Enhancing IoT Intelligence: A Transformer-based Reinforcement Learning Methodology
2404.04205
0
0
Abstract
The proliferation of the Internet of Things (IoT) has led to an explosion of data generated by interconnected devices, presenting both opportunities and challenges for intelligent decision-making in complex environments. Traditional Reinforcement Learning (RL) approaches often struggle to fully harness this data due to their limited ability to process and interpret the intricate patterns and dependencies inherent in IoT applications. This paper introduces a novel framework that integrates transformer architectures with Proximal Policy Optimization (PPO) to address these challenges. By leveraging the self-attention mechanism of transformers, our approach enhances RL agents' capacity for understanding and acting within dynamic IoT environments, leading to improved decision-making processes. We demonstrate the effectiveness of our method across various IoT scenarios, from smart home automation to industrial control systems, showing marked improvements in decision-making efficiency and adaptability. Our contributions include a detailed exploration of the transformer's role in processing heterogeneous IoT data, a comprehensive evaluation of the framework's performance in diverse environments, and a benchmark against traditional RL methods. The results indicate significant advancements in enabling RL agents to navigate the complexities of IoT ecosystems, highlighting the potential of our approach to revolutionize intelligent automation and decision-making in the IoT landscape.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a transformer-based reinforcement learning (RL) methodology for enhancing intelligence in Internet of Things (IoT) systems.
- It combines the strengths of transformer models and proximal policy optimization (PPO), a popular RL algorithm, to address challenges in IoT environments.
- The goal is to improve decision-making and adaptability in IoT applications, such as smart homes, industrial automation, and environmental monitoring.
Plain English Explanation
The paper presents a new approach to making IoT systems more intelligent and adaptable. IoT systems are networks of connected devices, like smart home appliances or industrial sensors, that collect and exchange data. However, these systems can struggle to make complex decisions and adapt to changing conditions.
The researchers combined two powerful AI techniques to address this: transformer models and reinforcement learning. Transformer models are a type of deep learning model that excels at processing and understanding structured data, like the sensor readings from IoT devices. Reinforcement learning is a way for AI systems to learn by interacting with their environment and getting feedback on their actions.
By putting these two techniques together, the researchers created an AI system that can analyze sensor data from IoT devices, understand patterns and relationships, and then use that knowledge to make smart decisions and adaptations. This could help IoT systems become more autonomous and responsive, leading to benefits like better energy efficiency, more reliable operations, and safer environments.
Technical Explanation
The key elements of the proposed methodology are:
-
Transformer-based Encoder: The system uses a transformer-based encoder to process and extract meaningful features from the sensor data collected by IoT devices. Transformer models are well-suited for this task due to their ability to capture complex relationships and dependencies in structured data.
-
Proximal Policy Optimization (PPO): The researchers employ PPO, a state-of-the-art reinforcement learning algorithm, to enable the IoT system to learn optimal decision-making policies. PPO is known for its stability and sample efficiency, making it a good fit for resource-constrained IoT environments.
-
Reward Shaping: The paper describes a reward shaping mechanism that aligns the RL agent's objective with the desired outcomes for the IoT system, such as energy efficiency, reliability, or safety. This helps the agent learn policies that balance multiple competing goals.
