Enhancing Gender-Inclusive Machine Translation with Neomorphemes and Large Language Models

0
💬
Sign in to get full access
Overview
- Machine translation (MT) models are known to have gender bias, especially when translating into languages with extensive gendered morphology.
- They often fail to use gender-inclusive language that represents non-binary identities.
- This paper explores the use of gender-inclusive "neomorphemes" - new linguistic elements that avoid binary gender markings - as an approach to fairer MT.
- The researchers investigate prompting techniques with large language models (LLMs) to translate from English to Italian using neomorphemes.
- They release a new resource called Neo-GATE to evaluate gender-inclusive En-It translation with neomorphemes, and assess four LLMs on this novel MT task.
Plain English Explanation
Machine translation (MT) models, which convert text from one language to another, can often have biases when it comes to gender. This is especially true when translating into languages that have extensive gendered grammar, like verb endings or pronouns that change based on the gender of the subject. These MT models sometimes fail to use inclusive language that represents non-binary identities.
To address this issue, the researchers in this paper looked at using "neomorphemes" - new linguistic elements that avoid binary male/female gender markings. They explored techniques for prompting large language models (LLMs), which are powerful AI models trained on vast amounts of text, to translate from English to Italian using these neomorphemes.
Since this is a relatively new area, the researchers also created a new evaluation resource called Neo-GATE. This allows them to assess how well different LLM models perform at this gender-inclusive translation task using neomorphemes.
The key idea is to move beyond the traditional male/female gender binary that most MT systems are designed for, and find ways to generate translation outputs that are more representative of the full spectrum of gender identities.
Technical Explanation
The paper investigates the use of gender-inclusive "neomorphemes" as an approach to address gender bias in machine translation (MT) models, especially when translating into languages with extensive gendered morphology like Italian.
The researchers explore prompting techniques with large language models (LLMs) to translate from English to Italian using these neomorphemes. They assess four different LLM families and sizes, as well as various prompt formats, to identify the strengths and weaknesses of each on this novel MT task.
To enable this evaluation, the researchers release a new resource called Neo-GATE, designed to assess gender-inclusive En-It translation with neomorphemes. This helps fill an important gap, as this area has been under-explored due to its novelty and lack of publicly available evaluation data.
The experiments show that while current LLMs can generate some gender-inclusive translations using neomorphemes, there is still significant room for improvement. The models often struggle with consistency, morphological agreement, and accurately representing non-binary identities. The paper discusses the implications of these findings and highlights directions for future research in this emerging area of fairer machine translation.
Critical Analysis
The paper makes a valuable contribution by exploring the use of gender-inclusive neomorphemes as an approach to address bias in machine translation. This is an important issue, as MT models that fail to represent the full spectrum of gender identities can perpetuate harmful stereotypes and marginalization.
However, the research is still quite preliminary, as the authors acknowledge. The evaluation is limited to a single language pair (En-It), and the neomorpheme vocabulary used is relatively small. There may be challenges in scaling this approach to broader use cases and language contexts.
Additionally, the paper does not delve deeply into the societal and ethical implications of this work. While the intent is to promote more inclusive translation, the real-world impact on marginalized communities is not fully explored. Further research is needed to understand how these techniques would perform in high-stakes applications.
Despite these limitations, the paper lays important groundwork for future developments in this area. The Neo-GATE resource in particular is a valuable contribution that can spur more research and innovation in gender-inclusive machine translation. As the field continues to evolve, it will be critical to center the perspectives of diverse stakeholders and ensure these technologies empower rather than further marginalize underrepresented groups.
Conclusion
This paper presents a novel approach to addressing gender bias in machine translation by exploring the use of gender-inclusive neomorphemes. Through the release of the Neo-GATE evaluation resource and assessment of different large language models, the researchers shed light on both the potential and limitations of this technique.
While current MT models struggle to consistently and accurately represent non-binary identities using neomorphemes, this work represents an important step towards fairer and more inclusive machine translation. As language technologies become increasingly ubiquitous, it is crucial that they evolve to better reflect the full diversity of human experience.
