Design as Desired: Utilizing Visual Question Answering for Multimodal Pre-training
2404.00226
0
0
Abstract
Multimodal pre-training demonstrates its potential in the medical domain, which learns medical visual representations from paired medical reports. However, many pre-training tasks require extra annotations from clinicians, and most of them fail to explicitly guide the model to learn the desired features of different pathologies. To the best of our knowledge, we are the first to utilize Visual Question Answering (VQA) for multimodal pre-training to guide the framework focusing on targeted pathological features. In this work, we leverage descriptions in medical reports to design multi-granular question-answer pairs associated with different diseases, which assist the framework in pre-training without requiring extra annotations from experts. We also propose a novel pre-training framework with a quasi-textual feature transformer, a module designed to transform visual features into a quasi-textual space closer to the textual domain via a contrastive learning strategy. This narrows the vision-language gap and facilitates modality alignment. Our framework is applied to four downstream tasks: report generation, classification, segmentation, and detection across five datasets. Extensive experiments demonstrate the superiority of our framework compared to other state-of-the-art methods. Our code will be released upon acceptance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of visual question answering (VQA) for multimodal pre-training, a technique that aims to improve the performance of language models by leveraging both visual and textual information.
- The researchers propose a framework called "Design as Desired" (DaD), which utilizes VQA tasks to pre-train a multimodal model that can then be fine-tuned for various downstream tasks.
- The paper presents experiments and insights regarding the effectiveness of this approach, as well as its potential benefits and limitations.
Plain English Explanation
The researchers in this paper are interested in finding ways to make language models, which are AI systems that can understand and generate human language, even more powerful. One way they think they can do this is by also showing the language model images and asking it questions about those images.
Link to MChartQA: A Universal Benchmark for Multimodal Chart Question Answering The idea is that by training the language model to not just understand text, but also to understand and answer questions about images, it can learn more about the world and become better at language understanding overall.
The researchers call this approach "Design as Desired" (DaD), and they test it out by having the language model try to answer questions about all sorts of different images. Link to TinyVQA: A Compact Multimodal Deep Neural Network for Visual Question Answering They find that this pre-training method can indeed help the language model perform better on a variety of tasks, though there are also some limitations and areas for further research.
Technical Explanation
The key idea behind the "Design as Desired" (DaD) framework is to utilize visual question answering (VQA) tasks for multimodal pre-training. VQA involves presenting an image to a model and asking it questions about the contents of that image. Link to Multi-Stage Multi-Modal Pre-Training for Automatic Video Description The researchers hypothesize that by training a model to perform well on VQA tasks, it can learn useful multimodal representations that can then be leveraged for other downstream tasks.
The DaD framework consists of three main components:
- A multimodal encoder that takes in both visual and textual inputs
- A VQA head that predicts answers to questions about the input images
- A task-specific head for the downstream task of interest
During pre-training, the model is trained on a large dataset of image-question-answer triplets to optimize the VQA performance. Link to Bridging Language, Vision, and Action: Multimodal VaEs for Robotic Manipulation The resulting multimodal representations can then be fine-tuned for various downstream tasks, such as image captioning or visual reasoning.
The researchers conduct experiments to evaluate the effectiveness of this approach, comparing the DaD framework to other multimodal pre-training strategies. They find that DaD can indeed lead to improved performance on a range of tasks, suggesting that the VQA-based pre-training is a valuable tool for enhancing the capabilities of multimodal models.
Critical Analysis
The paper provides a thorough exploration of the DaD framework and presents compelling evidence for its benefits. However, the researchers also acknowledge some limitations and areas for further research.
One key limitation is that the DaD approach relies on the availability of large-scale VQA datasets, which can be challenging to obtain and may not cover all the necessary visual and linguistic diversity. Link to Quantifying and Mitigating Unimodal Biases in Multimodal Language Models Additionally, the paper does not delve deeply into potential biases that may be introduced by the VQA tasks or the impact of such biases on downstream applications.
Another area for further research is the generalizability of the DaD approach. While the experiments demonstrate improvements on several tasks, it would be valuable to explore the performance of DaD-trained models on a wider range of applications, especially those that may require more complex multimodal reasoning or integration.
Overall, the paper presents a promising approach to multimodal pre-training and highlights the potential benefits of leveraging VQA tasks. The critical analysis suggests that while the DaD framework shows strong results, there are still opportunities to refine and expand upon this line of research.
