to learn from the feedback it receives, allowing it to better calibrate its confidence levels.
-
Uncertainty-Aware Training (UAT): This approach incorporates explicit uncertainty modeling into the LLM's training process. The model is trained to not only generate output, but also to estimate the uncertainty associated with its predictions. This helps the model better express its level of confidence in its responses.
The researchers evaluate these techniques on a range of language tasks and find that they can significantly improve the models' confidence calibration, without compromising their overall performance. The models trained with PEL and UAT are better able to assess and communicate their uncertainty, making them more reliable and trustworthy in real-world applications.
Critical Analysis
The paper presents a thoughtful and systematic approach to enhancing the confidence expression of LLMs, which is an important challenge in the field of AI safety and reliability. The proposed techniques, PEL and UAT, are well-grounded in existing research on uncertainty quantification and self-awareness in large language models.
One potential limitation of the study is the relatively narrow scope of the language tasks used for evaluation. While the researchers demonstrate the effectiveness of their approaches on a range of tasks, it would be valuable to explore their performance in more diverse and domain-specific applications, where the models' confidence expression may be even more crucial.
Additionally, the paper does not delve deeply into the potential societal implications of more reliable and trustworthy LLMs. As these models become more widely deployed, it will be important to consider the ethical and regulatory considerations around their use, particularly in high-stakes decision-making scenarios.
Conclusion
This research paper presents promising approaches to enhancing the confidence expression of large language models, which is a crucial step towards their safe and reliable deployment in real-world applications. By incorporating techniques that allow LLMs to learn from their past experiences and model their own uncertainty, the researchers have demonstrated a path towards more trustworthy and self-aware AI systems.
