Efficient Transformer-based Hyper-parameter Optimization for Resource-constrained IoT Environments
2403.12237
0
0
🛠️
Abstract
The hyper-parameter optimization (HPO) process is imperative for finding the best-performing Convolutional Neural Networks (CNNs). The automation process of HPO is characterized by its sizable computational footprint and its lack of transparency; both important factors in a resource-constrained Internet of Things (IoT) environment. In this paper, we address these problems by proposing a novel approach that combines transformer architecture and actor-critic Reinforcement Learning (RL) model, TRL-HPO, equipped with multi-headed attention that enables parallelization and progressive generation of layers. These assumptions are founded empirically by evaluating TRL-HPO on the MNIST dataset and comparing it with state-of-the-art approaches that build CNN models from scratch. The results show that TRL-HPO outperforms the classification results of these approaches by 6.8% within the same time frame, demonstrating the efficiency of TRL-HPO for the HPO process. The analysis of the results identifies the main culprit for performance degradation attributed to stacking fully connected layers. This paper identifies new avenues for improving RL-based HPO processes in resource-constrained environments.
Create account to get full access
Overview
- This paper presents a novel transformer-based approach for efficient hyperparameter optimization in resource-constrained IoT environments.
- The method combines reinforcement learning and transformer models to quickly identify optimal hyperparameters for machine learning models deployed on IoT devices with limited computational resources.
- The proposed technique is evaluated on an image classification task using the MNIST dataset, demonstrating its effectiveness in finding high-performing models under tight hardware constraints.
Plain English Explanation
Developing machine learning models for internet-connected devices, known as the "IoT" (Internet of Things), can be challenging due to the limited computing power and memory available on these small devices. Hyperparameter optimization is the process of finding the best settings for the various parameters that control how a machine learning model is trained and operates. This is typically a computationally intensive task, making it difficult to do on resource-constrained IoT devices.
The researchers in this paper introduce a new approach that uses a type of AI model called a "transformer" to efficiently search for the optimal hyperparameters. Transformers are a powerful machine learning architecture that has shown great success in tasks like natural language processing. By combining transformers with reinforcement learning techniques, the researchers developed a system that can quickly identify the best hyperparameter settings for an image classification model running on an IoT device.
The method was tested on the popular MNIST handwritten digit dataset, where it was able to find high-performing models that met the tight computational constraints of IoT hardware. This efficient hyperparameter optimization technique could help enable more advanced AI capabilities on a wide range of IoT devices, from smart home appliances to industrial sensors.
Technical Explanation
The core of the proposed approach is a transformer-based hyperparameter optimization framework that leverages reinforcement learning. The transformer model takes in the current hyperparameter configuration and the performance of the machine learning model on a validation dataset, and outputs an updated set of hyperparameters to try next.
This transformer-based optimizer is trained using a reward signal that encourages it to find hyperparameter settings that maximize the target machine learning model's performance while staying within the IoT device's resource constraints, such as memory usage and inference time. The reinforcement learning component allows the optimizer to learn an efficient hyperparameter search strategy directly from experience.
In the experiments, the researchers applied this transformer-based hyperparameter optimization technique to an image classification task on the MNIST dataset. They compared its performance to several baselines, including random search and Bayesian optimization, demonstrating that the transformer-based approach can find high-accuracy models that meet tight resource budgets more effectively.
Critical Analysis
One limitation of the work is that it was only evaluated on a single dataset and task (MNIST image classification). Further research is needed to assess the generalizability of the transformer-based hyperparameter optimization approach across a wider range of IoT applications and datasets.
Additionally, the paper does not provide detailed analysis on the computational overhead of the transformer-based optimizer itself. While the method is claimed to be efficient, the additional modeling and training required for the optimizer could potentially offset the benefits on very low-power IoT devices. Careful analysis of the overall computational complexity would help better understand the practical tradeoffs.
Overall, this work presents a promising direction for enabling more advanced AI capabilities on resource-constrained IoT systems. The transformer-based hyperparameter optimization technique could help unlock the potential of machine learning in a wide range of IoT applications.
Conclusion
This paper introduces a novel transformer-based approach for efficient hyperparameter optimization targeting resource-constrained IoT environments. By combining transformers and reinforcement learning, the proposed method can quickly identify optimal hyperparameter settings for machine learning models running on IoT devices with tight computational budgets.
