Imitation Game: A Model-based and Imitation Learning Deep Reinforcement Learning Hybrid
2404.01794
0
0
Abstract
Autonomous and learning systems based on Deep Reinforcement Learning have firmly established themselves as a foundation for approaches to creating resilient and efficient Cyber-Physical Energy Systems. However, most current approaches suffer from two distinct problems: Modern model-free algorithms such as Soft Actor Critic need a high number of samples to learn a meaningful policy, as well as a fallback to ward against concept drifts (e. g., catastrophic forgetting). In this paper, we present the work in progress towards a hybrid agent architecture that combines model-based Deep Reinforcement Learning with imitation learning to overcome both problems.
Create account to get full access
Overview
- This paper presents a novel deep reinforcement learning approach called "Imitation Game" that combines model-based and imitation learning techniques.
- The goal is to enable agents to learn complex behaviors by imitating expert demonstrations while also leveraging the strengths of model-based reinforcement learning.
- The authors conduct experiments in several benchmark environments to evaluate the performance of their Imitation Game approach compared to other deep reinforcement learning methods.
Plain English Explanation
The researchers developed a new kind of artificial intelligence (AI) system that can learn how to do complex tasks by watching an expert do it first, and then figuring out how to do it on its own. This is like a child watching their parents cook a meal, and then trying to cook the same meal themselves.
The key idea is to combine two different AI techniques: imitation learning and model-based reinforcement learning. Imitation learning allows the AI to learn by observing an expert, while model-based reinforcement learning helps the AI explore and discover new ways of doing the task on its own.
By using both of these approaches together, the researchers found that the AI system was able to learn complex behaviors more effectively than using either approach alone. The AI could observe an expert, learn from their demonstrations, and then build on that knowledge to find its own creative solutions to the task.
The researchers tested their Imitation Game approach in several different environments, like simulated video games or robotics tasks, and showed that it outperformed other state-of-the-art deep reinforcement learning methods. This suggests that combining imitation learning and model-based reinforcement learning could be a powerful way to build more capable and versatile AI systems.
Technical Explanation
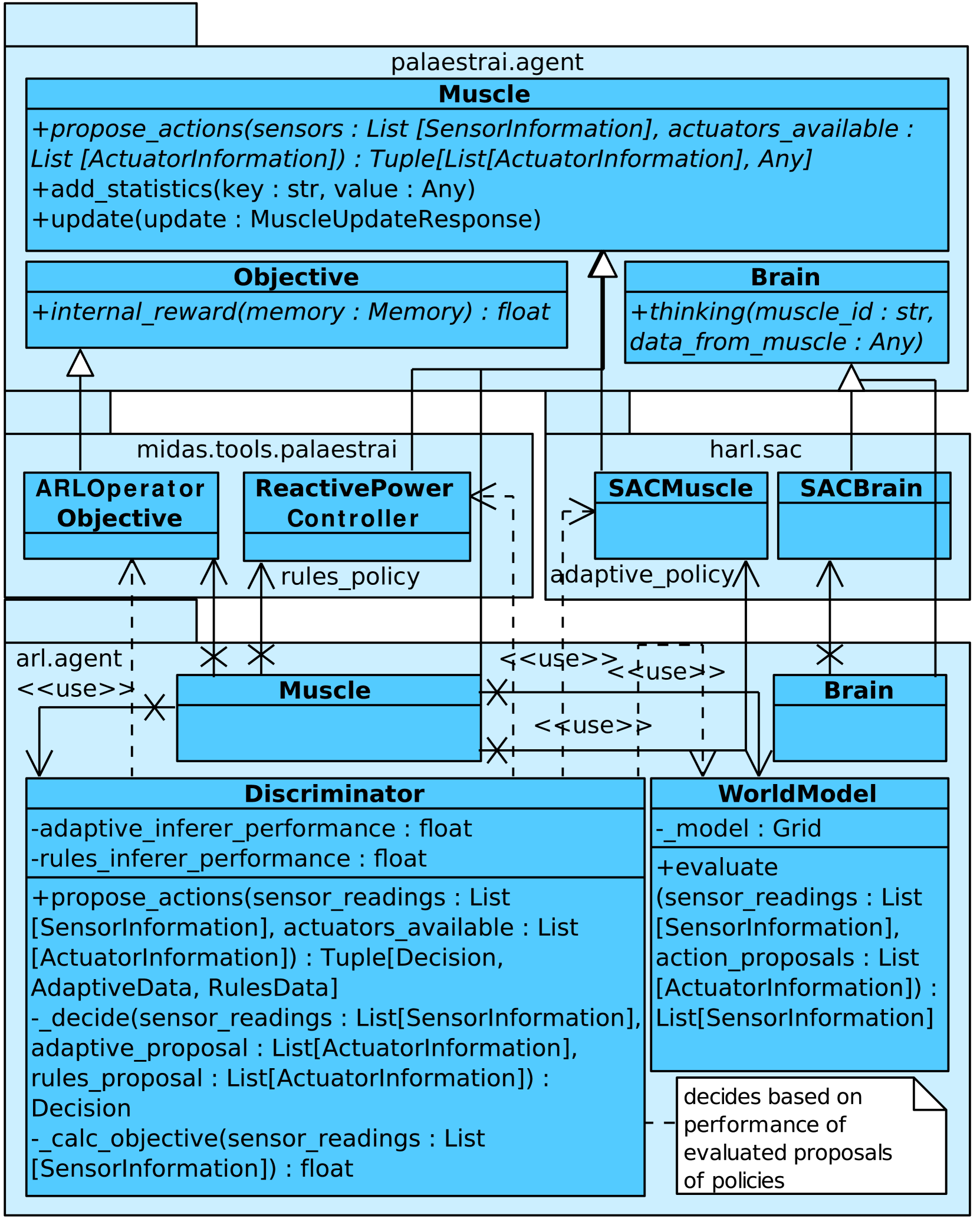
The key innovation of this paper is the "Imitation Game" framework, which integrates model-based reinforcement learning (MBRL) and imitation learning (IL) techniques. The model-based component allows the agent to learn a dynamics model of the environment, which it can then use to plan and explore effectively. The imitation learning component allows the agent to observe and learn from expert demonstrations of the task.
