Optimizing Deep Reinforcement Learning for Adaptive Robotic Arm Control

0
Sign in to get full access
Overview
- This paper explores the use of deep reinforcement learning (DRL) techniques to optimize the control of robotic arms for adaptive tasks.
- The researchers investigate the impact of various hyperparameter settings on the performance of DRL algorithms for robotic arm control.
- The goal is to develop an efficient and adaptive control system that can handle a wide range of robotic arm tasks.
Plain English Explanation
Robotic arms are used in many industries, such as manufacturing and healthcare, to perform a variety of tasks. However, programming these robotic arms can be challenging, as the tasks they need to perform can be complex and constantly changing.
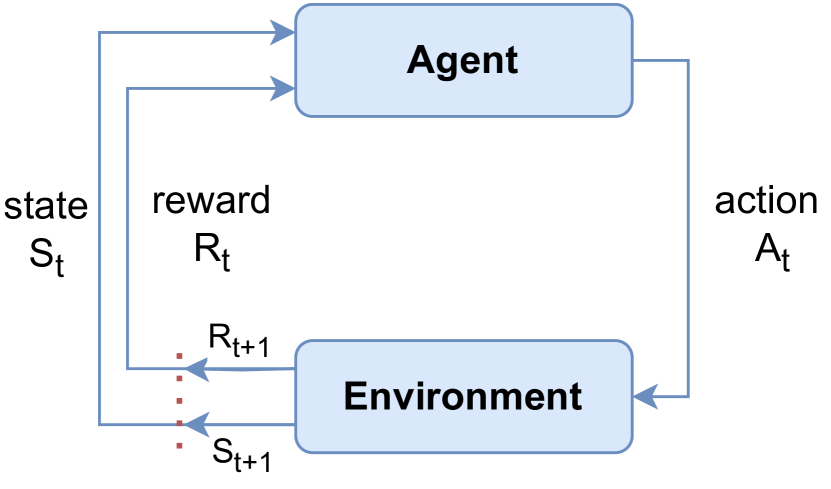
The researchers in this paper looked at using a technique called deep reinforcement learning (DRL) to help control robotic arms more effectively. DRL is a type of machine learning that allows a system to learn how to perform a task by trial and error, similar to how a human or animal might learn.
The researchers specifically focused on optimizing the hyperparameters, or settings, of the DRL algorithms to see which ones worked best for controlling robotic arms. Hyperparameters are important because they can greatly affect the performance of a machine learning model.
By testing different hyperparameter settings, the researchers aimed to develop a DRL-based control system that could adapt to a wide range of robotic arm tasks. This would make it easier to program robotic arms to perform complex, real-world tasks without having to manually fine-tune the control system for each new task.
Technical Explanation
The researchers in this paper investigated the use of deep reinforcement learning (DRL) techniques to optimize the control of robotic arms for adaptive tasks. Specifically, they explored the impact of various hyperparameter settings on the performance of DRL algorithms, such as Proximal Policy Optimization (PPO) and Joint PPO, for robotic arm control.
The researchers used a simulated robotic arm environment to test their DRL-based control system. They evaluated the performance of the system under different hyperparameter settings, including the learning rate, discount factor, and entropy coefficient. The goal was to identify the optimal hyperparameter configuration that would allow the DRL agent to learn an effective control policy for a wide range of robotic arm tasks.
The researchers also investigated the use of PAC-Bayesian Soft Actor-Critic (PAC-SAC) as an alternative DRL algorithm for robotic arm control. PAC-SAC is a recently proposed algorithm that aims to provide better exploration-exploitation trade-offs and more stable learning compared to traditional DRL methods.
The results of the experiments showed that the DRL-based control system was able to adaptively control the robotic arm and perform various tasks, such as reaching and grasping, with high accuracy. The researchers found that the hyperparameter settings had a significant impact on the performance of the DRL algorithms, and that the optimal settings varied depending on the specific task and environment.
Critical Analysis
The researchers in this paper make a compelling case for the use of DRL techniques to enhance the control of robotic arms for adaptive tasks. By optimizing the hyperparameter settings of DRL algorithms, they were able to develop a control system that could effectively handle a wide range of robotic arm tasks.