As LLMs continue to advance and become increasingly integrated into our lives, the ability to accurately assess and communicate confidence will be essential for building human trust and ensuring the responsible development of this transformative technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Model Confidence Estimation via Black-Box Access
Tejaswini Pedapati, Amit Dhurandhar, Soumya Ghosh, Soham Dan, Prasanna Sattigeri
0
0
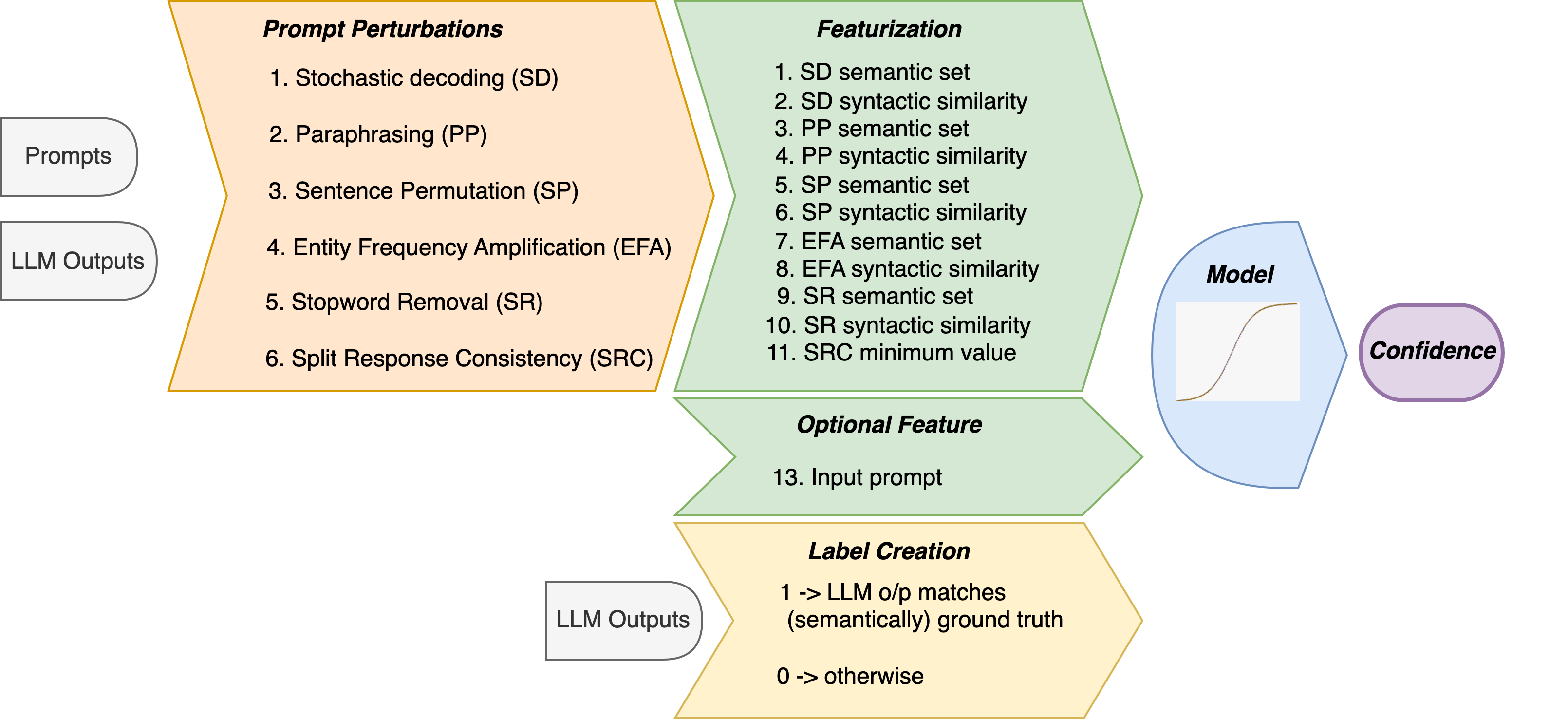
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
6/10/2024
Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models
Loka Li, Zhenhao Chen, Guangyi Chen, Yixuan Zhang, Yusheng Su, Eric Xing, Kun Zhang
0
0
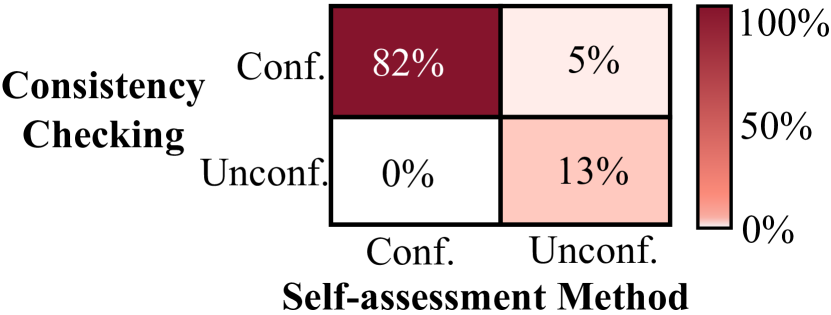
The recent success of Large Language Models (LLMs) has catalyzed an increasing interest in their self-correction capabilities. This paper presents a comprehensive investigation into the intrinsic self-correction of LLMs, attempting to address the ongoing debate about its feasibility. Our research has identified an important latent factor - the confidence of LLMs - during the self-correction process. Overlooking this factor may cause the models to over-criticize themselves, resulting in unreliable conclusions regarding the efficacy of self-correction. We have experimentally observed that LLMs possess the capability to understand the confidence in their own responses. It motivates us to develop an If-or-Else (IoE) prompting framework, designed to guide LLMs in assessing their own confidence, facilitating intrinsic self-corrections. We conduct extensive experiments and demonstrate that our IoE-based Prompt can achieve a consistent improvement regarding the accuracy of self-corrected responses over the initial answers. Our study not only sheds light on the underlying factors affecting self-correction in LLMs, but also introduces a practical framework that utilizes the IoE prompting principle to efficiently improve self-correction capabilities with confidence. The code is available at https://github.com/MBZUAI-CLeaR/IoE-Prompting.git.
