Enhancing Few-Shot Transfer Learning with Optimized Multi-Task Prompt Tuning through Modular Prompt Composition

0

Sign in to get full access
Overview
- This paper presents a method called "Modular Prompt Composition" (MPC) that enhances few-shot transfer learning by optimizing multi-task prompt tuning.
- The key ideas are to use modular prompts that can be composed flexibly, and to optimize the prompts through meta-learning across multiple tasks.
- The proposed approach aims to improve the performance of language models on new tasks with limited training data.
Plain English Explanation
The paper introduces a technique called "Modular Prompt Composition" (MPC) that can help language models perform better on new tasks when only a small amount of training data is available.
The core idea is to break down the prompts used to guide the language model into smaller, reusable components. These modular prompts can then be combined in different ways to adapt the model to new tasks. The researchers also develop a way to optimize the modular prompts by having the model practice on multiple tasks during training.
This flexibility and optimization allows the language model to more effectively transfer its knowledge from previous tasks to new ones, even when only a few examples of the new task are available. By using modular, optimized prompts, the model can quickly adapt its behavior to perform well on the new task.
The researchers demonstrate the benefits of their MPC approach through experiments on various language understanding and generation tasks. The results show that MPC can outperform other prompt-based and few-shot learning methods, highlighting its potential to enhance the capabilities of language models in low-resource settings.
Technical Explanation
The paper introduces a novel approach called "Modular Prompt Composition" (MPC) to enhance few-shot transfer learning for language models. The key ideas are:
-
Modular Prompts: The authors propose breaking down the input prompts used to guide the language model into smaller, reusable components. These modular prompts can then be flexibly combined to adapt the model to new tasks.
-
Multi-Task Prompt Optimization: The researchers develop a meta-learning approach to optimize the modular prompts across multiple tasks during training. This allows the model to learn prompt compositions that are effective for transferring knowledge to new tasks.
The MPC framework consists of three main components:
- Prompt Encoder: This module encodes the modular prompts into vector representations that can be efficiently combined.
- Prompt Composer: This component learns to compose the modular prompt representations in an optimal way for each task.
- Task Predictor: This is the language model itself, which takes the composed prompt and generates the desired output.
During training, the entire MPC framework is optimized end-to-end using a meta-learning objective. This allows the model to learn prompt compositions that enable effective few-shot transfer to new tasks.
The researchers evaluate MPC on a range of language understanding and generation tasks, including text classification, question answering, and dialogue generation. The results demonstrate that MPC outperforms other prompt-based and few-shot learning methods, showcasing its ability to enhance the performance of language models in low-resource settings.
Critical Analysis
The paper presents a compelling approach to improving the few-shot transfer capabilities of language models through the use of modular, optimized prompts. Some key strengths of the research include:
- Flexibility and Compositionality: The modular prompt design allows for greater flexibility in adapting the model to new tasks, as the individual prompt components can be combined in different ways.
- Optimization through Meta-Learning: The multi-task prompt optimization technique enables the model to learn prompt compositions that are effective for transfer learning, going beyond manual prompt engineering.
- Empirical Validation: The experiments demonstrate the benefits of MPC across a diverse set of language tasks, providing strong evidence for the practical utility of the approach.
However, the paper also acknowledges some limitations and areas for future work:
- Computational Complexity: The meta-learning process used to optimize the modular prompts can be computationally intensive, which may limit the scalability of the approach.
- Interpretability: The paper does not provide much insight into the internal workings of the modular prompts and how they enable effective transfer. Improved interpretability could lead to a better understanding of the mechanisms behind the approach.
- Generalization to Broader Domains: The experiments focus on language understanding and generation tasks, but it would be valuable to explore the application of MPC to other domains, such as vision or multimodal tasks.
Overall, the Modular Prompt Composition method presented in this paper represents a promising direction for enhancing the few-shot transfer capabilities of language models. Further research into improving the efficiency and interpretability of the approach could help unlock its full potential.
Conclusion
This paper introduces a novel technique called "Modular Prompt Composition" (MPC) that enhances the few-shot transfer learning abilities of language models. By breaking down prompts into modular components and optimizing their composition through meta-learning, MPC enables language models to more effectively adapt to new tasks with limited training data.
The key contributions of the research include the modular prompt design, the multi-task prompt optimization approach, and the empirical validation of the MPC framework across a range of language tasks. While the method has some computational and interpretability limitations, it represents an important step forward in improving the versatility and performance of language models in low-resource settings.
