Large Language Model Confidence Estimation via Black-Box Access
2406.04370
0
0
Abstract
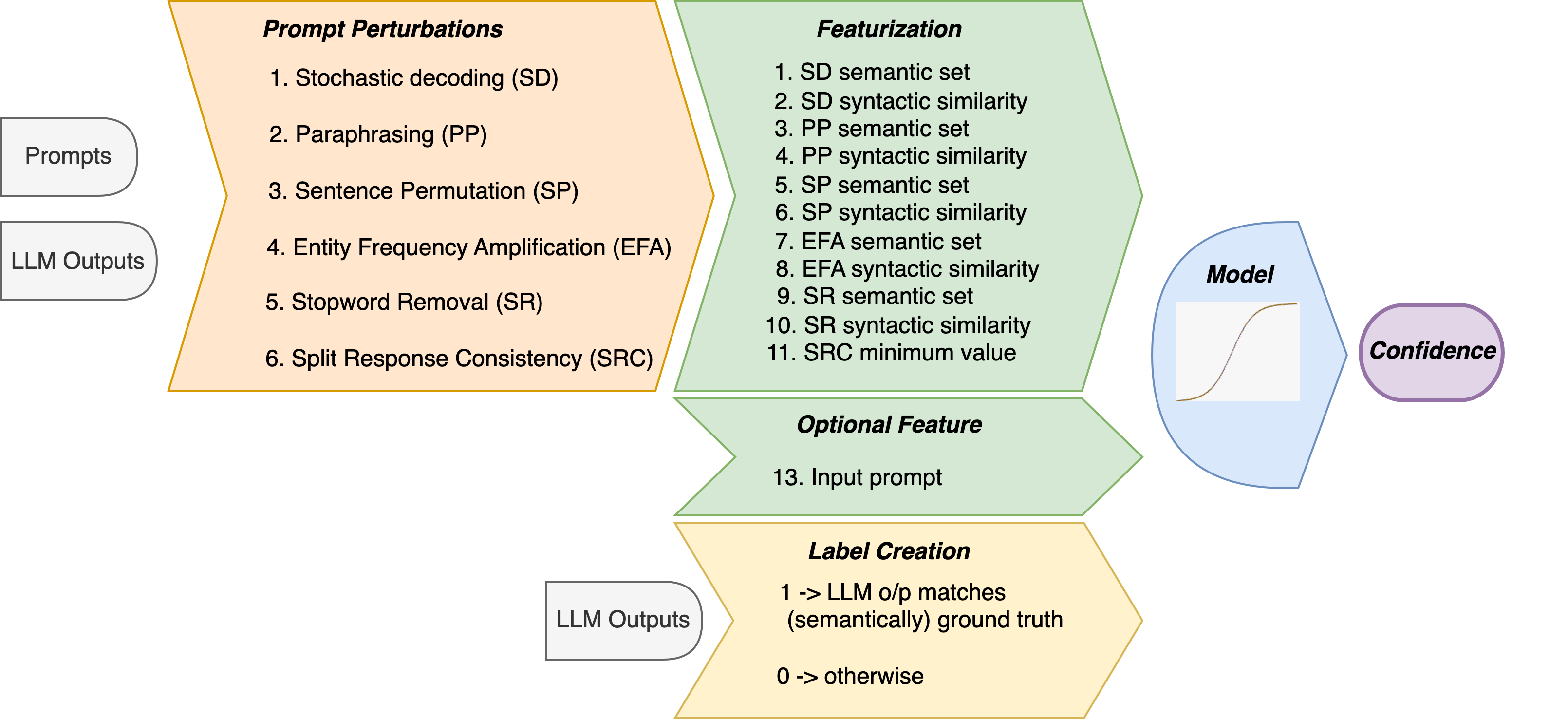
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
Create account to get full access
Overview
- This paper explores methods for estimating the confidence of large language models (LLMs) using only black-box access, without access to the model's internal parameters.
- The researchers propose several techniques to generate confidence estimates for LLM outputs, including using calibration data, adversarial examples, and assessing the stability of model outputs.
- The paper evaluates these methods on a range of language tasks and provides insights into the capabilities and limitations of black-box confidence estimation for LLMs.
Plain English Explanation
The paper focuses on a problem that's becoming increasingly important as large language models (LLMs) like GPT-3 become more widely used - how can we assess how confident the model is in its own outputs? This is important because we want to be able to trust the responses from these powerful AI systems, especially when they're being used for high-stakes applications.
The key challenge is that these LLMs are "black boxes" - we can't see the inner workings of the model, we can only observe the inputs and outputs. So the researchers in this paper explore ways to estimate the model's confidence without having access to the model's internal parameters or architecture.
They propose several different techniques, including:
- Using calibration data - data that's specifically designed to probe the model's confidence levels.
- Generating adversarial examples - inputs that are subtly perturbed to see how the model's confidence changes.
- Measuring the stability of the model's outputs - how consistent are the responses when you run the same input multiple times.
The researchers then evaluate these techniques on a variety of language tasks, like question answering and text generation, to see how well they can estimate the model's confidence. Their results provide insights into the strengths and limitations of these black-box confidence estimation methods.