The insights from this paper can inform future research directions in this emerging area, ultimately working towards MT systems that empower rather than marginalize underrepresented groups. Continued advancements in this direction, combined with thoughtful consideration of the societal implications, hold promise for more equitable and representative language technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Enhancing Gender-Inclusive Machine Translation with Neomorphemes and Large Language Models
Andrea Piergentili, Beatrice Savoldi, Matteo Negri, Luisa Bentivogli
Machine translation (MT) models are known to suffer from gender bias, especially when translating into languages with extensive gendered morphology. Accordingly, they still fall short in using gender-inclusive language, also representative of non-binary identities. In this paper, we look at gender-inclusive neomorphemes, neologistic elements that avoid binary gender markings as an approach towards fairer MT. In this direction, we explore prompting techniques with large language models (LLMs) to translate from English into Italian using neomorphemes. So far, this area has been under-explored due to its novelty and the lack of publicly available evaluation resources. We fill this gap by releasing Neo-GATE, a resource designed to evaluate gender-inclusive en-it translation with neomorphemes. With Neo-GATE, we assess four LLMs of different families and sizes and different prompt formats, identifying strengths and weaknesses of each on this novel task for MT.
Read more5/15/2024

0
The power of Prompts: Evaluating and Mitigating Gender Bias in MT with LLMs
Aleix Sant, Carlos Escolano, Audrey Mash, Francesca De Luca Fornaciari, Maite Melero
This paper studies gender bias in machine translation through the lens of Large Language Models (LLMs). Four widely-used test sets are employed to benchmark various base LLMs, comparing their translation quality and gender bias against state-of-the-art Neural Machine Translation (NMT) models for English to Catalan (En $rightarrow$ Ca) and English to Spanish (En $rightarrow$ Es) translation directions. Our findings reveal pervasive gender bias across all models, with base LLMs exhibiting a higher degree of bias compared to NMT models. To combat this bias, we explore prompting engineering techniques applied to an instruction-tuned LLM. We identify a prompt structure that significantly reduces gender bias by up to 12% on the WinoMT evaluation dataset compared to more straightforward prompts. These results significantly reduce the gender bias accuracy gap between LLMs and traditional NMT systems.