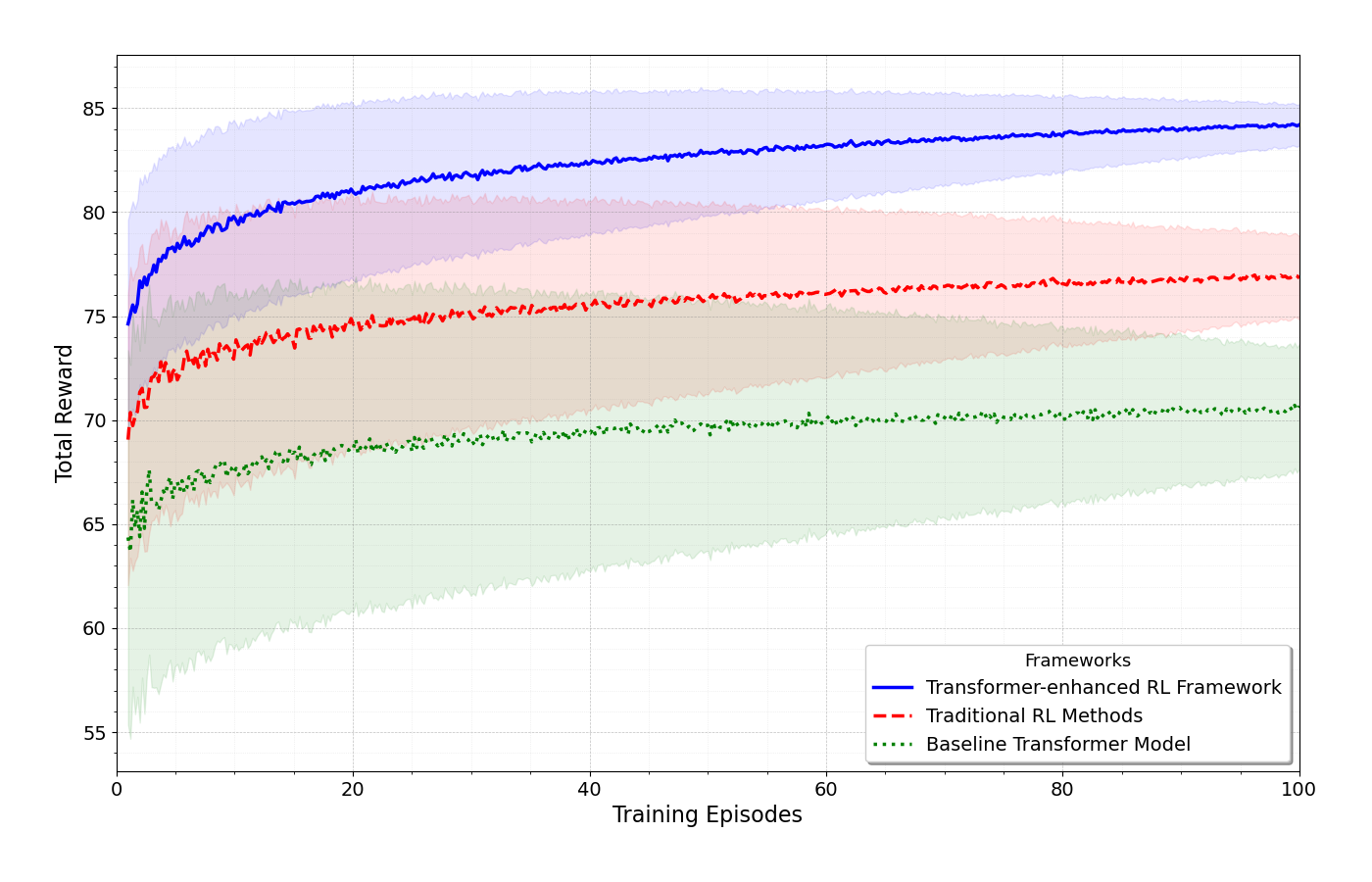
The researchers evaluated their approach using simulated IoT environments and demonstrated its superiority over baseline RL methods in terms of decision-making performance and sample efficiency.
Critical Analysis
The paper presents a promising approach for enhancing the intelligence and adaptability of IoT systems. However, some limitations and areas for further research are worth considering:
-
Real-world Validation: While the simulated experiments provide proof-of-concept, the authors acknowledge the need for validation in real-world IoT deployments to assess the practical impact and challenges of deploying such a system.
-
Scalability and Heterogeneity: The paper focuses on a single IoT environment, but real-world IoT systems often involve a large number of diverse devices and data sources. Addressing scalability and heterogeneity will be crucial for the widespread adoption of this methodology.
-
Interpretability and Explainability: As with many deep learning-based systems, the underlying decision-making process of the transformer-RL agent may be opaque. Incorporating interpretability and explainability mechanisms could help build trust and facilitate the integration of human expertise.
-
Security and Privacy: IoT systems handle sensitive data and operate in mission-critical environments. Addressing security and privacy concerns should be a key consideration in the further development of this methodology.