As language models continue to play an increasingly central role in various AI applications, techniques like MPC that can boost their few-shot transfer capabilities will become increasingly valuable. Further advancements in this direction could have significant implications for the field of natural language processing and the broader landscape of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Few-Shot Transfer Learning with Optimized Multi-Task Prompt Tuning through Modular Prompt Composition
Ahmad Pouramini, Hesham Faili
In recent years, multi-task prompt tuning has garnered considerable attention for its inherent modularity and potential to enhance parameter-efficient transfer learning across diverse tasks. This paper aims to analyze and improve the performance of multiple tasks by facilitating the transfer of knowledge between their corresponding prompts in a multi-task setting. Our proposed approach decomposes the prompt for each target task into a combination of shared prompts (source prompts) and a task-specific prompt (private prompt). During training, the source prompts undergo fine-tuning and are integrated with the private prompt to drive the target prompt for each task. We present and compare multiple methods for combining source prompts to construct the target prompt, analyzing the roles of both source and private prompts within each method. We investigate their contributions to task performance and offer flexible, adjustable configurations based on these insights to optimize performance. Our empirical findings clearly showcase improvements in accuracy and robustness compared to the conventional practice of prompt tuning and related works. Notably, our results substantially outperform other methods in the field in few-shot settings, demonstrating superior performance in various tasks across GLUE benchmark, among other tasks. This achievement is attained with a significantly reduced amount of training data, making our method a promising one for few-shot settings.
Read more8/26/2024

0
Efficient Multi-task Prompt Tuning for Recommendation
Ting Bai, Le Huang, Yue Yu, Cheng Yang, Cheng Hou, Zhe Zhao, Chuan Shi
With the expansion of business scenarios, real recommender systems are facing challenges in dealing with the constantly emerging new tasks in multi-task learning frameworks. In this paper, we attempt to improve the generalization ability of multi-task recommendations when dealing with new tasks. We find that joint training will enhance the performance of the new task but always negatively impact existing tasks in most multi-task learning methods. Besides, such a re-training mechanism with new tasks increases the training costs, limiting the generalization ability of multi-task recommendation models. Based on this consideration, we aim to design a suitable sharing mechanism among different tasks while maintaining joint optimization efficiency in new task learning. A novel two-stage prompt-tuning MTL framework (MPT-Rec) is proposed to address task irrelevance and training efficiency problems in multi-task recommender systems. Specifically, we disentangle the task-specific and task-sharing information in the multi-task pre-training stage, then use task-aware prompts to transfer knowledge from other tasks to the new task effectively. By freezing parameters in the pre-training tasks, MPT-Rec solves the negative impacts that may be brought by the new task and greatly reduces the training costs. Extensive experiments on three real-world datasets show the effectiveness of our proposed multi-task learning framework. MPT-Rec achieves the best performance compared to the SOTA multi-task learning method. Besides, it maintains comparable model performance but vastly improves the training efficiency (i.e., with up to 10% parameters in the full training way) in the new task learning.
Read more9/2/2024

0
Zero-Shot Continuous Prompt Transfer: Generalizing Task Semantics Across Language Models
Zijun Wu, Yongkang Wu, Lili Mou
Prompt tuning in natural language processing (NLP) has become an increasingly popular method for adapting large language models to specific tasks. However, the transferability of these prompts, especially continuous prompts, between different models remains a challenge. In this work, we propose a zero-shot continuous prompt transfer method, where source prompts are encoded into relative space and the corresponding target prompts are searched for transferring to target models. Experimental results confirm the effectiveness of our method, showing that 'task semantics' in continuous prompts can be generalized across various language models. Moreover, we find that combining 'task semantics' from multiple source models can further enhance the generalizability of transfer.