One potential limitation of the research is that it was conducted in a simulated environment, which may not fully capture the complexity and variability of real-world robotic arm tasks. Further research on the deployment of these DRL-based control systems in physical robotic arm environments would be valuable to assess their performance and practical applicability.
Additionally, the researchers focused primarily on optimizing the hyperparameter settings of the DRL algorithms. While this is an important aspect of DRL, there may be other factors, such as the choice of reward function or the architecture of the neural network, that could also significantly impact the performance of the control system. Exploring these additional design choices could further improve the effectiveness of the DRL-based robotic arm control.
Overall, this research represents an important step towards developing more adaptive and efficient control systems for robotic arms. The insights gained from the hyperparameter optimization process and the exploration of alternative DRL algorithms, such as PAC-SAC, provide a valuable foundation for future work in this area.
Conclusion
This paper demonstrates the potential of deep reinforcement learning (DRL) techniques to enhance the control of robotic arms for adaptive tasks. By optimizing the hyperparameter settings of DRL algorithms, the researchers were able to develop a control system that could effectively handle a wide range of robotic arm tasks in a simulated environment.
The findings of this research contribute to the ongoing efforts to create more flexible and adaptive control systems for robotic arms, which are crucial for various applications in industries such as manufacturing, healthcare, and beyond. While the research was conducted in a simulated setting, the insights gained can inform future work on the deployment of DRL-based control systems in physical robotic arm environments.
As the field of robotics continues to evolve, the integration of advanced machine learning techniques like DRL will likely play an increasingly important role in developing more intelligent and adaptable robotic systems. This paper serves as an important step in that direction, and highlights the value of continued research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Deep Reinforcement Learning for Adaptive Robotic Arm Control
Jonaid Shianifar, Michael Schukat, Karl Mason
In this paper, we explore the optimization of hyperparameters for the Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO) algorithms using the Tree-structured Parzen Estimator (TPE) in the context of robotic arm control with seven Degrees of Freedom (DOF). Our results demonstrate a significant enhancement in algorithm performance, TPE improves the success rate of SAC by 10.48 percentage points and PPO by 34.28 percentage points, where models trained for 50K episodes. Furthermore, TPE enables PPO to converge to a reward within 95% of the maximum reward 76% faster than without TPE, which translates to about 40K fewer episodes of training required for optimal performance. Also, this improvement for SAC is 80% faster than without TPE. This study underscores the impact of advanced hyperparameter optimization on the efficiency and success of deep reinforcement learning algorithms in complex robotic tasks.
Read more7/4/2024

0
Enhancing Hardware Fault Tolerance in Machines with Reinforcement Learning Policy Gradient Algorithms
Sheila Schoepp, Mehran Taghian, Shotaro Miwa, Yoshihiro Mitsuka, Shadan Golestan, Osmar Zaiane
Industry is rapidly moving towards fully autonomous and interconnected systems that can detect and adapt to changing conditions, including machine hardware faults. Traditional methods for adding hardware fault tolerance to machines involve duplicating components and algorithmically reconfiguring a machine's processes when a fault occurs. However, the growing interest in reinforcement learning-based robotic control offers a new perspective on achieving hardware fault tolerance. However, limited research has explored the potential of these approaches for hardware fault tolerance in machines. This paper investigates the potential of two state-of-the-art reinforcement learning algorithms, Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC), to enhance hardware fault tolerance into machines. We assess the performance of these algorithms in two OpenAI Gym simulated environments, Ant-v2 and FetchReach-v1. Robot models in these environments are subjected to six simulated hardware faults. Additionally, we conduct an ablation study to determine the optimal method for transferring an agent's knowledge, acquired through learning in a normal (pre-fault) environment, to a (post-)fault environment in a continual learning setting. Our results demonstrate that reinforcement learning-based approaches can enhance hardware fault tolerance in simulated machines, with adaptation occurring within minutes. Specifically, PPO exhibits the fastest adaptation when retaining the knowledge within its models, while SAC performs best when discarding all acquired knowledge. Overall, this study highlights the potential of reinforcement learning-based approaches, such as PPO and SAC, for hardware fault tolerance in machines. These findings pave the way for the development of robust and adaptive machines capable of effectively operating in real-world scenarios.
