Enhancing Hardware Fault Tolerance in Machines with Reinforcement Learning Policy Gradient Algorithms

0

Sign in to get full access
Overview
- Explores enhancing hardware fault tolerance in machines using reinforcement learning policy gradient algorithms
- Proposes a novel method to improve a machine's resilience to hardware faults
- Demonstrates the effectiveness of the approach through simulation experiments
Plain English Explanation
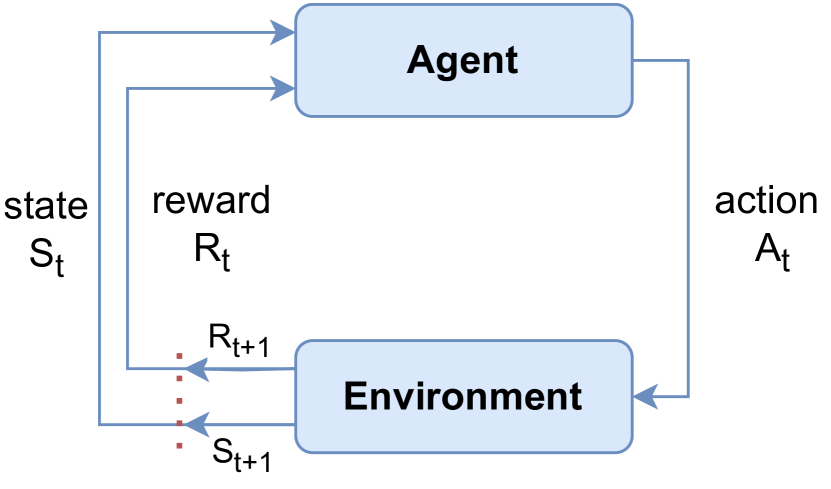
The paper describes a way to make machines more resilient to hardware faults, such as malfunctioning sensors or actuators, using reinforcement learning techniques. The key idea is to train the machine to adapt its behavior in response to these faults, rather than relying on the hardware to always function perfectly.
The researchers use policy gradient algorithms, a type of reinforcement learning, to enable the machine to learn how to cope with different fault scenarios. The machine is trained to take actions that minimize the impact of faults, even if it means modifying its normal behavior.
For example, if a sensor fails, the machine might learn to rely more on other sensors or adjust its movements to compensate. By training the machine to be "fault-tolerant," the researchers aim to improve the overall reliability and robustness of the system, even when underlying hardware components fail.
Technical Explanation
The paper proposes a reinforcement learning-based approach to enhance hardware fault tolerance in machines. The core idea is to leverage policy gradient algorithms, such as Soft Actor-Critic, to train the machine to adapt its behavior in response to simulated hardware faults.
The authors design a simulation environment that can inject different types of hardware faults, such as sensor or actuator failures, into the machine's control loop. The reinforcement learning agent is then trained to learn a policy that minimizes the impact of these faults, even if it means deviating from the machine's optimal behavior in the fault-free case.
The key technical contributions include:
- A fault injection framework that can simulate various hardware fault scenarios in a systematic manner.
- A policy gradient-based training approach that enables the machine to learn fault-tolerant behaviors through interaction with the simulated environment.
- Extensive experimental evaluation demonstrating the effectiveness of the proposed method in improving the machine's resilience to hardware faults.
The results show that the trained policy gradient agent can significantly outperform a baseline policy in terms of task completion and other performance metrics, even in the presence of hardware faults. The authors also discuss potential limitations and future research directions, such as extending the approach to handle more complex fault models or incorporating safety constraints into the training process.
Critical Analysis
The paper presents a promising approach to enhancing hardware fault tolerance in machines using reinforcement learning. The authors' focus on developing a systematic fault injection framework and leveraging policy gradient algorithms to enable adaptive fault-tolerant behaviors is a valuable contribution to the field.
One potential limitation of the study is the relatively simple fault models considered, such as sensor or actuator failures. In real-world applications, hardware faults can be more complex and unpredictable, involving interactions between multiple components. The authors acknowledge this and suggest extending the approach to handle more advanced fault models as future work.
Additionally, the paper does not explicitly address the issue of safety and reliability in the presence of hardware faults. While the trained policy gradient agent demonstrates improved performance, there may be scenarios where the machine's adaptive behavior could lead to undesirable or unsafe outcomes. Incorporating safety constraints or risk-aware training into the framework could be an important area for further research.
Overall, the paper presents an interesting and practical approach to enhancing hardware fault tolerance in machines. The authors' use of reinforcement learning techniques, particularly policy gradient algorithms, demonstrates the potential of adaptive and data-driven methods for addressing hardware reliability challenges. As the authors suggest, continued research in this direction could lead to more robust and resilient machine systems.