Overall, this work is an important step towards being able to reliably use and trust the outputs of powerful language models, even when we can't see the inner workings of the system.
Technical Explanation
The paper proposes several techniques for estimating the confidence of large language models (LLMs) using only black-box access, without access to the model's internal parameters or architecture.
One approach is to use calibration data - a dataset specifically designed to probe the model's confidence levels. By analyzing the model's outputs on this calibration data, the researchers can learn how to map the model's raw outputs to meaningful confidence estimates.
Another method is to generate adversarial examples - inputs that are subtly perturbed to see how the model's confidence changes. The intuition is that a confident model should be relatively robust to small input perturbations, while an uncertain model will show larger fluctuations in its outputs.
The researchers also explore measuring the stability of the model's outputs - running the same input multiple times and quantifying how consistent the responses are. The idea is that a more confident model will produce more stable outputs.
These techniques are evaluated on a range of language tasks, including question answering, text generation, and sentiment analysis. The results show that the proposed black-box confidence estimation methods can provide useful signals about the model's uncertainty, even without access to its internal mechanics.
However, the paper also acknowledges limitations of these approaches. For example, the calibration data may not perfectly capture the real-world usage scenarios of the model, and the adversarial examples may not fully reflect the types of inputs the model will encounter in practice.
Critical Analysis
The paper presents a thoughtful and systematic exploration of methods for estimating the confidence of large language models using only black-box access. The proposed techniques, such as using calibration data, generating adversarial examples, and measuring output stability, provide interesting approaches to this important challenge.
One key strength of the paper is its rigorous evaluation across a diverse set of language tasks. This helps demonstrate the generalizability of the confidence estimation methods and provides valuable insights into their strengths and limitations.
However, the paper also acknowledges several caveats and areas for further research. For example, the authors note that the calibration data may not fully capture real-world usage scenarios, and the adversarial examples may not reflect the types of inputs the model will encounter in practice. Additionally, the stability-based approach may be sensitive to the specific prompts and sampling procedures used.
Further research could explore ways to make these confidence estimation techniques more robust and generalizable. For instance, work on uncertainty-aware LLMs has shown promising avenues for incorporating uncertainty estimates directly into the model architecture.
Overall, this paper makes an important contribution to the growing body of research on understanding and quantifying the confidence of large language models. While the proposed methods have some limitations, they represent a valuable step towards building more trustworthy and transparent AI systems.
Conclusion
This paper presents several techniques for estimating the confidence of large language models (LLMs) using only black-box access, without visibility into the models' internal parameters or architecture. The proposed methods, including using calibration data, generating adversarial examples, and measuring output stability, provide useful signals about the models' uncertainty levels across a range of language tasks.
The paper's rigorous evaluation and acknowledgment of limitations highlight both the promise and the challenges of black-box confidence estimation. As LLMs become more widely deployed, particularly in high-stakes applications, the ability to reliably assess model confidence will be crucial for building trust and ensuring the safe and responsible use of these powerful AI systems.
While further research is needed to address the caveats identified in this work, the findings presented here represent an important step towards a better understanding of LLM confidence and uncertainty. By continuing to explore these issues, the AI research community can help unlock the full potential of large language models while ensuring they are used in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Boyang Xue, Hongru Wang, Rui Wang, Sheng Wang, Zezhong Wang, Yiming Du, Kam-Fai Wong
0
0
The tendency of Large Language Models (LLMs) to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of textbf Multitextbf{ling}ual textbf{Conf}idence estimation (textsc{MlingConf}) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Subsequently, we delve into the performance of several confidence estimation methods across diverse languages and examine how these confidence scores can enhance LLM performance through self-refinement. Extensive experiments conducted on the multilingual QA dataset demonstrate that confidence estimation results vary in different languages, and the verbalized numerical confidence estimation method exhibits the best performance among most languages over other methods. Finally, the obtained confidence scores can consistently improve performance as self-refinement feedback across various languages.
6/18/2024
💬
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
0
0
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
5/21/2024

Confidence Under the Hood: An Investigation into the Confidence-Probability Alignment in Large Language Models
Abhishek Kumar, Robert Morabito, Sanzhar Umbet, Jad Kabbara, Ali Emami
0
0
As the use of Large Language Models (LLMs) becomes more widespread, understanding their self-evaluation of confidence in generated responses becomes increasingly important as it is integral to the reliability of the output of these models. We introduce the concept of Confidence-Probability Alignment, that connects an LLM's internal confidence, quantified by token probabilities, to the confidence conveyed in the model's response when explicitly asked about its certainty. Using various datasets and prompting techniques that encourage model introspection, we probe the alignment between models' internal and expressed confidence. These techniques encompass using structured evaluation scales to rate confidence, including answer options when prompting, and eliciting the model's confidence level for outputs it does not recognize as its own. Notably, among the models analyzed, OpenAI's GPT-4 showed the strongest confidence-probability alignment, with an average Spearman's $hat{rho}$ of 0.42, across a wide range of tasks. Our work contributes to the ongoing efforts to facilitate risk assessment in the application of LLMs and to further our understanding of model trustworthiness.
6/18/2024

Large Language Models Must Be Taught to Know What They Don't Know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, Andrew Gordon Wilson
0
0
When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
6/13/2024