Confidence Under the Hood: An Investigation into the Confidence-Probability Alignment in Large Language Models
2405.16282
0
0

Abstract
As the use of Large Language Models (LLMs) becomes more widespread, understanding their self-evaluation of confidence in generated responses becomes increasingly important as it is integral to the reliability of the output of these models. We introduce the concept of Confidence-Probability Alignment, that connects an LLM's internal confidence, quantified by token probabilities, to the confidence conveyed in the model's response when explicitly asked about its certainty. Using various datasets and prompting techniques that encourage model introspection, we probe the alignment between models' internal and expressed confidence. These techniques encompass using structured evaluation scales to rate confidence, including answer options when prompting, and eliciting the model's confidence level for outputs it does not recognize as its own. Notably, among the models analyzed, OpenAI's GPT-4 showed the strongest confidence-probability alignment, with an average Spearman's $hat{rho}$ of 0.42, across a wide range of tasks. Our work contributes to the ongoing efforts to facilitate risk assessment in the application of LLMs and to further our understanding of model trustworthiness.
Create account to get full access
Overview
- This paper investigates the alignment between the confidence expressed by large language models (LLMs) and the actual probability of their predictions being correct.
- The researchers explore whether LLMs can accurately evaluate their own confidence levels and provide reliable self-assessments.
- The study examines the calibration and reliability of confidence estimates produced by various state-of-the-art LLMs across different tasks and datasets.
Plain English Explanation
When using large language models (LLMs) like GPT-3 or BERT, it's important to understand how confident the model is in its responses. This research paper investigates the relationship between the confidence expressed by LLMs and the actual probability of their predictions being correct.
The researchers wanted to see if LLMs can accurately assess their own confidence levels and provide reliable self-assessments. They examined the calibration and reliability of the confidence estimates produced by different state-of-the-art LLMs across various tasks and datasets.
In other words, the study looked at whether the model's stated confidence in its answers matched the true likelihood of those answers being correct. This is an important consideration when using LLMs, as we need to know how much we can trust the model's own assessment of its capabilities.
Technical Explanation
The paper Confidence Under the Hood: An Investigation into the Confidence-Probability Alignment in Large Language Models explores the reliability and calibration of confidence estimates produced by large language models (LLMs).
The researchers evaluated several state-of-the-art LLMs, including GPT-3, BERT, and T5, on their ability to accurately assess the probability of their own predictions being correct. They tested the models across a variety of tasks, such as natural language inference, question answering, and text generation.
To measure the confidence-probability alignment, the researchers used metrics like Brier score and expected calibration error. These metrics quantify how well the model's stated confidence matches the actual likelihood of its predictions being correct.
The study found that while some LLMs, like GPT-3, exhibited reasonably good calibration, others struggled to accurately express their confidence levels. The researchers also identified various factors, such as task difficulty and dataset size, that influenced the confidence-probability alignment.
Critical Analysis
The paper provides valuable insights into the inner workings of large language models and their ability to reliably express confidence in their predictions. However, it's important to consider some caveats and limitations of the research.
First, the study focused on a limited set of LLMs and tasks. It would be beneficial to extend the analysis to a wider range of models and applications to better understand the generalizability of the findings. Additional research in this area could also investigate the impact of different training approaches or architectural choices on the confidence-probability alignment.
Furthermore, the paper does not delve deeply into the potential causes of the observed miscalibration in some models. Exploring the underlying mechanisms and design choices that contribute to this issue could help guide the development of more reliable and trustworthy LLMs.
Finally, the study primarily focuses on the technical aspects of confidence estimation, but it would be valuable to also consider the practical implications and ethical considerations of deploying LLMs with uncertain confidence assessments. Further research in this direction could provide insights into the real-world impact of these models and how to address potential risks or misuse.
Conclusion
This paper offers a comprehensive investigation into the confidence-probability alignment in large language models, a critical aspect of their reliability and trustworthiness. The researchers found that while some LLMs exhibit reasonable calibration, others struggle to accurately express their confidence levels, highlighting the need for further improvements in this area.
