A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
2402.13606
0
0
Abstract
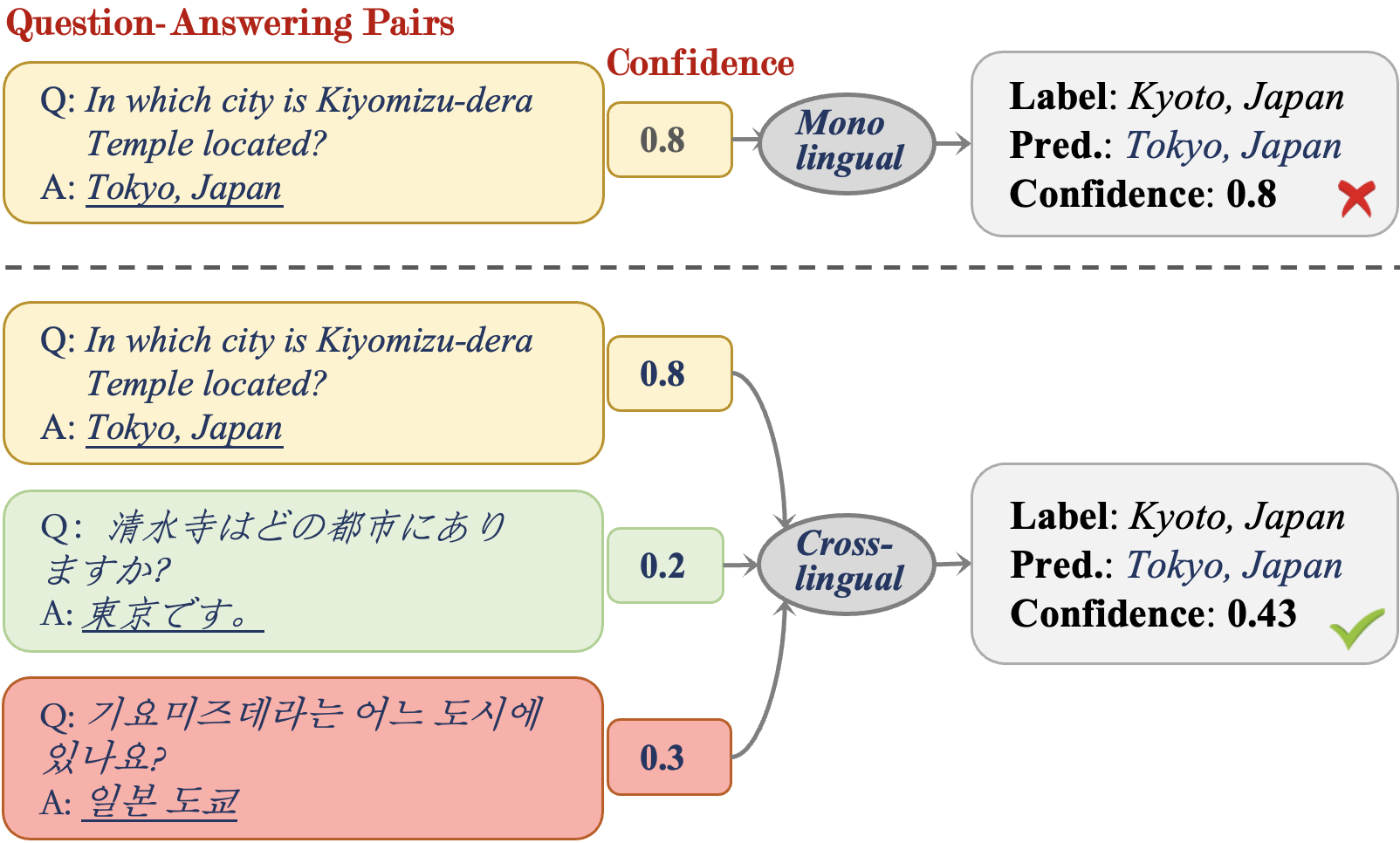
The tendency of Large Language Models (LLMs) to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of textbf Multitextbf{ling}ual textbf{Conf}idence estimation (textsc{MlingConf}) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Subsequently, we delve into the performance of several confidence estimation methods across diverse languages and examine how these confidence scores can enhance LLM performance through self-refinement. Extensive experiments conducted on the multilingual QA dataset demonstrate that confidence estimation results vary in different languages, and the verbalized numerical confidence estimation method exhibits the best performance among most languages over other methods. Finally, the obtained confidence scores can consistently improve performance as self-refinement feedback across various languages.
Create account to get full access
Overview
- This paper presents a comprehensive study of multilingual confidence estimation on large language models, titled "MlingConf".
- The research examines how well large language models can estimate their own confidence in generating text across multiple languages.
- The authors evaluate different techniques for improving confidence estimation, such as multicalibration and confidence-aware training.
- The findings provide insights into the capabilities and limitations of large language models in accurately assessing their own uncertainty.
Plain English Explanation
Large language models, such as GPT-3 and BERT, have become increasingly powerful at generating human-like text. However, these models don't always know how confident they are in the text they produce. This can be problematic, as users may rely on the model's output without realizing it may be inaccurate or uncertain.
The MlingConf study aims to address this issue by exploring ways to improve a model's ability to estimate its own confidence across multiple languages. The researchers tested different techniques, like multicalibration and confidence-aware training, to see how well they could help the models better understand their own uncertainty.
By understanding the strengths and limitations of a model's confidence estimation, researchers and developers can create more transparent and trustworthy language AI systems. This is important as these models become more widely used in real-world applications, where accurate confidence estimation is crucial for making informed decisions.
