Zero-Shot Continuous Prompt Transfer: Generalizing Task Semantics Across Language Models

0

Sign in to get full access
Overview
- This research paper proposes a method called "Zero-Shot Continuous Prompt Transfer" to generalize task semantics across different language models.
- The key idea is to learn a continuous prompt that can be transferred to different language models to perform the same task, without any model-specific fine-tuning.
- This approach aims to improve the flexibility and portability of language models, making it easier to apply them to new tasks and domains.
Plain English Explanation
The paper introduces a new technique called "Zero-Shot Continuous Prompt Transfer" that allows language models to be used for different tasks without requiring extensive retraining or fine-tuning. [This builds on previous work on prompt-based learning, such as the techniques described in the papers "Minimalist Prompt Zero-Shot Policy Learning" and "Instructing Prompt-to-Prompt Generation Zero-Shot".](https://aimodels.fyi/papers/arxiv/minimalist-prompt-zero-shot-policy-learning, https://aimodels.fyi/papers/arxiv/instructing-prompt-to-prompt-generation-zero-shot)
The core idea is to learn a "continuous prompt" - a set of parameters that can be added to the input of a language model to make it perform a specific task. This continuous prompt can then be transferred to different language models, allowing them to perform the same task without any model-specific fine-tuning.
For example, imagine you have trained a language model to summarize news articles. Using the Zero-Shot Continuous Prompt Transfer technique, you could take that continuous prompt and apply it to a different language model, like GPT-3, to make it also perform news article summarization, without having to retrain GPT-3 from scratch.
[This approach is similar to the techniques described in "Convolutional Prompting Meets Language Models for Continual Learning" and "CroPrompt: Cross-Task Interactive Prompting Zero-Shot", which also explore ways to make language models more flexible and adaptable.](https://aimodels.fyi/papers/arxiv/convolutional-prompting-meets-language-models-continual-learning, https://aimodels.fyi/papers/arxiv/croprompt-cross-task-interactive-prompting-zero-shot)
The key benefit of this technique is that it can make language models more versatile and useful, as they can be quickly adapted to new tasks without the need for extensive retraining. This could be particularly valuable in domains like customer service, where language models might need to handle a wide variety of queries and tasks.
Technical Explanation
The paper proposes a method called "Zero-Shot Continuous Prompt Transfer" that allows for the transfer of task semantics across different language models. The core idea is to learn a continuous prompt - a set of parameters that can be added to the input of a language model to make it perform a specific task.
Continuous Prompt Tuning
The key component of the method is the continuous prompt tuning process, where a continuous prompt is learned for a target task. This involves optimizing the prompt parameters to maximize the performance of the language model on the task, without modifying the model's parameters.
The authors show that this continuous prompt can then be transferred to different language models, enabling them to perform the same task without any model-specific fine-tuning. This is achieved by concatenating the continuous prompt to the input of the target language model.
Critical Analysis
The paper presents a promising approach to improving the flexibility and portability of language models. By learning continuous prompts that can be transferred across models, the method addresses a key limitation of traditional fine-tuning, which requires retraining the entire model for each new task.
However, the paper does not fully explore the limitations of this approach. For example, it is unclear how well the continuous prompts would generalize to tasks or domains that are very different from the ones used in the experiments. There may also be practical challenges in implementing this approach, such as the computational overhead of learning and storing the continuous prompts.
Additionally, the paper does not address potential issues around the interpretability and transparency of the learned prompts. It would be valuable to understand how the continuous prompts work and what kinds of task-specific information they capture, as this could have implications for the robustness and trustworthiness of the language models.
Conclusion
The "Zero-Shot Continuous Prompt Transfer" method proposed in this paper offers a promising approach to improving the flexibility and portability of language models. By learning continuous prompts that can be transferred across different models, the technique allows language models to be quickly adapted to new tasks without the need for extensive retraining.
This could have significant practical implications, enabling language models to be more widely deployed and applied in a variety of domains, from customer service to scientific research. However, further research is needed to fully understand the limitations and broader implications of this approach, as well as how it compares to other methods for improving language model generalization.
Overall, the paper represents an important contribution to the field of language model adaptation and transfer learning, and the ideas presented here are likely to be built upon and expanded in future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Zero-Shot Continuous Prompt Transfer: Generalizing Task Semantics Across Language Models
Zijun Wu, Yongkang Wu, Lili Mou
Prompt tuning in natural language processing (NLP) has become an increasingly popular method for adapting large language models to specific tasks. However, the transferability of these prompts, especially continuous prompts, between different models remains a challenge. In this work, we propose a zero-shot continuous prompt transfer method, where source prompts are encoded into relative space and the corresponding target prompts are searched for transferring to target models. Experimental results confirm the effectiveness of our method, showing that 'task semantics' in continuous prompts can be generalized across various language models. Moreover, we find that combining 'task semantics' from multiple source models can further enhance the generalizability of transfer.
Read more7/15/2024
0
A Minimalist Prompt for Zero-Shot Policy Learning
Meng Song, Xuezhi Wang, Tanay Biradar, Yao Qin, Manmohan Chandraker
Transformer-based methods have exhibited significant generalization ability when prompted with target-domain demonstrations or example solutions during inference. Although demonstrations, as a way of task specification, can capture rich information that may be hard to specify by language, it remains unclear what information is extracted from the demonstrations to help generalization. Moreover, assuming access to demonstrations of an unseen task is impractical or unreasonable in many real-world scenarios, especially in robotics applications. These questions motivate us to explore what the minimally sufficient prompt could be to elicit the same level of generalization ability as the demonstrations. We study this problem in the contextural RL setting which allows for quantitative measurement of generalization and is commonly adopted by meta-RL and multi-task RL benchmarks. In this setting, the training and test Markov Decision Processes (MDPs) only differ in certain properties, which we refer to as task parameters. We show that conditioning a decision transformer on these task parameters alone can enable zero-shot generalization on par with or better than its demonstration-conditioned counterpart. This suggests that task parameters are essential for the generalization and DT models are trying to recover it from the demonstration prompt. To extract the remaining generalizable information from the supervision, we introduce an additional learnable prompt which is demonstrated to further boost zero-shot generalization across a range of robotic control, manipulation, and navigation benchmark tasks.
Read more5/13/2024