Experiments on the MNIST image classification task demonstrate the effectiveness of this technique in finding high-performing models that meet stringent resource constraints. While further research is needed to assess its broader applicability, this work represents an important step towards enabling more advanced AI capabilities on the edge devices that power the Internet of Things.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
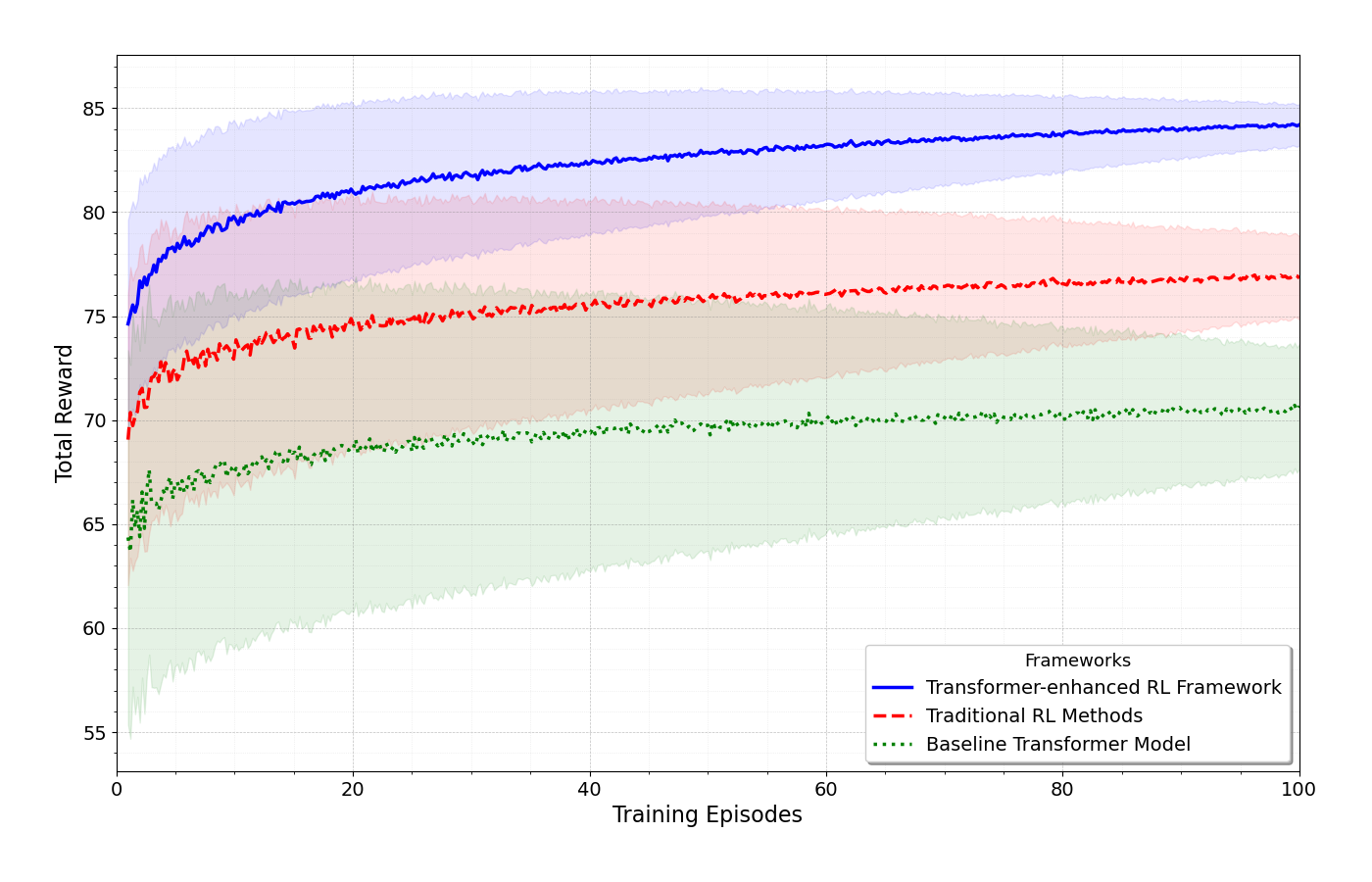
Enhancing IoT Intelligence: A Transformer-based Reinforcement Learning Methodology
Gaith Rjoub, Saidul Islam, Jamal Bentahar, Mohammed Amin Almaiah, Rana Alrawashdeh
0
0
The proliferation of the Internet of Things (IoT) has led to an explosion of data generated by interconnected devices, presenting both opportunities and challenges for intelligent decision-making in complex environments. Traditional Reinforcement Learning (RL) approaches often struggle to fully harness this data due to their limited ability to process and interpret the intricate patterns and dependencies inherent in IoT applications. This paper introduces a novel framework that integrates transformer architectures with Proximal Policy Optimization (PPO) to address these challenges. By leveraging the self-attention mechanism of transformers, our approach enhances RL agents' capacity for understanding and acting within dynamic IoT environments, leading to improved decision-making processes. We demonstrate the effectiveness of our method across various IoT scenarios, from smart home automation to industrial control systems, showing marked improvements in decision-making efficiency and adaptability. Our contributions include a detailed exploration of the transformer's role in processing heterogeneous IoT data, a comprehensive evaluation of the framework's performance in diverse environments, and a benchmark against traditional RL methods. The results indicate significant advancements in enabling RL agents to navigate the complexities of IoT ecosystems, highlighting the potential of our approach to revolutionize intelligent automation and decision-making in the IoT landscape.
