Task Facet Learning: A Structured Approach to Prompt Optimization
2406.10504
0
0
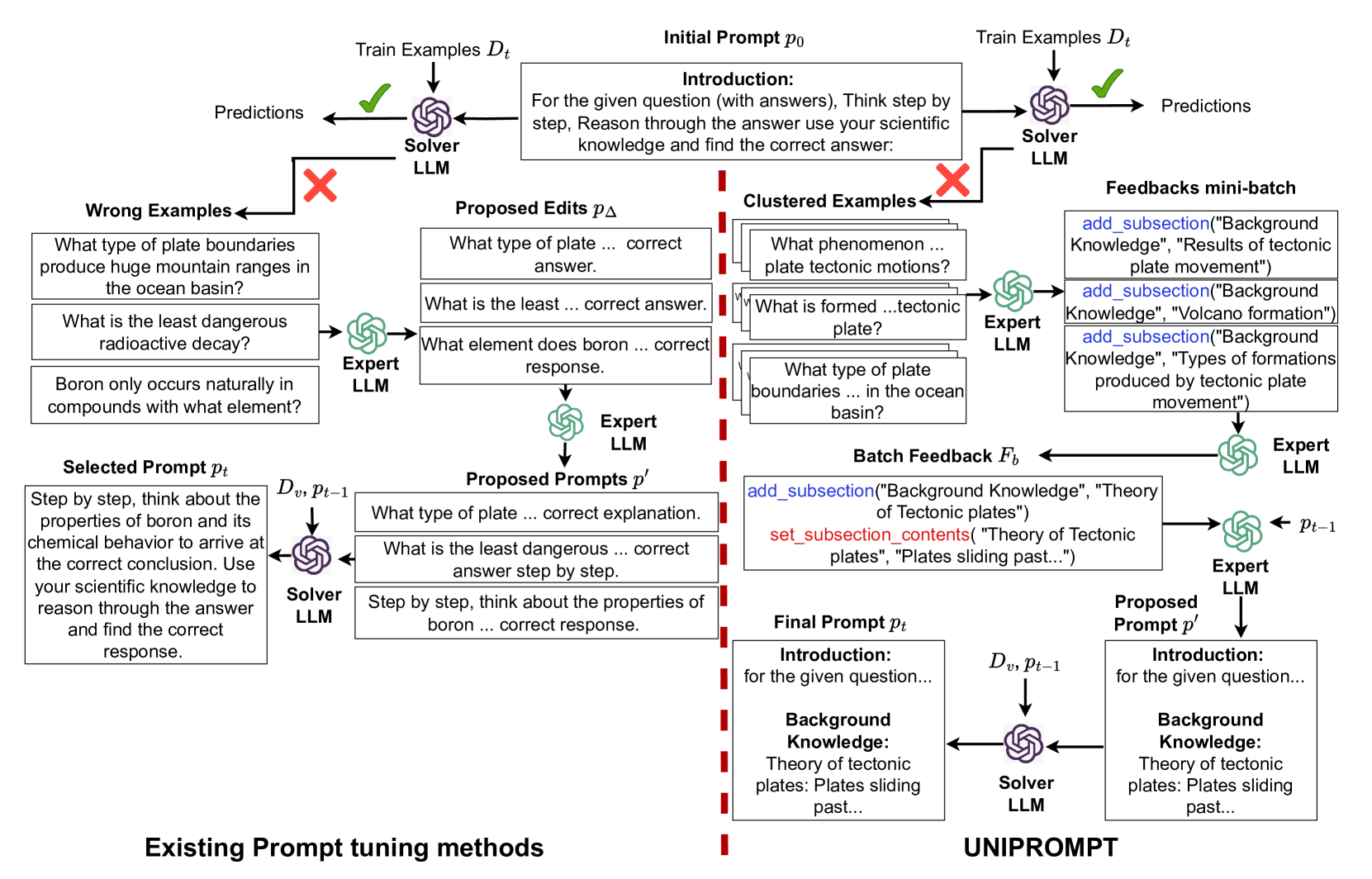
Abstract
Given a task in the form of a basic description and its training examples, prompt optimization is the problem of synthesizing the given information into a text prompt for a large language model (LLM). Humans solve this problem by also considering the different facets that define a task (e.g., counter-examples, explanations, analogies) and including them in the prompt. However, it is unclear whether existing algorithmic approaches, based on iteratively editing a given prompt or automatically selecting a few in-context examples, can cover the multiple facets required to solve a complex task. In this work, we view prompt optimization as that of learning multiple facets of a task from a set of training examples. We identify and exploit structure in the prompt optimization problem -- first, we find that prompts can be broken down into loosely coupled semantic sections that have a relatively independent effect on the prompt's performance; second, we cluster the input space and use clustered batches so that the optimization procedure can learn the different facets of a task across batches. The resulting algorithm, UniPrompt, consists of a generative model to generate initial candidates for each prompt section; and a feedback mechanism that aggregates suggested edits from multiple mini-batches into a conceptual description for the section. Empirical evaluation on multiple datasets and a real-world task shows that prompts generated using UniPrompt obtain higher accuracy than human-tuned prompts and those from state-of-the-art methods. In particular, our algorithm can generate long, complex prompts that existing methods are unable to generate. Code for UniPrompt will be available at url{https://aka.ms/uniprompt}.
