Enhancing Continual Learning in Visual Question Answering with Modality-Aware Feature Distillation

0
Sign in to get full access
Overview
• This paper proposes a novel approach called Modality-Aware Feature Distillation (MAFD) to enhance continual learning in Visual Question Answering (VQA) tasks.
• The key idea is to leverage the complementary strengths of different modalities (e.g., vision and language) to mitigate catastrophic forgetting during sequential learning.
• The authors demonstrate the effectiveness of MAFD on several VQA benchmarks, showing improvements over existing continual learning methods.
Plain English Explanation
Visual Question Answering (VQA) is a task where a model must answer questions about images. Continual learning in VQA is challenging because as the model learns new information, it can "forget" previous knowledge, a phenomenon known as catastrophic forgetting.
The researchers in this paper developed a method called Modality-Aware Feature Distillation (MAFD) to address this problem. The core insight is that different modalities, like vision and language, can complement each other during learning. By leveraging these complementary strengths, the model can better retain its previous knowledge as it learns new tasks.
In practice, MAFD works by distilling [https://aimodels.fyi/papers/arxiv/design-as-desired-utilizing-visual-question-answering] knowledge from one modality (e.g., vision) to regularize the learning of another modality (e.g., language). This helps the model remember what it has learned without being overly constrained by the new task.
The authors show that MAFD outperforms existing continual learning methods on several VQA benchmarks. This suggests that modality-aware approaches can be a powerful tool for building AI systems that can continuously learn and adapt without forgetting.
Technical Explanation
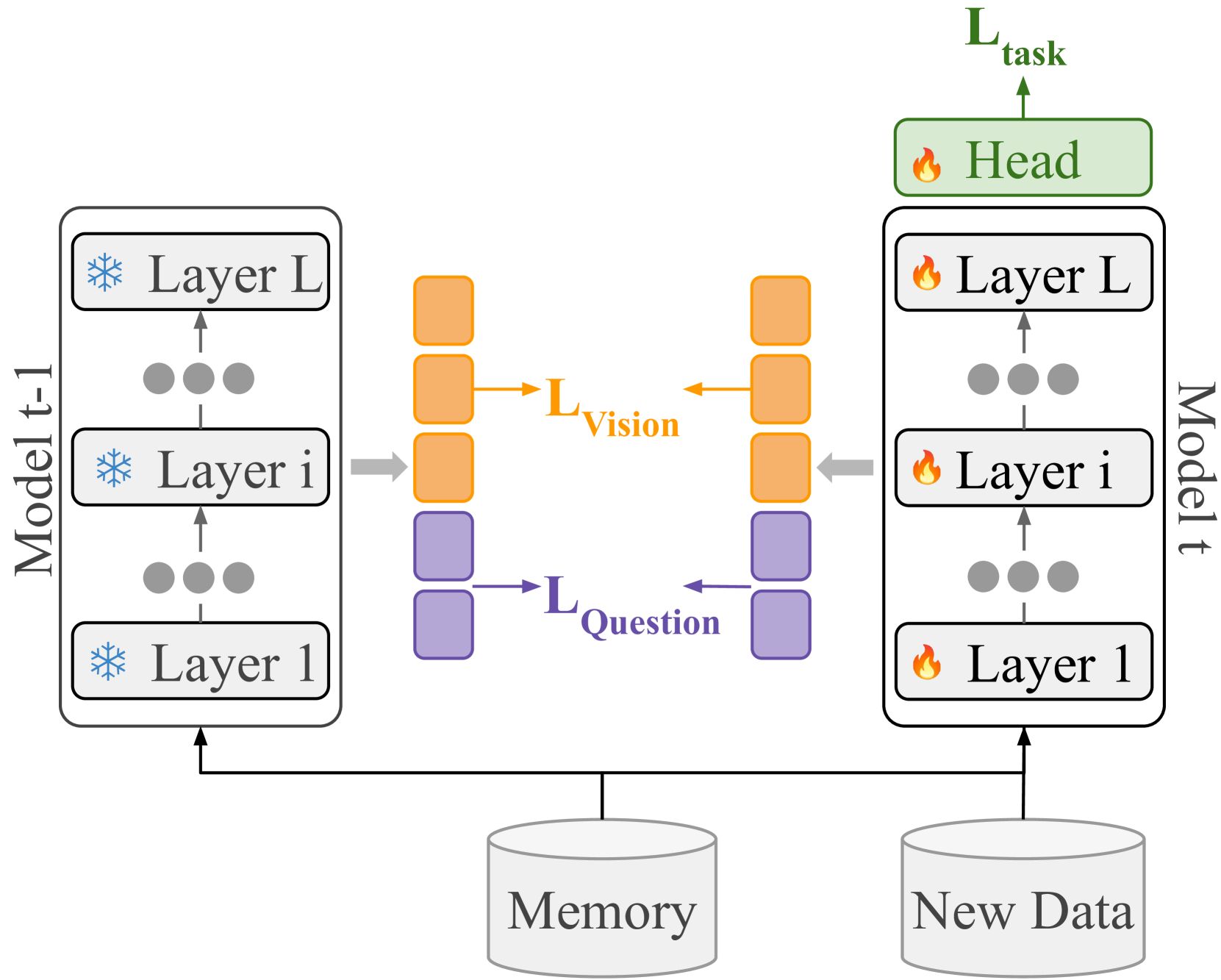
The authors propose a Modality-Aware Feature Distillation (MAFD) framework to enhance continual learning in Visual Question Answering (VQA) tasks. The key insight is to leverage the complementary strengths of different modalities, such as vision and language, to mitigate catastrophic forgetting.