Conclusion
The "Design as Desired" (DaD) framework proposed in this paper represents a novel approach to multimodal pre-training, leveraging visual question answering (VQA) tasks to enhance the capabilities of language models. The researchers demonstrate that this VQA-based pre-training can lead to improved performance on a range of downstream tasks, suggesting that it is a valuable tool for advancing the state of the art in multimodal AI.
While the paper identifies some limitations and areas for further research, the overall findings are encouraging and highlight the potential of multimodal pre-training to unlock new possibilities in language understanding, visual reasoning, and other related domains. As the field of AI continues to evolve, techniques like DaD will likely play an increasingly important role in developing more capable and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
Cuong Nhat Ha, Shima Asaadi, Sanjeev Kumar Karn, Oladimeji Farri, Tobias Heimann, Thomas Runkler
0
0
Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
4/26/2024
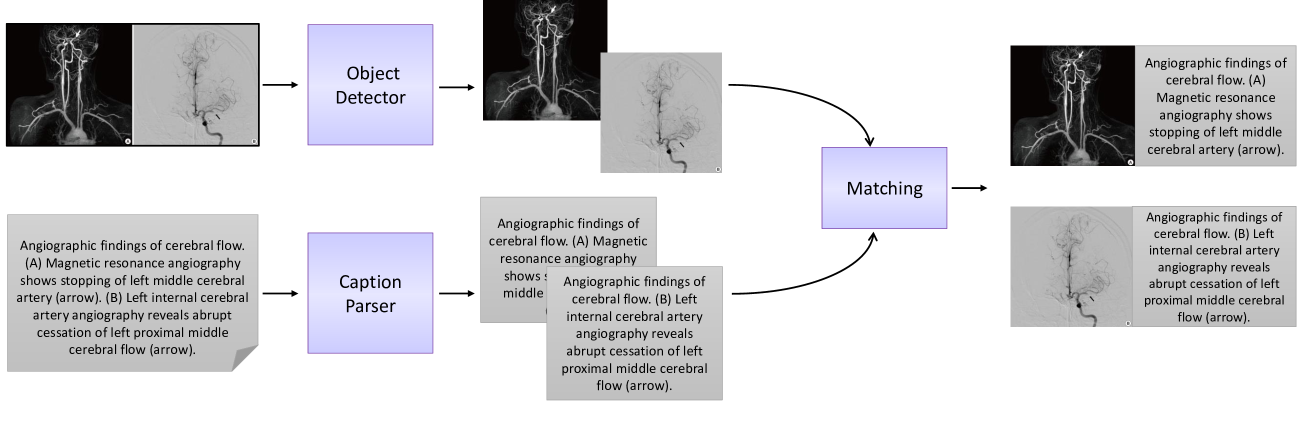
Medical Vision-Language Pre-Training for Brain Abnormalities
Masoud Monajatipoor, Zi-Yi Dou, Aichi Chien, Nanyun Peng, Kai-Wei Chang
0
0
Vision-language models have become increasingly powerful for tasks that require an understanding of both visual and linguistic elements, bridging the gap between these modalities. In the context of multimodal clinical AI, there is a growing need for models that possess domain-specific knowledge, as existing models often lack the expertise required for medical applications. In this paper, we take brain abnormalities as an example to demonstrate how to automatically collect medical image-text aligned data for pretraining from public resources such as PubMed. In particular, we present a pipeline that streamlines the pre-training process by initially collecting a large brain image-text dataset from case reports and published journals and subsequently constructing a high-performance vision-language model tailored to specific medical tasks. We also investigate the unique challenge of mapping subfigures to subcaptions in the medical domain. We evaluated the resulting model with quantitative and qualitative intrinsic evaluations. The resulting dataset and our code can be found here https://github.com/masoud-monajati/MedVL_pretraining_pipeline
4/30/2024
💬
MedThink: Explaining Medical Visual Question Answering via Multimodal Decision-Making Rationale
Xiaotang Gai, Chenyi Zhou, Jiaxiang Liu, Yang Feng, Jian Wu, Zuozhu Liu
0
0
Medical Visual Question Answering (MedVQA), which offers language responses to image-based medical inquiries, represents a challenging task and significant advancement in healthcare. It assists medical experts to swiftly interpret medical images, thereby enabling faster and more accurate diagnoses. However, the model interpretability and transparency of existing MedVQA solutions are often limited, posing challenges in understanding their decision-making processes. To address this issue, we devise a semi-automated annotation process to streamlining data preparation and build new benchmark MedVQA datasets R-RAD and R-SLAKE. The R-RAD and R-SLAKE datasets provide intermediate medical decision-making rationales generated by multimodal large language models and human annotations for question-answering pairs in existing MedVQA datasets, i.e., VQA-RAD and SLAKE. Moreover, we design a novel framework which finetunes lightweight pretrained generative models by incorporating medical decision-making rationales into the training process. The framework includes three distinct strategies to generate decision outcomes and corresponding rationales, thereby clearly showcasing the medical decision-making process during reasoning. Extensive experiments demonstrate that our method can achieve an accuracy of 83.5% on R-RAD and 86.3% on R-SLAKE, significantly outperforming existing state-of-the-art baselines. Dataset and code will be released.