Technical Explanation
The MlingConf paper presents a comprehensive study of multilingual confidence estimation on large language models. The researchers evaluated several techniques for improving a model's ability to accurately assess its own confidence in text generation across multiple languages.
One approach they tested was multicalibration, which aims to ensure that a model's confidence scores are well-calibrated, meaning they accurately reflect the true likelihood of the model's predictions being correct. The authors also explored confidence-aware training, where the model is trained to not only generate text but also estimate its own confidence in the generated output.
Through extensive experimentation and evaluation on a diverse multilingual dataset, the researchers gained insights into the capabilities and limitations of large language models in accurately assessing their own uncertainty. The findings from this study can inform the development of more transparent and trustworthy language AI systems, as well as contribute to the broader understanding of the power and uncertainty of large language models.
Critical Analysis
The MlingConf study provides a comprehensive and valuable analysis of multilingual confidence estimation in large language models. However, the authors acknowledge several caveats and limitations to their research.
One limitation is the reliance on a specific set of language models and datasets, which may not fully capture the diversity and evolution of the field. Additionally, the study primarily focuses on confidence estimation in text generation, and it would be interesting to see how the findings extend to other language tasks, such as question answering or language understanding.
Furthermore, while the techniques explored, such as multicalibration and confidence-aware training, show promise, the authors note that there is still room for improvement in terms of the accuracy and reliability of the models' confidence estimates. Additional research may be needed to further refine and enhance these methods.
It's also important to consider the broader implications of confidence estimation in language AI systems. As these models become more widely deployed, it will be crucial to ensure that their confidence assessments are well-understood and transparently communicated to end-users, who may rely on the models' outputs for important decisions.
Conclusion
The MlingConf study provides a comprehensive and insightful examination of multilingual confidence estimation on large language models. The findings suggest that while significant progress has been made in improving a model's ability to accurately assess its own uncertainty, there are still challenges and limitations that need to be addressed.
By understanding the strengths and weaknesses of current confidence estimation techniques, researchers and developers can work towards creating more transparent and trustworthy language AI systems. This is particularly important as these models become increasingly integrated into real-world applications, where accurate confidence estimation can have significant implications for decision-making and user trust.
The insights from this study contribute to the broader understanding of the power and limitations of large language models, and help pave the way for the development of more robust and reliable language AI systems that can be deployed with confidence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Model Confidence Estimation via Black-Box Access
Tejaswini Pedapati, Amit Dhurandhar, Soumya Ghosh, Soham Dan, Prasanna Sattigeri
0
0
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
6/10/2024

Factual Confidence of LLMs: on Reliability and Robustness of Current Estimators
Mat'eo Mahaut, Laura Aina, Paula Czarnowska, Momchil Hardalov, Thomas Muller, Llu'is M`arquez
0
0
Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM's confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual confidence. We define an experimental framework allowing for fair comparison, covering both fact-verification and question answering. Our experiments across a series of LLMs indicate that trained hidden-state probes provide the most reliable confidence estimates, albeit at the expense of requiring access to weights and training data. We also conduct a deeper assessment of factual confidence by measuring the consistency of model behavior under meaning-preserving variations in the input. We find that the confidence of LLMs is often unstable across semantically equivalent inputs, suggesting that there is much room for improvement of the stability of models' parametric knowledge. Our code is available at (https://github.com/amazon-science/factual-confidence-of-llms).
6/21/2024

Multicalibration for Confidence Scoring in LLMs
Gianluca Detommaso, Martin Bertran, Riccardo Fogliato, Aaron Roth
0
0
This paper proposes the use of multicalibration to yield interpretable and reliable confidence scores for outputs generated by large language models (LLMs). Multicalibration asks for calibration not just marginally, but simultaneously across various intersecting groupings of the data. We show how to form groupings for prompt/completion pairs that are correlated with the probability of correctness via two techniques: clustering within an embedding space, and self-annotation - querying the LLM by asking it various yes-or-no questions about the prompt. We also develop novel variants of multicalibration algorithms that offer performance improvements by reducing their tendency to overfit. Through systematic benchmarking across various question answering datasets and LLMs, we show how our techniques can yield confidence scores that provide substantial improvements in fine-grained measures of both calibration and accuracy compared to existing methods.
4/9/2024
🔮
On the Calibration of Multilingual Question Answering LLMs
Yahan Yang, Soham Dan, Dan Roth, Insup Lee
0
0
Multilingual pre-trained Large Language Models (LLMs) are incredibly effective at Question Answering (QA), a core task in Natural Language Understanding, achieving high accuracies on several multilingual benchmarks. However, little is known about how well their confidences are calibrated. In this paper, we comprehensively benchmark the calibration of several multilingual LLMs (MLLMs) on a variety of QA tasks. We perform extensive experiments, spanning encoder-only, encoder-decoder, and decoder-only QA models (size varying from 110M to 7B parameters) and diverse languages, including both high- and low-resource ones. We study different dimensions of calibration in in-distribution, out-of-distribution, and cross-lingual transfer settings, and investigate strategies to improve it, including post-hoc methods and regularized fine-tuning. For decoder-only LLMs such as LlaMa2, we additionally find that in-context learning improves confidence calibration on multilingual data. We also conduct several ablation experiments to study the effect of language distances, language corpus size, and model size on calibration, and how multilingual models compare with their monolingual counterparts for diverse tasks and languages. Our experiments suggest that the multilingual QA models are poorly calibrated for languages other than English and incorporating a small set of cheaply translated multilingual samples during fine-tuning/calibration effectively enhances the calibration performance.
4/16/2024