Conclusion
This paper presents a novel transformer-based reinforcement learning approach for enhancing the intelligence and adaptability of IoT systems. By combining the strengths of transformer models and proximal policy optimization, the proposed methodology can enable IoT devices to make more informed and responsive decisions, leading to potential benefits in areas like energy efficiency, reliability, and safety.
While the simulated results are promising, further research is needed to address real-world challenges, such as scalability, interpretability, and security. Nonetheless, this work represents an important step towards developing more autonomous and intelligent IoT systems that can better serve the needs of individuals, communities, and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Efficient Transformer-based Hyper-parameter Optimization for Resource-constrained IoT Environments
Ibrahim Shaer, Soodeh Nikan, Abdallah Shami
0
0
The hyper-parameter optimization (HPO) process is imperative for finding the best-performing Convolutional Neural Networks (CNNs). The automation process of HPO is characterized by its sizable computational footprint and its lack of transparency; both important factors in a resource-constrained Internet of Things (IoT) environment. In this paper, we address these problems by proposing a novel approach that combines transformer architecture and actor-critic Reinforcement Learning (RL) model, TRL-HPO, equipped with multi-headed attention that enables parallelization and progressive generation of layers. These assumptions are founded empirically by evaluating TRL-HPO on the MNIST dataset and comparing it with state-of-the-art approaches that build CNN models from scratch. The results show that TRL-HPO outperforms the classification results of these approaches by 6.8% within the same time frame, demonstrating the efficiency of TRL-HPO for the HPO process. The analysis of the results identifies the main culprit for performance degradation attributed to stacking fully connected layers. This paper identifies new avenues for improving RL-based HPO processes in resource-constrained environments.
5/3/2024
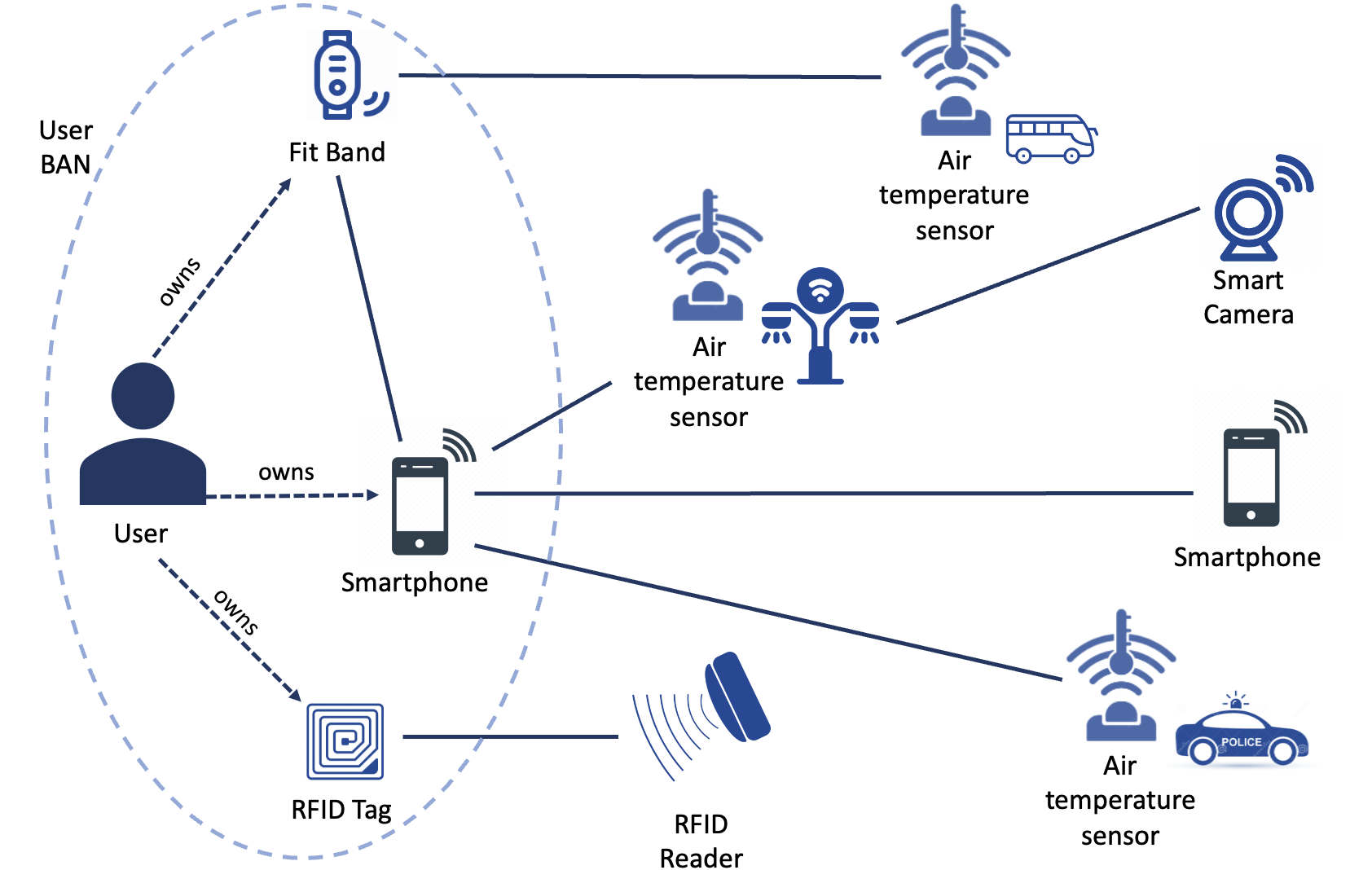
A Deep Reinforcement Learning Approach for Security-Aware Service Acquisition in IoT
Marco Arazzi, Serena Nicolazzo, Antonino Nocera
0
0