0
Enhancing Few-Shot Transfer Learning with Optimized Multi-Task Prompt Tuning through Modular Prompt Composition
Ahmad Pouramini, Hesham Faili
In recent years, multi-task prompt tuning has garnered considerable attention for its inherent modularity and potential to enhance parameter-efficient transfer learning across diverse tasks. This paper aims to analyze and improve the performance of multiple tasks by facilitating the transfer of knowledge between their corresponding prompts in a multi-task setting. Our proposed approach decomposes the prompt for each target task into a combination of shared prompts (source prompts) and a task-specific prompt (private prompt). During training, the source prompts undergo fine-tuning and are integrated with the private prompt to drive the target prompt for each task. We present and compare multiple methods for combining source prompts to construct the target prompt, analyzing the roles of both source and private prompts within each method. We investigate their contributions to task performance and offer flexible, adjustable configurations based on these insights to optimize performance. Our empirical findings clearly showcase improvements in accuracy and robustness compared to the conventional practice of prompt tuning and related works. Notably, our results substantially outperform other methods in the field in few-shot settings, demonstrating superior performance in various tasks across GLUE benchmark, among other tasks. This achievement is attained with a significantly reduced amount of training data, making our method a promising one for few-shot settings.
Read more8/26/2024
0
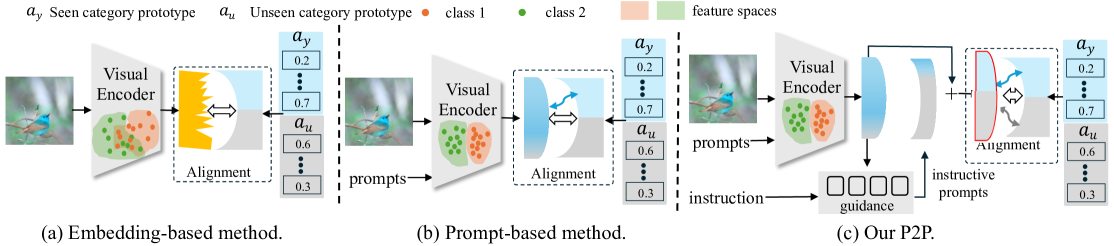
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Man Liu, Huihui Bai, Feng Li, Chunjie Zhang, Yunchao Wei, Meng Wang, Tat-Seng Chua, Yao Zhao
Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a textbf{P}rompt-to-textbf{P}rompt generation methodology (textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Read more6/6/2024