Create account to get full access
Overview
- The paper explores a structured approach to prompt optimization, called Task Facet Learning, which aims to improve the performance of language models on various tasks.
- It characterizes the prompt optimization problem, proposing a framework to decompose tasks into distinct facets that can be optimized separately.
- The authors develop a gradient-based optimization method to efficiently learn prompts for each facet and show improvements on several benchmark tasks compared to existing prompt optimization techniques.
Plain English Explanation
The paper introduces a new way to optimize the prompts, or instructions, given to language models like GPT-3 to improve their performance on different tasks. The key idea is to break down each task into distinct "facets" or components, and then optimize the prompt for each facet separately.
For example, a writing task might have facets like [object Object], [object Object], and [object Object]. The researchers develop a method to efficiently learn the best prompts for each of these facets, rather than optimizing a single, one-size-fits-all prompt.
This structured approach is shown to outperform existing prompt optimization techniques on several benchmark tasks, like [object Object] and [object Object]. The authors argue that their framework provides a more systematic way to understand and improve prompt-based language model performance.
Technical Explanation
The paper introduces a novel framework called Task Facet Learning (TFL) for prompt optimization. The key idea is to decompose a given task into distinct "facets" that can be optimized separately. For example, in a writing task, the facets could be tone, structure, and style.
The authors develop a gradient-based optimization method to efficiently learn prompts for each facet. They first define a set of trainable prompt tokens that are optimized to maximize the model's performance on each facet. Then, they use a multi-task learning approach to jointly optimize the prompts for all facets, leveraging the interdependencies between them.
Experiments on several benchmark tasks, including text summarization, question answering, and commonsense reasoning, show that the TFL approach outperforms existing prompt optimization techniques, such as [object Object] and [object Object]. The authors attribute these improvements to the structured nature of their framework, which allows for more targeted and efficient prompt optimization.
Critical Analysis
The paper presents a well-structured and promising approach to prompt optimization, but there are a few potential limitations and areas for further research:
-
The authors focus on decomposing tasks into facets manually, which may not scale well to more complex tasks. Developing automated methods for facet discovery could improve the generalizability of the approach.
-
The experiments are conducted on a relatively small set of benchmark tasks. It would be valuable to see how the TFL framework performs on a wider range of real-world applications, especially those with more ambiguous or open-ended prompts.
-
The paper does not address the potential for [object Object] in the optimized prompts. Exploring methods to ensure fairness and mitigate biases in the prompt optimization process would be an important direction for future research.
Overall, the Task Facet Learning framework represents a thoughtful and structured approach to prompt optimization that could have significant implications for improving the performance of language models across a variety of tasks.
Conclusion
The paper introduces Task Facet Learning, a structured approach to prompt optimization that decomposes tasks into distinct facets and optimizes prompts for each facet separately. The authors develop a gradient-based optimization method to efficiently learn prompts for each facet and demonstrate improved performance on several benchmark tasks compared to existing prompt optimization techniques.