Conclusion
This paper explores a novel approach to improving the hardware fault tolerance of machines using reinforcement learning policy gradient algorithms. By training the machine to adapt its behavior in response to simulated hardware faults, the researchers demonstrate the potential to enhance the overall reliability and resilience of the system, even when underlying components fail.
The key contributions of the work include a systematic fault injection framework and a policy gradient-based training approach that enables the machine to learn fault-tolerant behaviors. The experimental results show promising improvements in task completion and other performance metrics, suggesting that this approach could be valuable for a wide range of machine applications that require high levels of hardware reliability and robustness.
While the paper highlights several promising directions, further research is needed to address potential limitations, such as more complex fault models and safety considerations. Nonetheless, this work represents an important step forward in the development of more resilient and adaptive machine systems that can better withstand the challenges of hardware failures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Hardware Fault Tolerance in Machines with Reinforcement Learning Policy Gradient Algorithms
Sheila Schoepp, Mehran Taghian, Shotaro Miwa, Yoshihiro Mitsuka, Shadan Golestan, Osmar Zaiane
Industry is rapidly moving towards fully autonomous and interconnected systems that can detect and adapt to changing conditions, including machine hardware faults. Traditional methods for adding hardware fault tolerance to machines involve duplicating components and algorithmically reconfiguring a machine's processes when a fault occurs. However, the growing interest in reinforcement learning-based robotic control offers a new perspective on achieving hardware fault tolerance. However, limited research has explored the potential of these approaches for hardware fault tolerance in machines. This paper investigates the potential of two state-of-the-art reinforcement learning algorithms, Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC), to enhance hardware fault tolerance into machines. We assess the performance of these algorithms in two OpenAI Gym simulated environments, Ant-v2 and FetchReach-v1. Robot models in these environments are subjected to six simulated hardware faults. Additionally, we conduct an ablation study to determine the optimal method for transferring an agent's knowledge, acquired through learning in a normal (pre-fault) environment, to a (post-)fault environment in a continual learning setting. Our results demonstrate that reinforcement learning-based approaches can enhance hardware fault tolerance in simulated machines, with adaptation occurring within minutes. Specifically, PPO exhibits the fastest adaptation when retaining the knowledge within its models, while SAC performs best when discarding all acquired knowledge. Overall, this study highlights the potential of reinforcement learning-based approaches, such as PPO and SAC, for hardware fault tolerance in machines. These findings pave the way for the development of robust and adaptive machines capable of effectively operating in real-world scenarios.
Read more7/23/2024
0
Optimizing Deep Reinforcement Learning for Adaptive Robotic Arm Control
Jonaid Shianifar, Michael Schukat, Karl Mason
In this paper, we explore the optimization of hyperparameters for the Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO) algorithms using the Tree-structured Parzen Estimator (TPE) in the context of robotic arm control with seven Degrees of Freedom (DOF). Our results demonstrate a significant enhancement in algorithm performance, TPE improves the success rate of SAC by 10.48 percentage points and PPO by 34.28 percentage points, where models trained for 50K episodes. Furthermore, TPE enables PPO to converge to a reward within 95% of the maximum reward 76% faster than without TPE, which translates to about 40K fewer episodes of training required for optimal performance. Also, this improvement for SAC is 80% faster than without TPE. This study underscores the impact of advanced hyperparameter optimization on the efficiency and success of deep reinforcement learning algorithms in complex robotic tasks.
Read more7/4/2024
🤷
0
PAC-Bayesian Soft Actor-Critic Learning
Bahareh Tasdighi, Abdullah Akgul, Manuel Haussmann, Kenny Kazimirzak Brink, Melih Kandemir
Actor-critic algorithms address the dual goals of reinforcement learning (RL), policy evaluation and improvement via two separate function approximators. The practicality of this approach comes at the expense of training instability, caused mainly by the destructive effect of the approximation errors of the critic on the actor. We tackle this bottleneck by employing an existing Probably Approximately Correct (PAC) Bayesian bound for the first time as the critic training objective of the Soft Actor-Critic (SAC) algorithm. We further demonstrate that online learning performance improves significantly when a stochastic actor explores multiple futures by critic-guided random search. We observe our resulting algorithm to compare favorably against the state-of-the-art SAC implementation on multiple classical control and locomotion tasks in terms of both sample efficiency and regret.
Read more6/11/2024
🚀
0
ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
Kai-Chieh Hsu, Duy Phuong Nguyen, Jaime Fern'andez Fisac
The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable deep methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial disturbance agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
Read more6/11/2024