Read more7/29/2024
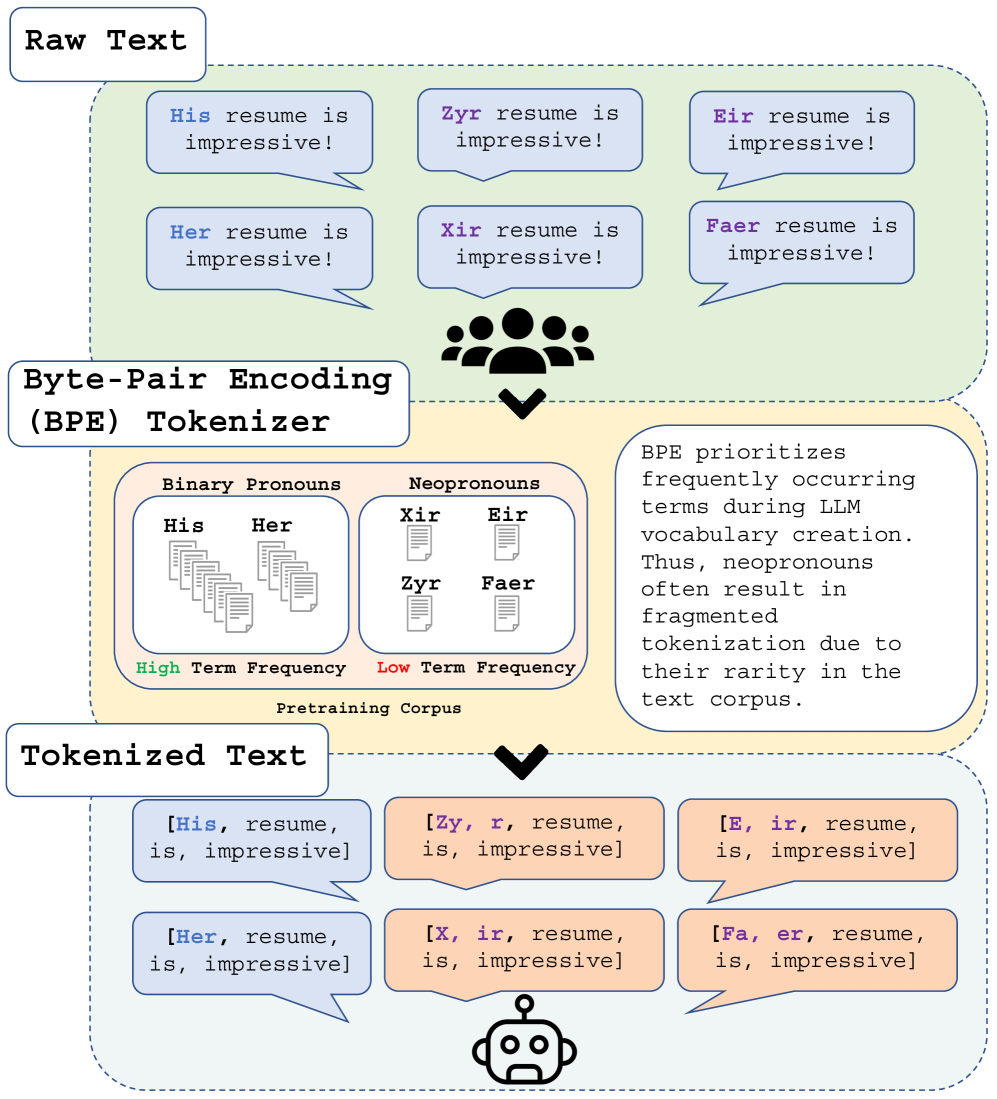
0
Tokenization Matters: Navigating Data-Scarce Tokenization for Gender Inclusive Language Technologies
Anaelia Ovalle, Ninareh Mehrabi, Palash Goyal, Jwala Dhamala, Kai-Wei Chang, Richard Zemel, Aram Galstyan, Yuval Pinter, Rahul Gupta
Gender-inclusive NLP research has documented the harmful limitations of gender binary-centric large language models (LLM), such as the inability to correctly use gender-diverse English neopronouns (e.g., xe, zir, fae). While data scarcity is a known culprit, the precise mechanisms through which scarcity affects this behavior remain underexplored. We discover LLM misgendering is significantly influenced by Byte-Pair Encoding (BPE) tokenization, the tokenizer powering many popular LLMs. Unlike binary pronouns, BPE overfragments neopronouns, a direct consequence of data scarcity during tokenizer training. This disparate tokenization mirrors tokenizer limitations observed in multilingual and low-resource NLP, unlocking new misgendering mitigation strategies. We propose two techniques: (1) pronoun tokenization parity, a method to enforce consistent tokenization across gendered pronouns, and (2) utilizing pre-existing LLM pronoun knowledge to improve neopronoun proficiency. Our proposed methods outperform finetuning with standard BPE, improving neopronoun accuracy from 14.1% to 58.4%. Our paper is the first to link LLM misgendering to tokenization and deficient neopronoun grammar, indicating that LLMs unable to correctly treat neopronouns as pronouns are more prone to misgender.
Read more4/9/2024

0
Generating Gender Alternatives in Machine Translation
Sarthak Garg, Mozhdeh Gheini, Clara Emmanuel, Tatiana Likhomanenko, Qin Gao, Matthias Paulik
Machine translation (MT) systems often translate terms with ambiguous gender (e.g., English term the nurse) into the gendered form that is most prevalent in the systems' training data (e.g., enfermera, the Spanish term for a female nurse). This often reflects and perpetuates harmful stereotypes present in society. With MT user interfaces in mind that allow for resolving gender ambiguity in a frictionless manner, we study the problem of generating all grammatically correct gendered translation alternatives. We open source train and test datasets for five language pairs and establish benchmarks for this task. Our key technical contribution is a novel semi-supervised solution for generating alternatives that integrates seamlessly with standard MT models and maintains high performance without requiring additional components or increasing inference overhead.
Read more7/31/2024