The insights gained from this study can inform the development of more reliable and transparent LLMs, which is crucial as these models become increasingly prevalent in various applications. By understanding the limitations and challenges surrounding confidence estimation, researchers and practitioners can work towards building language models that can provide users with trustworthy and well-calibrated self-assessments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
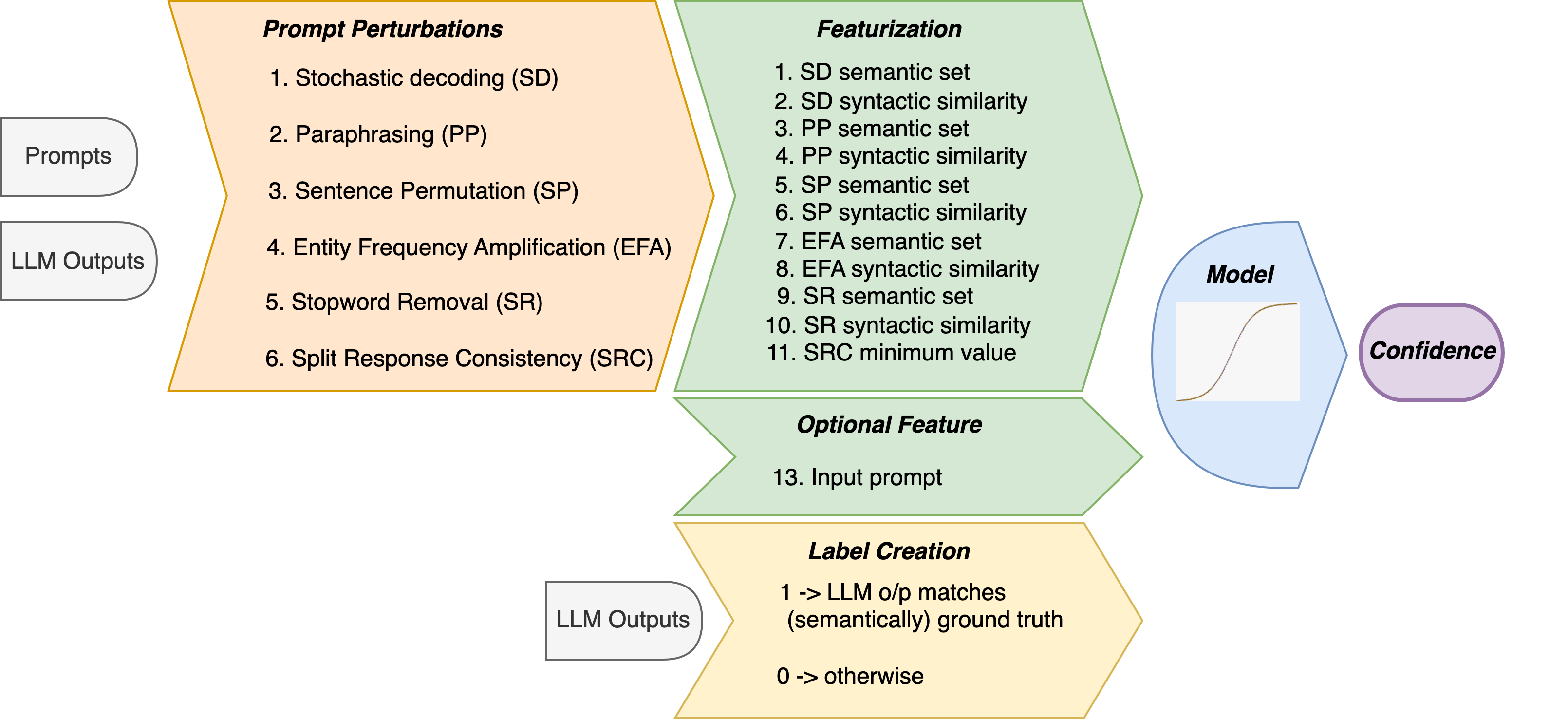
Large Language Model Confidence Estimation via Black-Box Access
Tejaswini Pedapati, Amit Dhurandhar, Soumya Ghosh, Soham Dan, Prasanna Sattigeri
0
0
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
6/10/2024
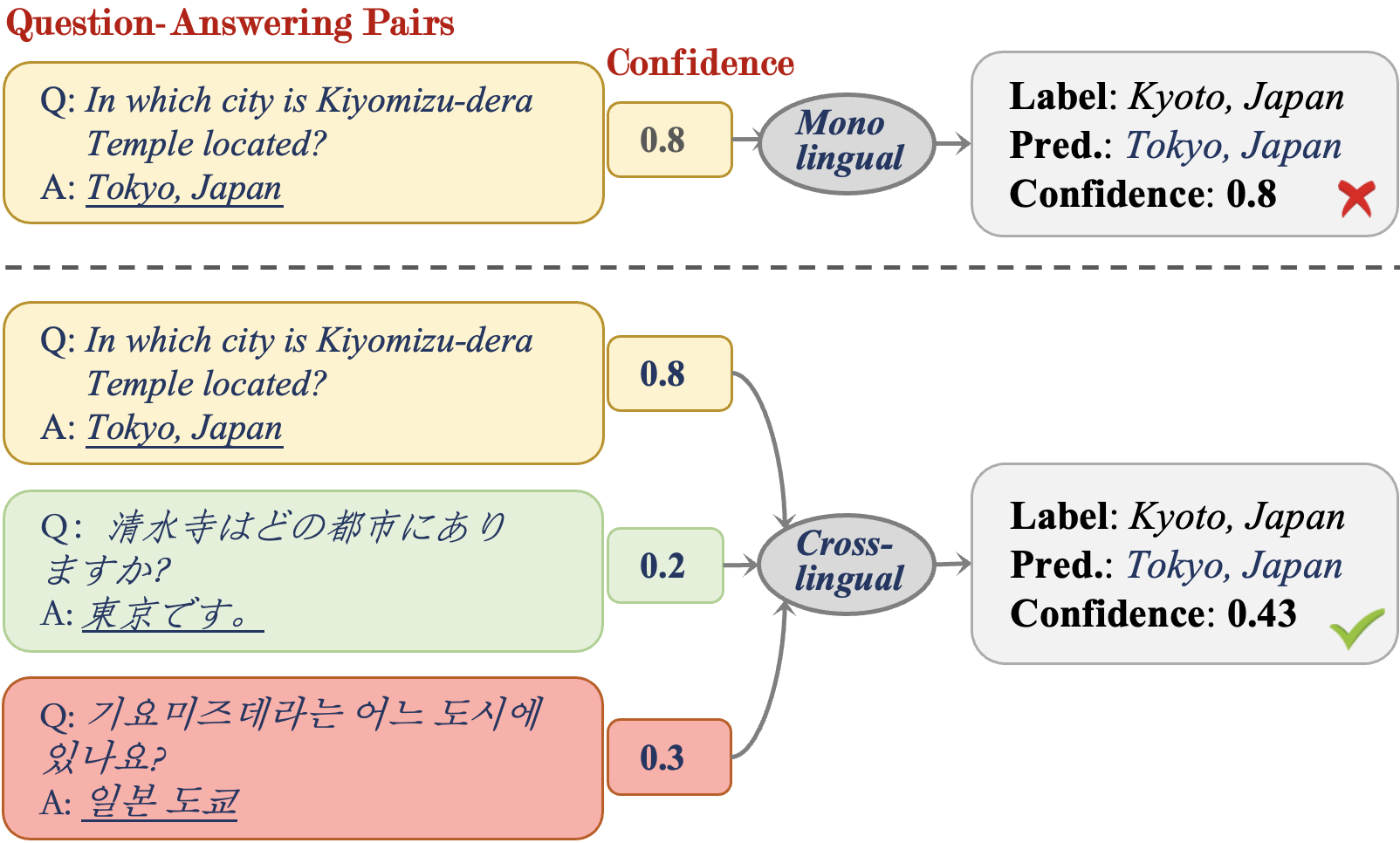
A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Boyang Xue, Hongru Wang, Rui Wang, Sheng Wang, Zezhong Wang, Yiming Du, Kam-Fai Wong
0
0
The tendency of Large Language Models (LLMs) to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of textbf Multitextbf{ling}ual textbf{Conf}idence estimation (textsc{MlingConf}) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Subsequently, we delve into the performance of several confidence estimation methods across diverse languages and examine how these confidence scores can enhance LLM performance through self-refinement. Extensive experiments conducted on the multilingual QA dataset demonstrate that confidence estimation results vary in different languages, and the verbalized numerical confidence estimation method exhibits the best performance among most languages over other methods. Finally, the obtained confidence scores can consistently improve performance as self-refinement feedback across various languages.
6/18/2024
↗️
When to Trust LLMs: Aligning Confidence with Response Quality
Shuchang Tao, Liuyi Yao, Hanxing Ding, Yuexiang Xie, Qi Cao, Fei Sun, Jinyang Gao, Huawei Shen, Bolin Ding
0
0
Despite the success of large language models (LLMs) in natural language generation, much evidence shows that LLMs may produce incorrect or nonsensical text. This limitation highlights the importance of discerning when to trust LLMs, especially in safety-critical domains. Existing methods often express reliability by confidence level, however, their