Improving SMOTE via Fusing Conditional VAE for Data-adaptive Noise Filtering

0

Sign in to get full access
Overview
- This paper proposes a new approach called IFCVN (Improving SMOTE via Fusing Conditional VAE for Data-adaptive Noise Filtering) to address the limitations of the popular SMOTE (Synthetic Minority Over-sampling Technique) method for generating synthetic data.
- The key idea is to combine a Conditional Variational Autoencoder (CVAE) with SMOTE to create more realistic and diverse synthetic samples, while also identifying and removing noisy data points.
- The authors demonstrate that IFCVN outperforms SMOTE and other state-of-the-art data augmentation techniques on several imbalanced tabular datasets.
Plain English Explanation
The paper tackles the problem of dealing with imbalanced datasets, where some classes have significantly fewer data points than others. This can be a common issue in many real-world machine learning applications, such as fraud detection or disease diagnosis.
One popular approach to address this is SMOTE, which generates new synthetic data points in the minority class to balance out the dataset. However, SMOTE has some limitations - it can create unrealistic samples and may not be able to handle noisy or outlier data points effectively.
The authors' IFCVN method tries to improve on SMOTE by using a more sophisticated machine learning technique called a Conditional Variational Autoencoder (CVAE). CVAEs are a type of generative model that can learn the underlying patterns in the data and generate new, realistic samples.
By combining SMOTE with a CVAE, IFCVN is able to create more diverse and plausible synthetic data points. Additionally, the CVAE component helps identify and remove noisy or low-quality data points from the original dataset, which can further improve the performance of machine learning models trained on the augmented data.
The authors show through experiments on several real-world datasets that IFCVN outperforms SMOTE and other state-of-the-art data augmentation techniques, leading to better performance on imbalanced classification tasks.
Technical Explanation
The key technical components of the IFCVN approach are:
-
Conditional Variational Autoencoder (CVAE): The authors use a CVAE model, which is an extension of the standard Variational Autoencoder (VAE) architecture. The CVAE takes in both the input data and the class labels, allowing it to generate new samples conditioned on the class information.
-
Data-adaptive Noise Filtering: The authors leverage the latent space of the CVAE to identify and remove noisy or low-quality data points from the original dataset. This is done by defining a "noise score" for each data point based on its distance from the class-conditional latent distributions learned by the CVAE.
-
SMOTE-based Synthetic Data Generation: After filtering out the noisy data points, the authors use SMOTE to generate new synthetic samples in the minority class. However, instead of directly applying SMOTE, they use the CVAE to generate the synthetic samples, which helps create more diverse and realistic data points.
The authors evaluate IFCVN on several imbalanced tabular datasets from the UCI Machine Learning Repository and OpenML. They compare the performance of IFCVN to SMOTE, as well as other state-of-the-art data augmentation techniques, such as ADASYN and GAN-Ensemble. The results show that IFCVN consistently outperforms these methods in terms of various performance metrics, including accuracy, F1-score, and Area Under the Receiver Operating Characteristic (AUROC) curve.
Critical Analysis
The authors have made a solid contribution to the field of data augmentation for imbalanced datasets. The IFCVN approach leverages the strengths of both SMOTE and Conditional Variational Autoencoders to address the limitations of SMOTE, such as generating unrealistic synthetic samples and being susceptible to noisy data.
However, there are a few potential limitations and areas for further research:
- The authors only evaluate IFCVN on tabular datasets, and it would be interesting to see how it performs on other types of data, such as images or text.
- The noise filtering approach relies on a chosen threshold for the noise score, which may require careful tuning for different datasets. An adaptive or automated method for setting this threshold could be explored.
- The authors do not provide a detailed analysis of the computational complexity and training time of IFCVN compared to the other methods. This information would be useful for practitioners to assess the practical applicability of the approach.
Overall, the IFCVN method represents a promising step forward in addressing the challenges of imbalanced datasets, and the authors' work provides a solid foundation for further research and development in this area.