Read more7/15/2024
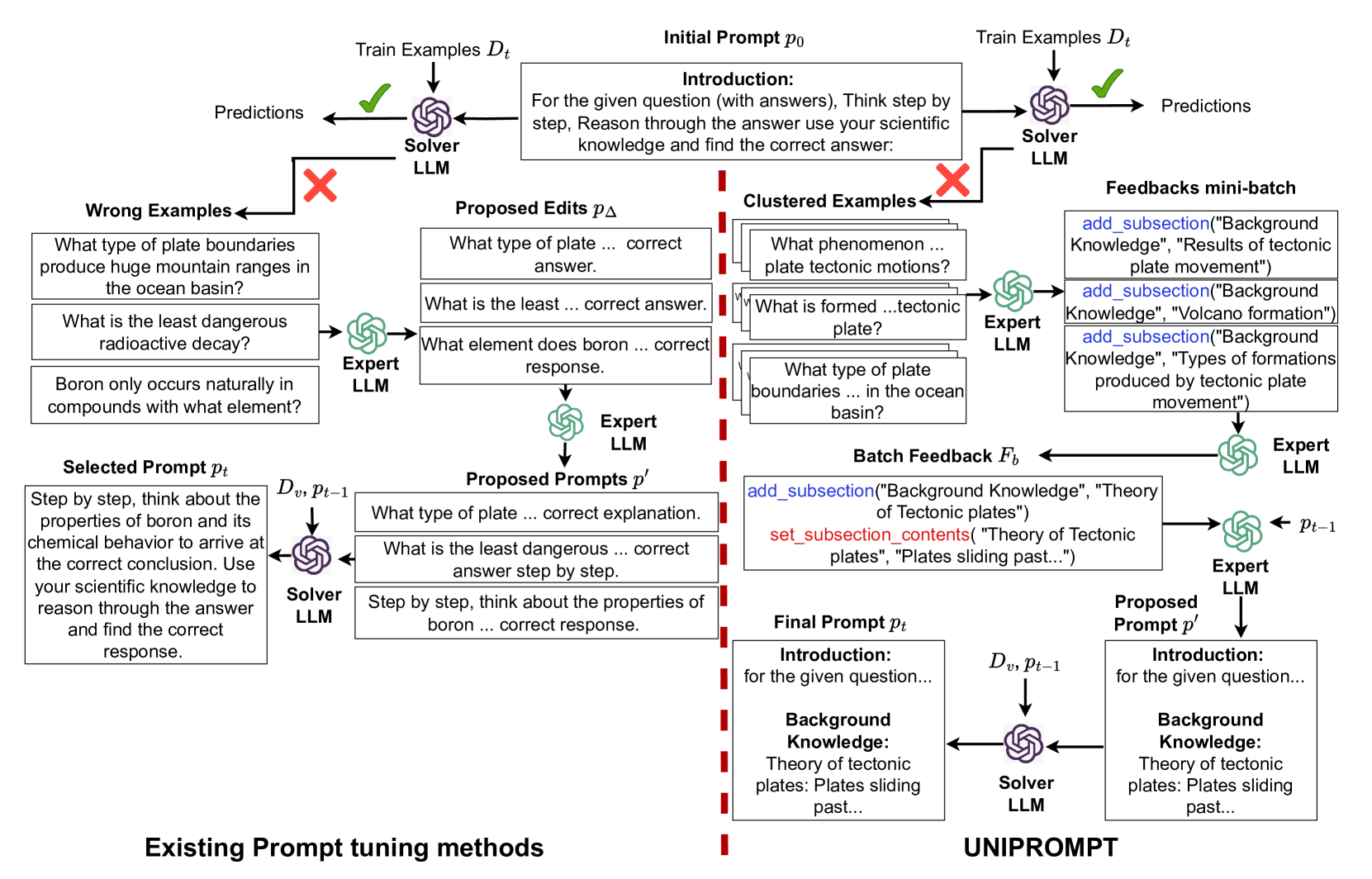
0
Task Facet Learning: A Structured Approach to Prompt Optimization
Gurusha Juneja, Nagarajan Natarajan, Hua Li, Jian Jiao, Amit Sharma
Given a task in the form of a basic description and its training examples, prompt optimization is the problem of synthesizing the given information into a text prompt for a large language model (LLM). Humans solve this problem by also considering the different facets that define a task (e.g., counter-examples, explanations, analogies) and including them in the prompt. However, it is unclear whether existing algorithmic approaches, based on iteratively editing a given prompt or automatically selecting a few in-context examples, can cover the multiple facets required to solve a complex task. In this work, we view prompt optimization as that of learning multiple facets of a task from a set of training examples. We identify and exploit structure in the prompt optimization problem -- first, we find that prompts can be broken down into loosely coupled semantic sections that have a relatively independent effect on the prompt's performance; second, we cluster the input space and use clustered batches so that the optimization procedure can learn the different facets of a task across batches. The resulting algorithm, UniPrompt, consists of a generative model to generate initial candidates for each prompt section; and a feedback mechanism that aggregates suggested edits from multiple mini-batches into a conceptual description for the section. Empirical evaluation on multiple datasets and a real-world task shows that prompts generated using UniPrompt obtain higher accuracy than human-tuned prompts and those from state-of-the-art methods. In particular, our algorithm can generate long, complex prompts that existing methods are unable to generate. Code for UniPrompt will be available at url{https://aka.ms/uniprompt}.
Read more6/18/2024