The novel Internet of Things (IoT) paradigm is composed of a growing number of heterogeneous smart objects and services that are transforming architectures and applications, increasing systems' complexity, and the need for reliability and autonomy. In this context, both smart objects and services are often provided by third parties which do not give full transparency regarding the security and privacy of the features offered. Although machine-based Service Level Agreements (SLA) have been recently leveraged to establish and share policies in Cloud-based scenarios, and also in the IoT context, the issue of making end users aware of the overall system security levels and the fulfillment of their privacy requirements through the provision of the requested service remains a challenging task. To tackle this problem, we propose a complete framework that defines suitable levels of privacy and security requirements in the acquisition of services in IoT, according to the user needs. Through the use of a Reinforcement Learning based solution, a user agent, inside the environment, is trained to choose the best smart objects granting access to the target services. Moreover, the solution is designed to guarantee deadline requirements and user security and privacy needs. Finally, to evaluate the correctness and the performance of the proposed approach we illustrate an extensive experimental analysis.
4/5/2024
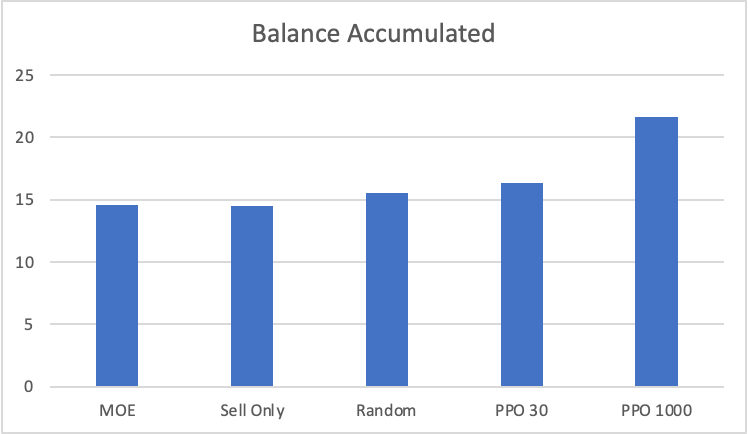
A proximal policy optimization based intelligent home solar management
Kode Creer, Imitiaz Parvez
0
0
In the smart grid, the prosumers can sell unused electricity back to the power grid, assuming the prosumers own renewable energy sources and storage units. The maximizing of their profits under a dynamic electricity market is a problem that requires intelligent planning. To address this, we propose a framework based on Proximal Policy Optimization (PPO) using recurrent rewards. By using the information about the rewards modeled effectively with PPO to maximize our objective, we were able to get over 30% improvement over the other naive algorithms in accumulating total profits. This shows promise in getting reinforcement learning algorithms to perform tasks required to plan their actions in complex domains like financial markets. We also introduce a novel method for embedding longs based on soliton waves that outperformed normal embedding in our use case with random floating point data augmentation.