Conclusion
The paper proposes a new data augmentation technique called IFCVN (Improving SMOTE via Fusing Conditional VAE for Data-adaptive Noise Filtering) that combines the strengths of SMOTE and Conditional Variational Autoencoders to generate more realistic and diverse synthetic samples, while also identifying and removing noisy data points.
The key contributions of IFCVN are:
- Leveraging a Conditional Variational Autoencoder to generate higher-quality synthetic samples compared to SMOTE.
- Incorporating a data-adaptive noise filtering approach to remove low-quality data points from the original dataset.
- Demonstrating superior performance on several imbalanced tabular datasets compared to SMOTE and other state-of-the-art data augmentation techniques.
The IFCVN method represents a significant advancement in addressing the challenges of imbalanced datasets, which are commonly encountered in real-world machine learning applications. The authors' work lays the groundwork for further research and development in this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving SMOTE via Fusing Conditional VAE for Data-adaptive Noise Filtering
Sungchul Hong, Seunghwan An, Jong-June Jeon
Recent advances in a generative neural network model extend the development of data augmentation methods. However, the augmentation methods based on the modern generative models fail to achieve notable performance for class imbalance data compared to the conventional model, Synthetic Minority Oversampling Technique (SMOTE). We investigate the problem of the generative model for imbalanced classification and introduce a framework to enhance the SMOTE algorithm using Variational Autoencoders (VAE). Our approach systematically quantifies the density of data points in a low-dimensional latent space using the VAE, simultaneously incorporating information on class labels and classification difficulty. Then, the data points potentially degrading the augmentation are systematically excluded, and the neighboring observations are directly augmented on the data space. Empirical studies on several imbalanced datasets represent that this simple process innovatively improves the conventional SMOTE algorithm over the deep learning models. Consequently, we conclude that the selection of minority data and the interpolation in the data space are beneficial for imbalanced classification problems with a relatively small number of data points.
Read more8/27/2024
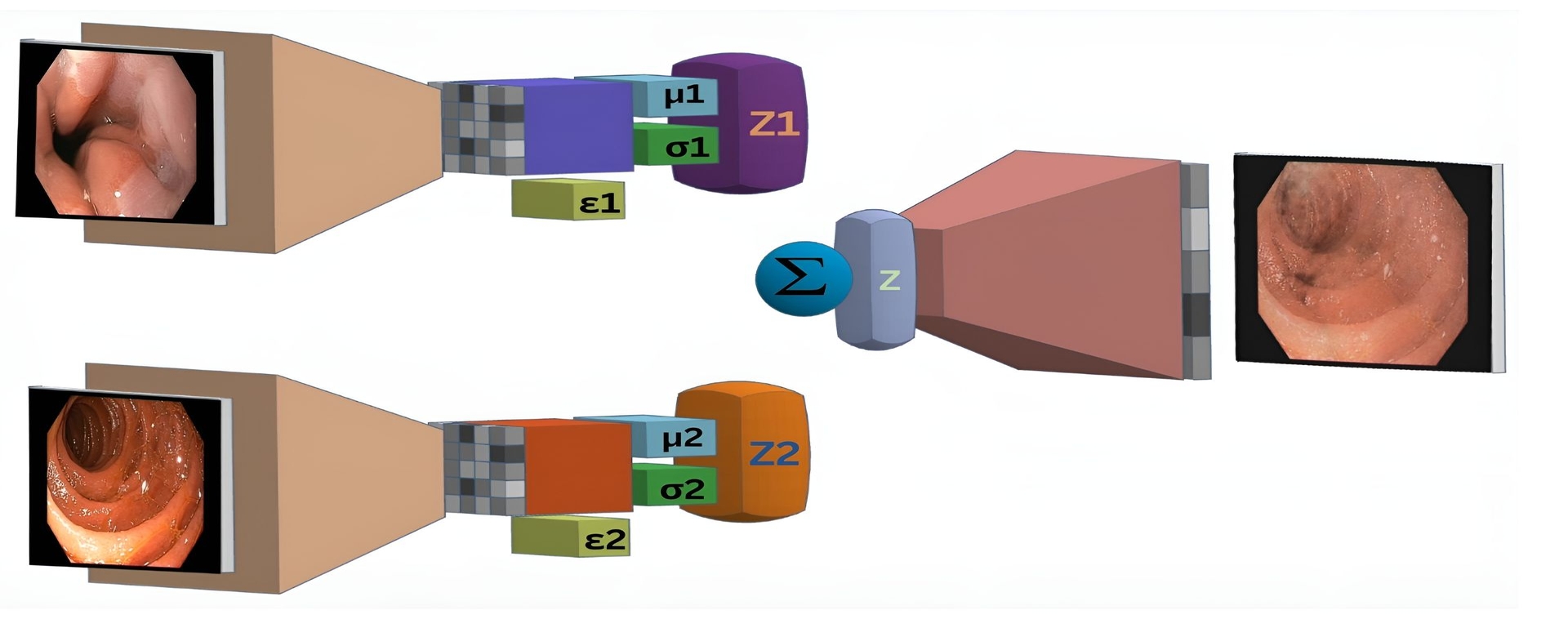
0
New!Enhancing Image Classification in Small and Unbalanced Datasets through Synthetic Data Augmentation
Neil De La Fuente, Mireia Maj'o, Irina Luzko, Henry C'ordova, Gloria Fern'andez-Esparrach, Jorge Bernal
