Enhancing Gaussian Process Surrogates for Optimization and Posterior Approximation via Random Exploration

0

Sign in to get full access
Overview
- This paper proposes a new Bayesian optimization algorithm that achieves improved regret bounds compared to previous methods through the use of random exploration.
- The key innovation is a "noise-free" setting where the objective function can be evaluated exactly, rather than with noisy observations.
- The authors provide theoretical analysis to show that their algorithm achieves better regret bounds than existing Bayesian optimization techniques in this noise-free setting.
Plain English Explanation
Bayesian optimization is a powerful technique for efficiently optimizing complex, black-box functions. It works by building a probabilistic model of the function (typically a Gaussian process) and then using that model to guide the search for the function's optimum.
In this paper, the authors consider a special case of Bayesian optimization where the objective function can be evaluated exactly, without any noise or uncertainty. This "noise-free" setting might arise, for example, when running computational simulations or experiments with high-precision measurement equipment.
The authors propose a new Bayesian optimization algorithm that incorporates random exploration in addition to the usual exploitation of the probabilistic model. They show that this random exploration step leads to improved theoretical guarantees on the algorithm's performance, as measured by the "regret" - the difference between the function's optimal value and the values obtained by the algorithm.
Intuitively, the random exploration helps the algorithm discover promising regions of the search space that it might have otherwise missed by relying too heavily on the probabilistic model. This can lead to faster convergence to the global optimum.
The authors provide a detailed mathematical analysis to quantify these improvements in regret bounds, demonstrating the benefits of their approach over previous Bayesian optimization techniques in the noise-free setting.
Technical Explanation
The authors consider the problem of maximizing an unknown function
The authors propose a new algorithm, called Noise-Free Bayesian Optimization with Random Exploration (NF-BORE), that combines the classic Bayesian optimization approach of building a Gaussian process model of
The authors provide a detailed theoretical analysis of the NF-BORE algorithm, proving that it achieves improved regret bounds compared to previous noise-free Bayesian optimization methods, such as the ones described in Provably Efficient Bayesian Optimization with Unknown Gaussian Processes and A Study of Bayesian Neural Network Surrogates for Bayesian Optimization.
The key insight behind the improved regret bounds is that the random exploration step helps the algorithm discover promising regions of the search space that it might have otherwise missed by relying too heavily on the Gaussian process model. This can lead to faster convergence to the global optimum.
The authors also discuss connections to related work, such as Adaptive Gradient-Enhanced Gaussian Process Surrogates for Inverse Problems and Variational Bayesian Surrogate Modelling with Application to Robust Design Optimization, which explore different approaches to Bayesian optimization and surrogate modeling.
Critical Analysis
The authors provide a strong theoretical analysis of their proposed NF-BORE algorithm, demonstrating its improved regret bounds compared to previous noise-free Bayesian optimization methods. This is an important contribution, as it advances the state-of-the-art in this area of research.
However, the paper does not address the practical implementation challenges that may arise when applying the NF-BORE algorithm to real-world problems. For example, the authors assume that the function
It would be interesting to see how the NF-BORE algorithm performs in the presence of noise, and whether the theoretical improvements in the noise-free setting translate to practical benefits in more realistic settings. The authors could also consider extending their analysis to settings with constraints or multi-objective optimization problems, which are common in many real-world applications.
Additionally, the authors do not provide any empirical evaluation of their algorithm, so it is difficult to assess its practical performance compared to existing Bayesian optimization techniques. Experimenting with the NF-BORE algorithm on a range of benchmark problems or real-world use cases would help to validate the theoretical findings and provide a more comprehensive understanding of its strengths and limitations.
Conclusion
This paper proposes a new Bayesian optimization algorithm, NF-BORE, that achieves improved regret bounds compared to previous methods in the noise-free setting. The key innovation is the incorporation of random exploration, which helps the algorithm discover promising regions of the search space that it might have otherwise missed.
The authors provide a strong theoretical analysis to quantify the benefits of their approach, but there are still open questions about the algorithm's practical performance and its applicability to more realistic optimization scenarios. Further empirical evaluation and exploration of extensions to constrained or multi-objective problems could help to fully understand the potential impact of this work.