The key contribution of this work is the structured framework for prompt optimization, which provides a more systematic way to understand and improve the performance of language models on various tasks. While the paper highlights some limitations and areas for future research, the TFL approach represents an important step forward in the field of prompt-based language model optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
PromptWizard: Task-Aware Agent-driven Prompt Optimization Framework
Eshaan Agarwal, Vivek Dani, Tanuja Ganu, Akshay Nambi
0
0
Large language models (LLMs) have revolutionized AI across diverse domains, showcasing remarkable capabilities. Central to their success is the concept of prompting, which guides model output generation. However, manual prompt engineering is labor-intensive and domain-specific, necessitating automated solutions. This paper introduces PromptWizard, a novel framework leveraging LLMs to iteratively synthesize and refine prompts tailored to specific tasks. Unlike existing approaches, PromptWizard optimizes both prompt instructions and in-context examples, maximizing model performance. The framework iteratively refines prompts by mutating instructions and incorporating negative examples to deepen understanding and ensure diversity. It further enhances both instructions and examples with the aid of a critic, synthesizing new instructions and examples enriched with detailed reasoning steps for optimal performance. PromptWizard offers several key features and capabilities, including computational efficiency compared to state-of-the-art approaches, adaptability to scenarios with varying amounts of training data, and effectiveness with smaller LLMs. Rigorous evaluation across 35 tasks on 8 datasets demonstrates PromptWizard's superiority over existing prompt strategies, showcasing its efficacy and scalability in prompt optimization.
5/29/2024
🛠️
PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Heuristic-based Sampling
Yongchao Chen, Jacob Arkin, Yilun Hao, Yang Zhang, Nicholas Roy, Chuchu Fan
0
0
Prompt optimization aims to find the best prompt to a large language model (LLM) for a given task. LLMs have been successfully used to help find and improve prompt candidates for single-step tasks. However, realistic tasks for agents are multi-step and introduce new challenges: (1) Prompt content is likely to be more extensive and complex, making it more difficult for LLMs to analyze errors, (2) the impact of an individual step is difficult to evaluate, and (3) different people may have varied preferences about task execution. While humans struggle to optimize prompts, they are good at providing feedback about LLM outputs; we therefore introduce a new LLM-driven discrete prompt optimization framework PROMST that incorporates human-designed feedback rules to automatically offer direct suggestions for improvement. We also use an extra learned heuristic model that predicts prompt performance to efficiently sample from prompt candidates. This approach significantly outperforms both human-engineered prompts and several other prompt optimization methods across 11 representative multi-step tasks (an average 10.6%-29.3% improvement to current best methods on five LLMs respectively). We believe our work can serve as a benchmark for automatic prompt optimization for LLM-driven multi-step tasks. Datasets and Codes are available at https://github.com/yongchao98/PROMST. Project Page is available at https://yongchao98.github.io/MIT-REALM-PROMST/.
6/18/2024
Language Model Prompt Selection via Simulation Optimization
Haoting Zhang, Jinghai He, Rhonda Righter, Zeyu Zheng
0
0
With the advancement in generative language models, the selection of prompts has gained significant attention in recent years. A prompt is an instruction or description provided by the user, serving as a guide for the generative language model in content generation. Despite existing methods for prompt selection that are based on human labor, we consider facilitating this selection through simulation optimization, aiming to maximize a pre-defined score for the selected prompt. Specifically, we propose a two-stage framework. In the first stage, we determine a feasible set of prompts in sufficient numbers, where each prompt is represented by a moderate-dimensional vector. In the subsequent stage for evaluation and selection, we construct a surrogate model of the score regarding the moderate-dimensional vectors that represent the prompts. We propose sequentially selecting the prompt for evaluation based on this constructed surrogate model. We prove the consistency of the sequential evaluation procedure in our framework. We also conduct numerical experiments to demonstrate the efficacy of our proposed framework, providing practical instructions for implementation.
5/21/2024

Batch-Instructed Gradient for Prompt Evolution:Systematic Prompt Optimization for Enhanced Text-to-Image Synthesis
Xinrui Yang, Zhuohan Wang, Anthony Hu
0
0
Text-to-image models have shown remarkable progress in generating high-quality images from user-provided prompts. Despite this, the quality of these images varies due to the models' sensitivity to human language nuances. With advancements in large language models, there are new opportunities to enhance prompt design for image generation tasks. Existing research primarily focuses on optimizing prompts for direct interaction, while less attention is given to scenarios involving intermediary agents, like the Stable Diffusion model. This study proposes a Multi-Agent framework to optimize input prompts for text-to-image generation models. Central to this framework is a prompt generation mechanism that refines initial queries using dynamic instructions, which evolve through iterative performance feedback. High-quality prompts are then fed into a state-of-the-art text-to-image model. A professional prompts database serves as a benchmark to guide the instruction modifier towards generating high-caliber prompts. A scoring system evaluates the generated images, and an LLM generates new instructions based on calculated gradients. This iterative process is managed by the Upper Confidence Bound (UCB) algorithm and assessed using the Human Preference Score version 2 (HPS v2). Preliminary ablation studies highlight the effectiveness of various system components and suggest areas for future improvements.
6/14/2024