effectiveness is limited by the lack of objective guidance. To address this, we propose CONfidence-Quality-ORDer-preserving alignment approach (CONQORD), which leverages reinforcement learning guided by a tailored dual-component reward function. This function integrates quality reward and order-preserving alignment reward functions. Specifically, the order-preserving reward incentivizes the model to verbalize greater confidence for responses of higher quality to align the order of confidence and quality. Experiments demonstrate that CONQORD significantly improves the alignment performance between confidence and response accuracy, without causing over-cautious. Furthermore, the aligned confidence provided by CONQORD informs when to trust LLMs, and acts as a determinant for initiating the retrieval process of external knowledge. Aligning confidence with response quality ensures more transparent and reliable responses, providing better trustworthiness.
6/11/2024
💬
Language Models can Evaluate Themselves via Probability Discrepancy
Tingyu Xia, Bowen Yu, Yuan Wu, Yi Chang, Chang Zhou
0
0
In this paper, we initiate our discussion by demonstrating how Large Language Models (LLMs), when tasked with responding to queries, display a more even probability distribution in their answers if they are more adept, as opposed to their less skilled counterparts. Expanding on this foundational insight, we propose a new self-evaluation method ProbDiff for assessing the efficacy of various LLMs. This approach obviates the necessity for an additional evaluation model or the dependence on external, proprietary models like GPT-4 for judgment. It uniquely utilizes the LLMs being tested to compute the probability discrepancy between the initial response and its revised versions. A higher discrepancy for a given query between two LLMs indicates a relatively weaker capability. Our findings reveal that ProbDiff achieves results on par with those obtained from evaluations based on GPT-4, spanning a range of scenarios that include natural language generation (NLG) tasks such as translation, summarization, and our proposed Xiaohongshu blog writing task, and benchmarks for LLM evaluation like AlignBench, MT-Bench, and AlpacaEval, across LLMs of varying magnitudes.
5/20/2024