Overall, this paper represents an important contribution to the field of Bayesian optimization, and the NF-BORE algorithm may be a valuable tool for researchers and practitioners working on optimization problems where the objective function can be evaluated exactly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Gaussian Process Surrogates for Optimization and Posterior Approximation via Random Exploration
Hwanwoo Kim, Daniel Sanz-Alonso
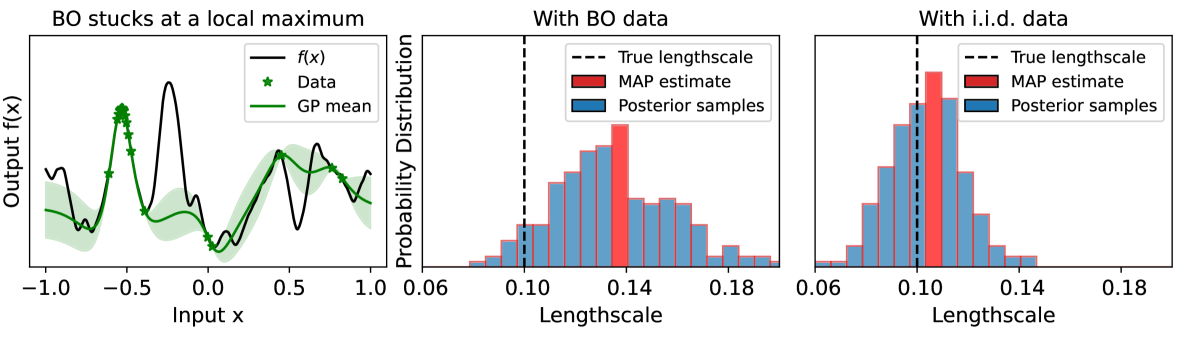
This paper proposes novel noise-free Bayesian optimization strategies that rely on a random exploration step to enhance the accuracy of Gaussian process surrogate models. The new algorithms retain the ease of implementation of the classical GP-UCB algorithm, but the additional random exploration step accelerates their convergence, nearly achieving the optimal convergence rate. Furthermore, to facilitate Bayesian inference with an intractable likelihood, we propose to utilize optimization iterates for maximum a posteriori estimation to build a Gaussian process surrogate model for the unnormalized log-posterior density. We provide bounds for the Hellinger distance between the true and the approximate posterior distributions in terms of the number of design points. We demonstrate the effectiveness of our Bayesian optimization algorithms in non-convex benchmark objective functions, in a machine learning hyperparameter tuning problem, and in a black-box engineering design problem. The effectiveness of our posterior approximation approach is demonstrated in two Bayesian inference problems for parameters of dynamical systems.
Read more7/18/2024
🛠️
0
Pseudo-Bayesian Optimization
Haoxian Chen, Henry Lam
Bayesian Optimization is a popular approach for optimizing expensive black-box functions. Its key idea is to use a surrogate model to approximate the objective and, importantly, quantify the associated uncertainty that allows a sequential search of query points that balance exploitation-exploration. Gaussian process (GP) has been a primary candidate for the surrogate model, thanks to its Bayesian-principled uncertainty quantification power and modeling flexibility. However, its challenges have also spurred an array of alternatives whose convergence properties could be more opaque. Motivated by these, we study in this paper an axiomatic framework that elicits the minimal requirements to guarantee black-box optimization convergence that could apply beyond GP-based methods. Moreover, we leverage the design freedom in our framework, which we call Pseudo-Bayesian Optimization, to construct empirically superior algorithms. In particular, we show how using simple local regression, and a suitable randomized prior construction to quantify uncertainty, not only guarantees convergence but also consistently outperforms state-of-the-art benchmarks in examples ranging from high-dimensional synthetic experiments to realistic hyperparameter tuning and robotic applications.
Read more6/21/2024
0
Provably Efficient Bayesian Optimization with Unbiased Gaussian Process Hyperparameter Estimation
Huong Ha, Vu Nguyen, Hung Tran-The, Hongyu Zhang, Xiuzhen Zhang, Anton van den Hengel
Gaussian process (GP) based Bayesian optimization (BO) is a powerful method for optimizing black-box functions efficiently. The practical performance and theoretical guarantees of this approach depend on having the correct GP hyperparameter values, which are usually unknown in advance and need to be estimated from the observed data. However, in practice, these estimations could be incorrect due to biased data sampling strategies used in BO. This can lead to degraded performance and break the sub-linear global convergence guarantee of BO. To address this issue, we propose a new BO method that can sub-linearly converge to the objective function's global optimum even when the true GP hyperparameters are unknown in advance and need to be estimated from the observed data. Our method uses a multi-armed bandit technique (EXP3) to add random data points to the BO process, and employs a novel training loss function for the GP hyperparameter estimation process that ensures consistent estimation. We further provide theoretical analysis of our proposed method. Finally, we demonstrate empirically that our method outperforms existing approaches on various synthetic and real-world problems.
Read more6/7/2024
🧠
0
A Study of Bayesian Neural Network Surrogates for Bayesian Optimization
Yucen Lily Li, Tim G. J. Rudner, Andrew Gordon Wilson
Bayesian optimization is a highly efficient approach to optimizing objective functions which are expensive to query. These objectives are typically represented by Gaussian process (GP) surrogate models which are easy to optimize and support exact inference. While standard GP surrogates have been well-established in Bayesian optimization, Bayesian neural networks (BNNs) have recently become practical function approximators, with many benefits over standard GPs such as the ability to naturally handle non-stationarity and learn representations for high-dimensional data. In this paper, we study BNNs as alternatives to standard GP surrogates for optimization. We consider a variety of approximate inference procedures for finite-width BNNs, including high-quality Hamiltonian Monte Carlo, low-cost stochastic MCMC, and heuristics such as deep ensembles. We also consider infinite-width BNNs, linearized Laplace approximations, and partially stochastic models such as deep kernel learning. We evaluate this collection of surrogate models on diverse problems with varying dimensionality, number of objectives, non-stationarity, and discrete and continuous inputs. We find: (i) the ranking of methods is highly problem dependent, suggesting the need for tailored inductive biases; (ii) HMC is the most successful approximate inference procedure for fully stochastic BNNs; (iii) full stochasticity may be unnecessary as deep kernel learning is relatively competitive; (iv) deep ensembles perform relatively poorly; (v) infinite-width BNNs are particularly promising, especially in high dimensions.
Read more5/9/2024