5/10/2024
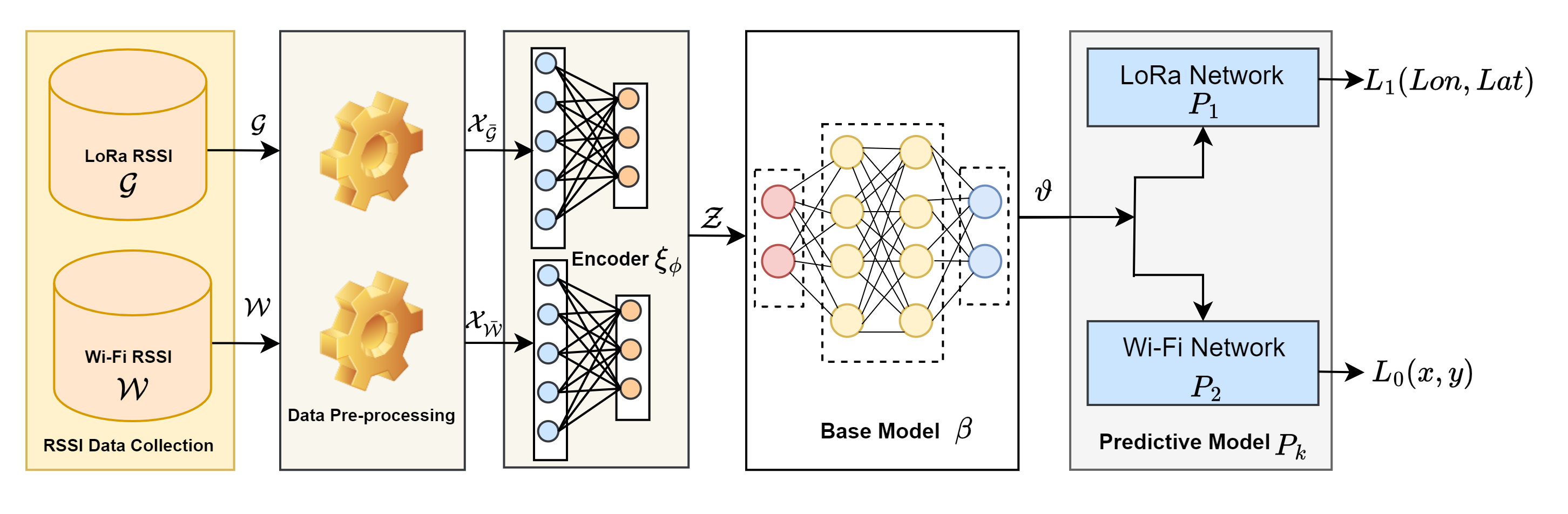
New!A Unified Deep Transfer Learning Model for Accurate IoT Localization in Diverse Environments
Abdullahi Isa Ahmed, Yaya Etiabi, Ali Waqar Azim, El Mehdi Amhoud
0
0
Internet of Things (IoT) is an ever-evolving technological paradigm that is reshaping industries and societies globally. Real-time data collection, analysis, and decision-making facilitated by localization solutions form the foundation for location-based services, enabling them to support critical functions within diverse IoT ecosystems. However, most existing works on localization focus on single environment, resulting in the development of multiple models to support multiple environments. In the context of smart cities, these raise costs and complexity due to the dynamicity of such environments. To address these challenges, this paper presents a unified indoor-outdoor localization solution that leverages transfer learning (TL) schemes to build a single deep learning model. The model accurately predicts the localization of IoT devices in diverse environments. The performance evaluation shows that by adopting an encoder-based TL scheme, we can improve the baseline model by about 17.18% in indoor environments and 9.79% in outdoor environments.
5/17/2024