Read more7/23/2024

0
Comparison of Model Predictive Control and Proximal Policy Optimization for a 1-DOF Helicopter System
Georg Schafer, Jakob Rehrl, Stefan Huber, Simon Hirlaender
This study conducts a comparative analysis of Model Predictive Control (MPC) and Proximal Policy Optimization (PPO), a Deep Reinforcement Learning (DRL) algorithm, applied to a 1-Degree of Freedom (DOF) Quanser Aero 2 system. Classical control techniques such as MPC and Linear Quadratic Regulator (LQR) are widely used due to their theoretical foundation and practical effectiveness. However, with advancements in computational techniques and machine learning, DRL approaches like PPO have gained traction in solving optimal control problems through environment interaction. This paper systematically evaluates the dynamic response characteristics of PPO and MPC, comparing their performance, computational resource consumption, and implementation complexity. Experimental results show that while LQR achieves the best steady-state accuracy, PPO excels in rise-time and adaptability, making it a promising approach for applications requiring rapid response and adaptability. Additionally, we have established a baseline for future RL-related research on this specific testbed. We also discuss the strengths and limitations of each control strategy, providing recommendations for selecting appropriate controllers for real-world scenarios.
Read more8/29/2024
0
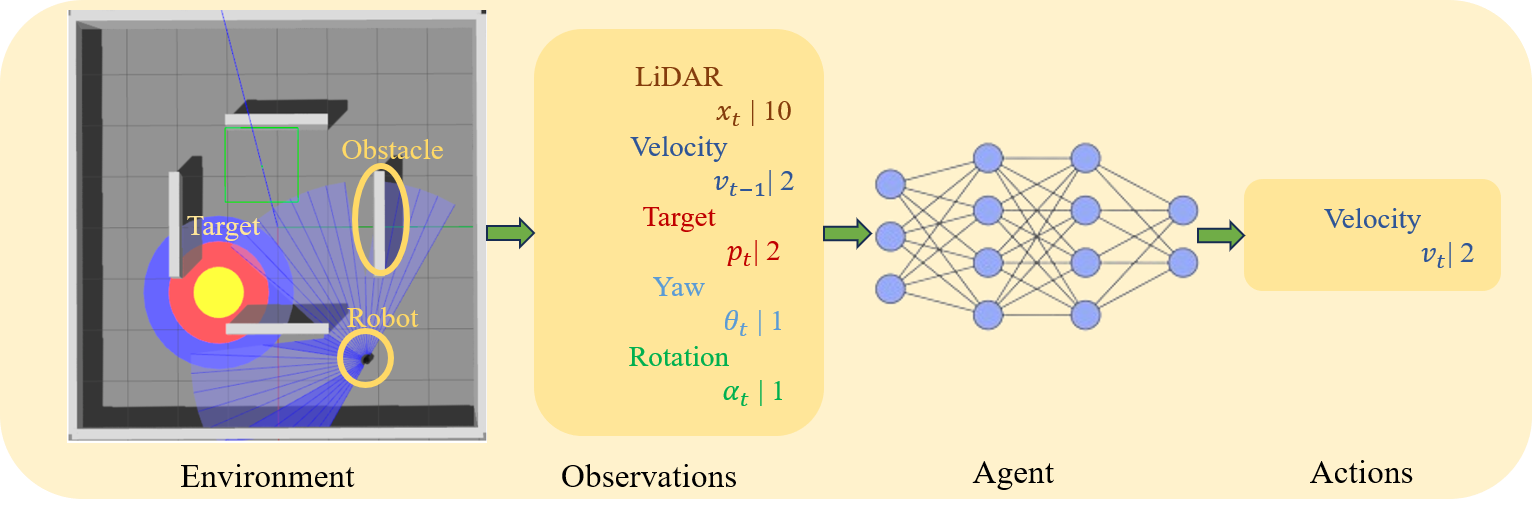
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini, Mohammad Ali Nekoui
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
Read more8/9/2024