5/14/2024
A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Boyang Xue, Hongru Wang, Rui Wang, Sheng Wang, Zezhong Wang, Yiming Du, Kam-Fai Wong
0
0
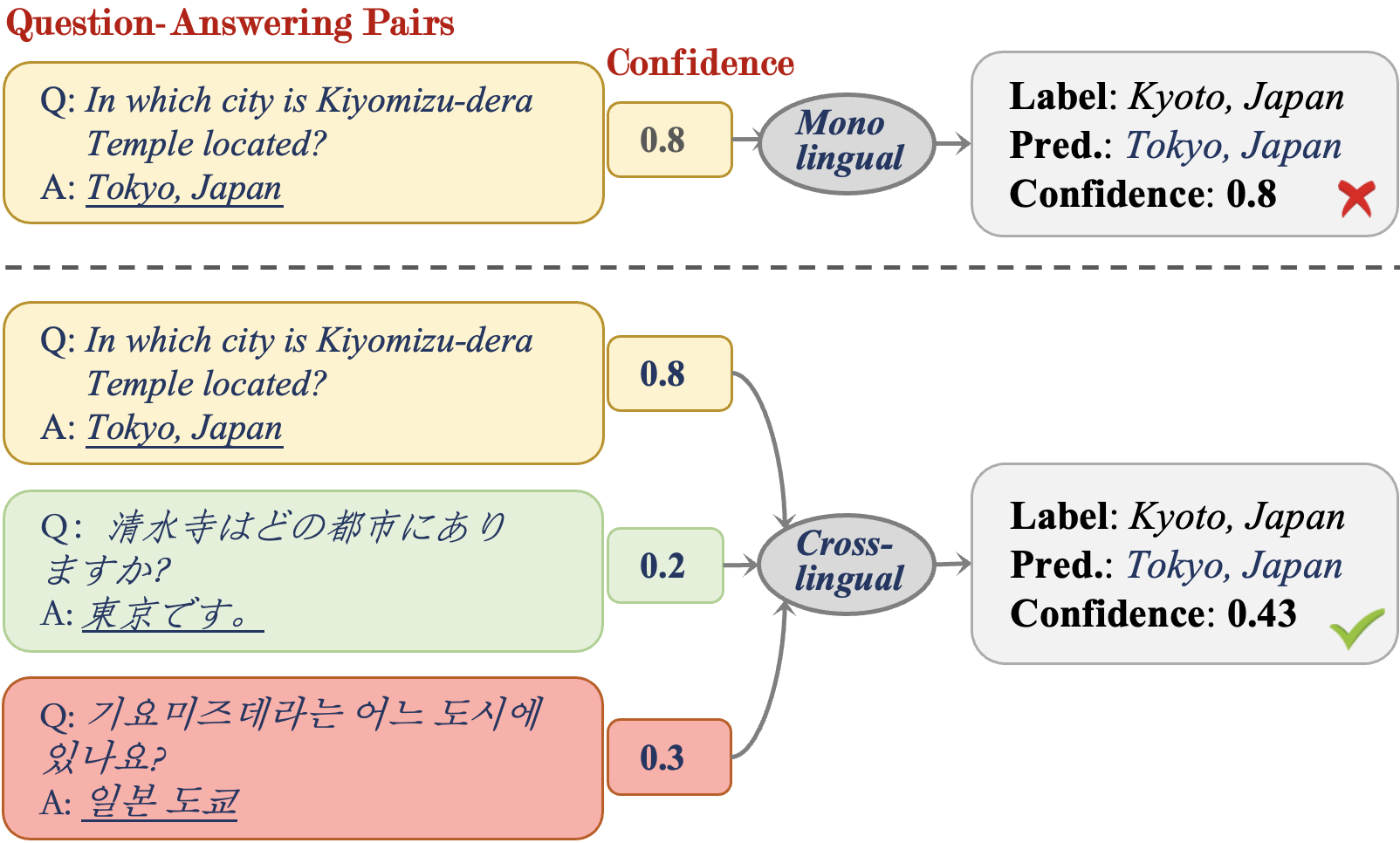
The tendency of Large Language Models (LLMs) to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of textbf Multitextbf{ling}ual textbf{Conf}idence estimation (textsc{MlingConf}) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Subsequently, we delve into the performance of several confidence estimation methods across diverse languages and examine how these confidence scores can enhance LLM performance through self-refinement. Extensive experiments conducted on the multilingual QA dataset demonstrate that confidence estimation results vary in different languages, and the verbalized numerical confidence estimation method exhibits the best performance among most languages over other methods. Finally, the obtained confidence scores can consistently improve performance as self-refinement feedback across various languages.
6/18/2024

Confidence Under the Hood: An Investigation into the Confidence-Probability Alignment in Large Language Models
Abhishek Kumar, Robert Morabito, Sanzhar Umbet, Jad Kabbara, Ali Emami
0
0
As the use of Large Language Models (LLMs) becomes more widespread, understanding their self-evaluation of confidence in generated responses becomes increasingly important as it is integral to the reliability of the output of these models. We introduce the concept of Confidence-Probability Alignment, that connects an LLM's internal confidence, quantified by token probabilities, to the confidence conveyed in the model's response when explicitly asked about its certainty. Using various datasets and prompting techniques that encourage model introspection, we probe the alignment between models' internal and expressed confidence. These techniques encompass using structured evaluation scales to rate confidence, including answer options when prompting, and eliciting the model's confidence level for outputs it does not recognize as its own. Notably, among the models analyzed, OpenAI's GPT-4 showed the strongest confidence-probability alignment, with an average Spearman's $hat{rho}$ of 0.42, across a wide range of tasks. Our work contributes to the ongoing efforts to facilitate risk assessment in the application of LLMs and to further our understanding of model trustworthiness.
6/18/2024