4/19/2024
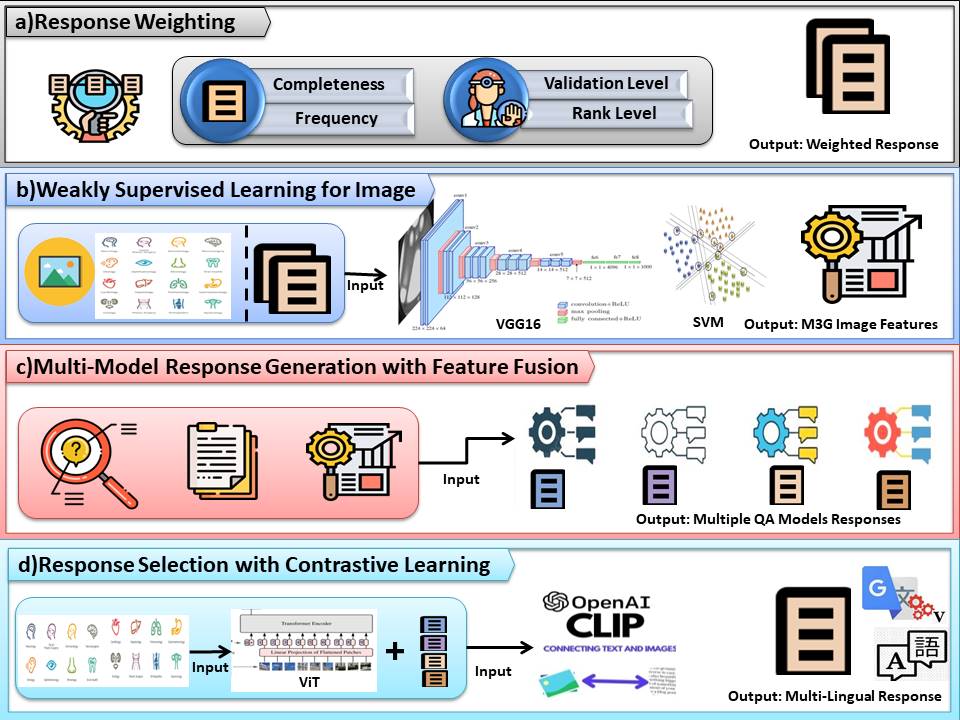
MediFact at MEDIQA-M3G 2024: Medical Question Answering in Dermatology with Multimodal Learning
Nadia Saeed
0
0
The MEDIQA-M3G 2024 challenge necessitates novel solutions for Multilingual & Multimodal Medical Answer Generation in dermatology (wai Yim et al., 2024a). This paper addresses the limitations of traditional methods by proposing a weakly supervised learning approach for open-ended medical question-answering (QA). Our system leverages readily available MEDIQA-M3G images via a VGG16-CNN-SVM model, enabling multilingual (English, Chinese, Spanish) learning of informative skin condition representations. Using pre-trained QA models, we further bridge the gap between visual and textual information through multimodal fusion. This approach tackles complex, open-ended questions even without predefined answer choices. We empower the generation of comprehensive answers by feeding the ViT-CLIP model with multiple responses alongside images. This work advances medical QA research, paving the way for clinical decision support systems and ultimately improving healthcare delivery.
5/6/2024