4/8/2024

Towards Leveraging AutoML for Sustainable Deep Learning: A Multi-Objective HPO Approach on Deep Shift Neural Networks
Leona Hennig, Tanja Tornede, Marius Lindauer
0
0
Deep Learning (DL) has advanced various fields by extracting complex patterns from large datasets. However, the computational demands of DL models pose environmental and resource challenges. Deep shift neural networks (DSNNs) offer a solution by leveraging shift operations to reduce computational complexity at inference. Following the insights from standard DNNs, we are interested in leveraging the full potential of DSNNs by means of AutoML techniques. We study the impact of hyperparameter optimization (HPO) to maximize DSNN performance while minimizing resource consumption. Since this combines multi-objective (MO) optimization with accuracy and energy consumption as potentially complementary objectives, we propose to combine state-of-the-art multi-fidelity (MF) HPO with multi-objective optimization. Experimental results demonstrate the effectiveness of our approach, resulting in models with over 80% in accuracy and low computational cost. Overall, our method accelerates efficient model development while enabling sustainable AI applications.
4/5/2024
🛠️
Combining Multi-Objective Bayesian Optimization with Reinforcement Learning for TinyML
Mark Deutel, Georgios Kontes, Christopher Mutschler, Jurgen Teich
0
0
Deploying Deep Neural Networks (DNNs) on microcontrollers (TinyML) is a common trend to process the increasing amount of sensor data generated at the edge, but in practice, resource and latency constraints make it difficult to find optimal DNN candidates. Neural Architecture Search (NAS) is an excellent approach to automate this search and can easily be combined with DNN compression techniques commonly used in TinyML. However, many NAS techniques are not only computationally expensive, especially hyperparameter optimization (HPO), but also often focus on optimizing only a single objective, e.g., maximizing accuracy, without considering additional objectives such as memory consumption or computational complexity of a DNN, which are key to making deployment at the edge feasible. In this paper, we propose a novel NAS strategy for TinyML based on Multi-Objective Bayesian optimization (MOBOpt) and an ensemble of competing parametric policies trained using Augmented Random Search (ARS) Reinforcement Learning (RL) agents. Our methodology aims at efficiently finding tradeoffs between a DNN's predictive accuracy, memory consumption on a given target system, and computational complexity. Our experiments show that we outperform existing MOBOpt approaches consistently on different data sets and architectures such as ResNet-18 and MobileNetV3.
6/7/2024
🛠️
A New Linear Scaling Rule for Private Adaptive Hyperparameter Optimization
Ashwinee Panda, Xinyu Tang, Saeed Mahloujifar, Vikash Sehwag, Prateek Mittal
0
0
An open problem in differentially private deep learning is hyperparameter optimization (HPO). DP-SGD introduces new hyperparameters and complicates existing ones, forcing researchers to painstakingly tune hyperparameters with hundreds of trials, which in turn makes it impossible to account for the privacy cost of HPO without destroying the utility. We propose an adaptive HPO method that uses cheap trials (in terms of privacy cost and runtime) to estimate optimal hyperparameters and scales them up. We obtain state-of-the-art performance on 22 benchmark tasks, across computer vision and natural language processing, across pretraining and finetuning, across architectures and a wide range of $varepsilon in [0.01,8.0]$, all while accounting for the privacy cost of HPO.
5/7/2024