The authors propose an MBRL agent that is trained to both match the expert's actions (via behavioral cloning) and maximize the environment's reward signal (via policy optimization). This dual objective encourages the agent to not only mimic the expert, but also explore and discover its own solutions that may outperform the expert.
Experiments are conducted in several benchmark environments, including classic control tasks, continuous control tasks, and a complex 3D navigation task. The results show that the Imitation Game approach significantly outperforms both standard MBRL and IL baselines, demonstrating the benefits of combining these two complementary learning paradigms.
The authors also analyze the learned dynamics models and policies, providing insights into how the Imitation Game agent is able to leverage model-based reasoning and imitation to solve these tasks more effectively.
Critical Analysis
The Imitation Game framework presented in this paper is a promising approach that combines the strengths of model-based reinforcement learning and imitation learning. By enabling the agent to both observe an expert and explore the environment autonomously, the authors show that it can learn more effective policies than either technique alone.
One potential limitation is that the approach relies on access to expert demonstrations, which may not always be available in real-world scenarios. The authors acknowledge this and suggest that their framework could potentially be extended to handle more limited or noisy expert data.
Additionally, the paper focuses on relatively simple benchmark tasks, and it would be valuable to see how the Imitation Game approach scales to more complex, real-world problems. Evaluating its sample efficiency, robustness, and ability to generalize to novel situations would also be important next steps.
Overall, this work makes a valuable contribution by demonstrating the potential of integrating model-based reasoning and imitation learning for complex control tasks. Further research exploring the broader applicability and limitations of this hybrid approach could yield important insights for the field of deep reinforcement learning.
Conclusion
The Imitation Game framework presented in this paper offers a promising new approach to deep reinforcement learning that combines the strengths of model-based reasoning and imitation learning. By enabling agents to both observe expert demonstrations and autonomously explore their environments, the authors show that this hybrid technique can outperform standard reinforcement learning and imitation learning methods on a variety of benchmark tasks.
While the current results are promising, further research is needed to understand the broader applicability and limitations of the Imitation Game approach, particularly when scaling to more complex, real-world problems. Exploring ways to handle more limited or noisy expert data, as well as evaluating the approach's sample efficiency and generalization capabilities, could lead to important advancements in the field of deep reinforcement learning.