MAFD works by distilling [https://aimodels.fyi/papers/arxiv/precision-empowers-excess-distracts-visual-question-answering] knowledge from one modality to regularize the learning of another modality. Specifically, the model maintains separate feature extractors for each modality and uses knowledge distillation [https://aimodels.fyi/papers/arxiv/miss-generative-pretraining-finetuning-approach-med-vqa] to transfer salient information from the previous modality to the current one.
This modality-aware distillation helps the model retain its previous knowledge while learning new tasks, preventing catastrophic forgetting. The authors evaluate MAFD on several VQA benchmarks, including [https://aimodels.fyi/papers/arxiv/lova3-learning-to-visual-question-answering-asking] and [https://aimodels.fyi/papers/arxiv/optimizing-visual-question-answering-models-driving-bridging], and demonstrate its superiority over existing continual learning methods.
Critical Analysis
The authors provide a thorough evaluation of MAFD, including comparisons to state-of-the-art continual learning approaches on multiple VQA datasets. However, the paper does not discuss the potential limitations of the proposed method.
For example, the performance of MAFD may depend on the specific characteristics of the VQA tasks, such as the complexity of the visual and linguistic information, the degree of task relatedness, and the availability of annotated data. Further research is needed to understand the generalizability of MAFD to a wider range of continual learning scenarios.
Additionally, the paper does not explore the computational and memory overhead introduced by the separate feature extractors and the distillation process. In practical applications, these factors may be crucial, and the authors could have provided more insights into the trade-offs between performance and efficiency.
Conclusion
This paper introduces Modality-Aware Feature Distillation (MAFD), a novel approach to enhance continual learning in Visual Question Answering (VQA) tasks. By leveraging the complementary strengths of different modalities, MAFD effectively mitigates catastrophic forgetting and outperforms existing continual learning methods on several benchmarks.
The key innovation of MAFD is the idea of using modality-aware distillation to transfer salient knowledge between feature extractors, which helps the model retain its previous capabilities while learning new tasks. This work highlights the potential of modality-aware techniques for building AI systems that can continuously learn and adapt without forgetting.