Accurate and robust medical image classification is a challenging task, especially in application domains where available annotated datasets are small and present high imbalance between target classes. Considering that data acquisition is not always feasible, especially for underrepresented classes, our approach introduces a novel synthetic augmentation strategy using class-specific Variational Autoencoders (VAEs) and latent space interpolation to improve discrimination capabilities. By generating realistic, varied synthetic data that fills feature space gaps, we address issues of data scarcity and class imbalance. The method presented in this paper relies on the interpolation of latent representations within each class, thus enriching the training set and improving the model's generalizability and diagnostic accuracy. The proposed strategy was tested in a small dataset of 321 images created to train and validate an automatic method for assessing the quality of cleanliness of esophagogastroduodenoscopy images. By combining real and synthetic data, an increase of over 18% in the accuracy of the most challenging underrepresented class was observed. The proposed strategy not only benefited the underrepresented class but also led to a general improvement in other metrics, including a 6% increase in global accuracy and precision.
Read more9/17/2024

0
Robust VAEs via Generating Process of Noise Augmented Data
Hiroo Irobe, Wataru Aoki, Kimihiro Yamazaki, Yuhui Zhang, Takumi Nakagawa, Hiroki Waida, Yuichiro Wada, Takafumi Kanamori
Advancing defensive mechanisms against adversarial attacks in generative models is a critical research topic in machine learning. Our study focuses on a specific type of generative models - Variational Auto-Encoders (VAEs). Contrary to common beliefs and existing literature which suggest that noise injection towards training data can make models more robust, our preliminary experiments revealed that naive usage of noise augmentation technique did not substantially improve VAE robustness. In fact, it even degraded the quality of learned representations, making VAEs more susceptible to adversarial perturbations. This paper introduces a novel framework that enhances robustness by regularizing the latent space divergence between original and noise-augmented data. Through incorporating a paired probabilistic prior into the standard variational lower bound, our method significantly boosts defense against adversarial attacks. Our empirical evaluations demonstrate that this approach, termed Robust Augmented Variational Auto-ENcoder (RAVEN), yields superior performance in resisting adversarial inputs on widely-recognized benchmark datasets.
Read more7/29/2024

0
Improving Variational Autoencoder Estimation from Incomplete Data with Mixture Variational Families
Vaidotas Simkus, Michael U. Gutmann
We consider the task of estimating variational autoencoders (VAEs) when the training data is incomplete. We show that missing data increases the complexity of the model's posterior distribution over the latent variables compared to the fully-observed case. The increased complexity may adversely affect the fit of the model due to a mismatch between the variational and model posterior distributions. We introduce two strategies based on (i) finite variational-mixture and (ii) imputation-based variational-mixture distributions to address the increased posterior complexity. Through a comprehensive evaluation of the proposed approaches, we show that variational mixtures are effective at improving the accuracy of VAE estimation from incomplete data.
Read more6/28/2024