Overall, this work represents an important step forward in developing more capable and versatile AI systems that can learn complex behaviors through a combination of observation, imitation, and autonomous exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Hybrid Inverse Reinforcement Learning
Juntao Ren, Gokul Swamy, Zhiwei Steven Wu, J. Andrew Bagnell, Sanjiban Choudhury
0
0
The inverse reinforcement learning approach to imitation learning is a double-edged sword. On the one hand, it can enable learning from a smaller number of expert demonstrations with more robustness to error compounding than behavioral cloning approaches. On the other hand, it requires that the learner repeatedly solve a computationally expensive reinforcement learning (RL) problem. Often, much of this computation is wasted searching over policies very dissimilar to the expert's. In this work, we propose using hybrid RL -- training on a mixture of online and expert data -- to curtail unnecessary exploration. Intuitively, the expert data focuses the learner on good states during training, which reduces the amount of exploration required to compute a strong policy. Notably, such an approach doesn't need the ability to reset the learner to arbitrary states in the environment, a requirement of prior work in efficient inverse RL. More formally, we derive a reduction from inverse RL to expert-competitive RL (rather than globally optimal RL) that allows us to dramatically reduce interaction during the inner policy search loop while maintaining the benefits of the IRL approach. This allows us to derive both model-free and model-based hybrid inverse RL algorithms with strong policy performance guarantees. Empirically, we find that our approaches are significantly more sample efficient than standard inverse RL and several other baselines on a suite of continuous control tasks.
6/6/2024

Deep Dive into Model-free Reinforcement Learning for Biological and Robotic Systems: Theory and Practice
Yusheng Jiao, Feng Ling, Sina Heydari, Nicolas Heess, Josh Merel, Eva Kanso
0
0
Animals and robots exist in a physical world and must coordinate their bodies to achieve behavioral objectives. With recent developments in deep reinforcement learning, it is now possible for scientists and engineers to obtain sensorimotor strategies (policies) for specific tasks using physically simulated bodies and environments. However, the utility of these methods goes beyond the constraints of a specific task; they offer an exciting framework for understanding the organization of an animal sensorimotor system in connection to its morphology and physical interaction with the environment, as well as for deriving general design rules for sensing and actuation in robotic systems. Algorithms and code implementing both learning agents and environments are increasingly available, but the basic assumptions and choices that go into the formulation of an embodied feedback control problem using deep reinforcement learning may not be immediately apparent. Here, we present a concise exposition of the mathematical and algorithmic aspects of model-free reinforcement learning, specifically through the use of textit{actor-critic} methods, as a tool for investigating the feedback control underlying animal and robotic behavior.
5/21/2024
🏅
Model-Based Reinforcement Learning for Atari
Lukasz Kaiser, Mohammad Babaeizadeh, Piotr Milos, Blazej Osinski, Roy H Campbell, Konrad Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozakowski, Sergey Levine, Afroz Mohiuddin, Ryan Sepassi, George Tucker, Henryk Michalewski
0
0
Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games in low data regime of 100k interactions between the agent and the environment, which corresponds to two hours of real-time play. In most games SimPLe outperforms state-of-the-art model-free algorithms, in some games by over an order of magnitude.
4/4/2024
Imitating Cost-Constrained Behaviors in Reinforcement Learning
Qian Shao, Pradeep Varakantham, Shih-Fen Cheng
0
0
Complex planning and scheduling problems have long been solved using various optimization or heuristic approaches. In recent years, imitation learning that aims to learn from expert demonstrations has been proposed as a viable alternative to solving these problems. Generally speaking, imitation learning is designed to learn either the reward (or preference) model or directly the behavioral policy by observing the behavior of an expert. Existing work in imitation learning and inverse reinforcement learning has focused on imitation primarily in unconstrained settings (e.g., no limit on fuel consumed by the vehicle). However, in many real-world domains, the behavior of an expert is governed not only by reward (or preference) but also by constraints. For instance, decisions on self-driving delivery vehicles are dependent not only on the route preferences/rewards (depending on past demand data) but also on the fuel in the vehicle and the time available. In such problems, imitation learning is challenging as decisions are not only dictated by the reward model but are also dependent on a cost-constrained model. In this paper, we provide multiple methods that match expert distributions in the presence of trajectory cost constraints through (a) Lagrangian-based method; (b) Meta-gradients to find a good trade-off between expected return and minimizing constraint violation; and (c) Cost-violation-based alternating gradient. We empirically show that leading imitation learning approaches imitate cost-constrained behaviors poorly and our meta-gradient-based approach achieves the best performance.
5/24/2024