While the paper provides a strong technical contribution, further research is needed to understand the limitations and broader applicability of MAFD. Nonetheless, this work represents an important step forward in the field of continual learning for multimodal AI tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Continual Learning in Visual Question Answering with Modality-Aware Feature Distillation
Malvina Nikandrou, Georgios Pantazopoulos, Ioannis Konstas, Alessandro Suglia
Continual learning focuses on incrementally training a model on a sequence of tasks with the aim of learning new tasks while minimizing performance drop on previous tasks. Existing approaches at the intersection of Continual Learning and Visual Question Answering (VQA) do not study how the multimodal nature of the input affects the learning dynamics of a model. In this paper, we demonstrate that each modality evolves at different rates across a continuum of tasks and that this behavior occurs in established encoder-only models as well as modern recipes for developing Vision & Language (VL) models. Motivated by this observation, we propose a modality-aware feature distillation (MAFED) approach which outperforms existing baselines across models of varying scale in three multimodal continual learning settings. Furthermore, we provide ablations showcasing that modality-aware distillation complements experience replay. Overall, our results emphasize the importance of addressing modality-specific dynamics to prevent forgetting in multimodal continual learning.
Read more6/28/2024
0
Design as Desired: Utilizing Visual Question Answering for Multimodal Pre-training
Tongkun Su, Jun Li, Xi Zhang, Haibo Jin, Hao Chen, Qiong Wang, Faqin Lv, Baoliang Zhao, Yin Hu
Multimodal pre-training demonstrates its potential in the medical domain, which learns medical visual representations from paired medical reports. However, many pre-training tasks require extra annotations from clinicians, and most of them fail to explicitly guide the model to learn the desired features of different pathologies. To the best of our knowledge, we are the first to utilize Visual Question Answering (VQA) for multimodal pre-training to guide the framework focusing on targeted pathological features. In this work, we leverage descriptions in medical reports to design multi-granular question-answer pairs associated with different diseases, which assist the framework in pre-training without requiring extra annotations from experts. We also propose a novel pre-training framework with a quasi-textual feature transformer, a module designed to transform visual features into a quasi-textual space closer to the textual domain via a contrastive learning strategy. This narrows the vision-language gap and facilitates modality alignment. Our framework is applied to four downstream tasks: report generation, classification, segmentation, and detection across five datasets. Extensive experiments demonstrate the superiority of our framework compared to other state-of-the-art methods. Our code will be released upon acceptance.
Read more4/9/2024
🏋️
0
Enhancing Visual Question Answering through Ranking-Based Hybrid Training and Multimodal Fusion
Peiyuan Chen, Zecheng Zhang, Yiping Dong, Li Zhou, Han Wang
Visual Question Answering (VQA) is a challenging task that requires systems to provide accurate answers to questions based on image content. Current VQA models struggle with complex questions due to limitations in capturing and integrating multimodal information effectively. To address these challenges, we propose the Rank VQA model, which leverages a ranking-inspired hybrid training strategy to enhance VQA performance. The Rank VQA model integrates high-quality visual features extracted using the Faster R-CNN model and rich semantic text features obtained from a pre-trained BERT model. These features are fused through a sophisticated multimodal fusion technique employing multi-head self-attention mechanisms. Additionally, a ranking learning module is incorporated to optimize the relative ranking of answers, thus improving answer accuracy. The hybrid training strategy combines classification and ranking losses, enhancing the model's generalization ability and robustness across diverse datasets. Experimental results demonstrate the effectiveness of the Rank VQA model. Our model significantly outperforms existing state-of-the-art models on standard VQA datasets, including VQA v2.0 and COCO-QA, in terms of both accuracy and Mean Reciprocal Rank (MRR). The superior performance of Rank VQA is evident in its ability to handle complex questions that require understanding nuanced details and making sophisticated inferences from the image and text. This work highlights the effectiveness of a ranking-based hybrid training strategy in improving VQA performance and lays the groundwork for further research in multimodal learning methods.
Read more8/15/2024

0
Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
Read more6/17/2024